
[딥러닝] RNN/LSTM/GRU 비교(개념/수식)
RNN/LSTM/GRU
1. RNN
1) RNN의 개요
- Recurrent Neural Net은 sequential data 처리에 적합한 모델
- 순서도 데이터의 일부
- speech, text, image의 특징은 데이터 나타날 위치가 중요한 경우임
2) RNN 입출력 구조
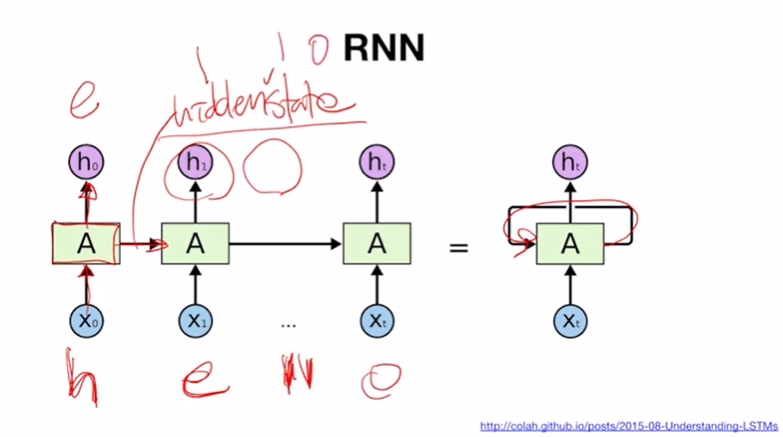
- Input: hello
- 첫번째 입력값이 셀 A에서 처리되고 하나는 h0로 출력이 되고 다른 하나는 출력되지 않고 다음 셀로 전달됨(=hidden state) → 이 전의 입력값의 처리결과를 반영하여 데이터의 순서를 이해하게 됨 → h가 들어가면 답이 e
- RNN은 모든 셀이 파라미터를 공유하므로 그림의 A가 하나이며, 긴 sequence가 들어와도 이를 처리하기 위한 셀은 A 하나임
- 입력되는 단어가 짧은 hello 든 더 길든 → 셀 A에 들어가는 파라미터만 알고 있으면 다음 단어를 예측하는 모델을 정상적으로 작동함
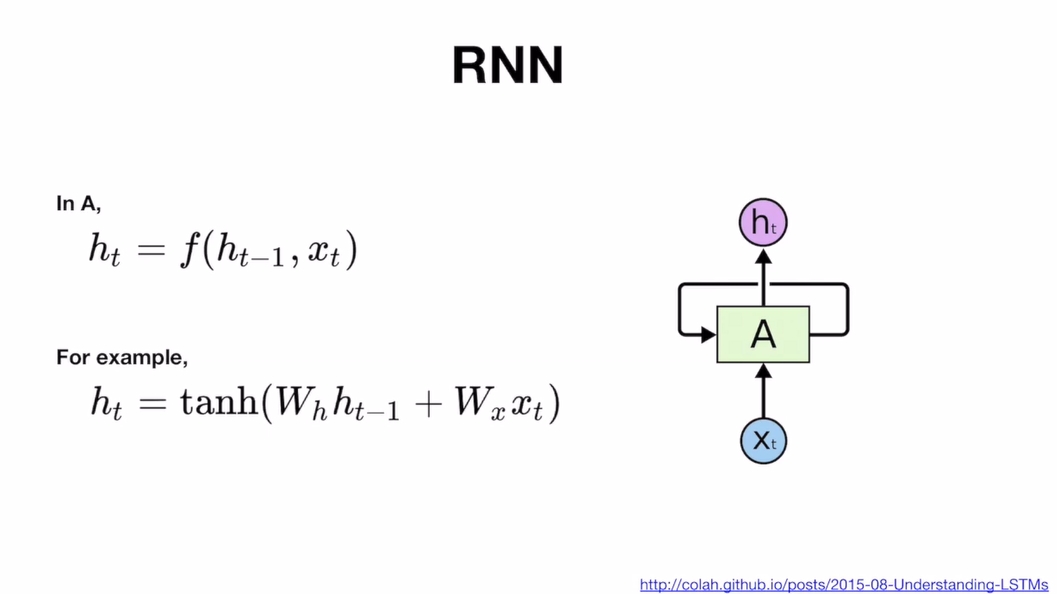
3) RNN 수식
- 수식을 살펴보면 셀 A에서 함수연산 일어나는데 전단계의 hidden state(h(t-1))에 매트릭스 W(h) 곱하고와 지금 단계의 입력값인 x(t)에 W(x) 곱해서 함수 연산을 통해 h(t)를 출력함
- 이러한 A라는 함수에 대한 설계는 다양한데 유명하고 일반적인게 LSTM, GRU
- 셀A의 파라미터는 학습의 대상이기 때문에 구조가 복잡해질 수록 셀 학습이 학습되는 정도는 줄어듦 →복잡도는 LSTM > GRU > RNN
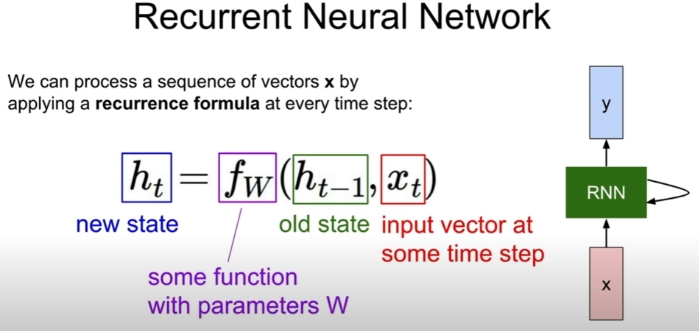

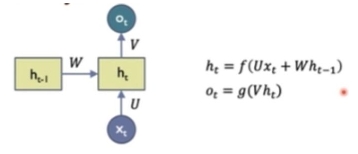
- RNN 수식 구성요소
1) x(t): input at time t
2) h(t): hidden state at time t
3) f: activation fuction
4) W(h), W(xh), W(hy) = U,V,W: network parameters
-
RNN은 모든 time steps에서 같은 parameter를 share함
-
U: x에서 h로 연결되는 connection weight
-
V: h(t) →O(t)로 연결되는 weight
-
W: h(t-1) → h(t) 연결되는 weight, fully connect라 2차원
1) g: activation fuction for the output layer
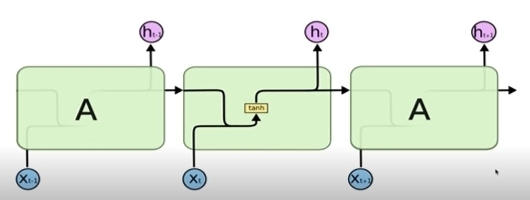
- 스탠다드 RNN
- Input: 직전 계산한 h와 현재 x
- 새로운 입력(x(t-1))이 들어오면 이전 값을 0으로 초기화해서 같이 넣어서 네트워크 A로 들어가게 함 -> 이 둘을 합쳐서 output (h(t-1))을 만들고 이걸 다시 다음 input으로 넣음
- 이전 정보와 현재 정보를 취합(concat)한 걸로 뉴럴넷에 들어가서 output이 됨
4) 가능한 RNN Tasks
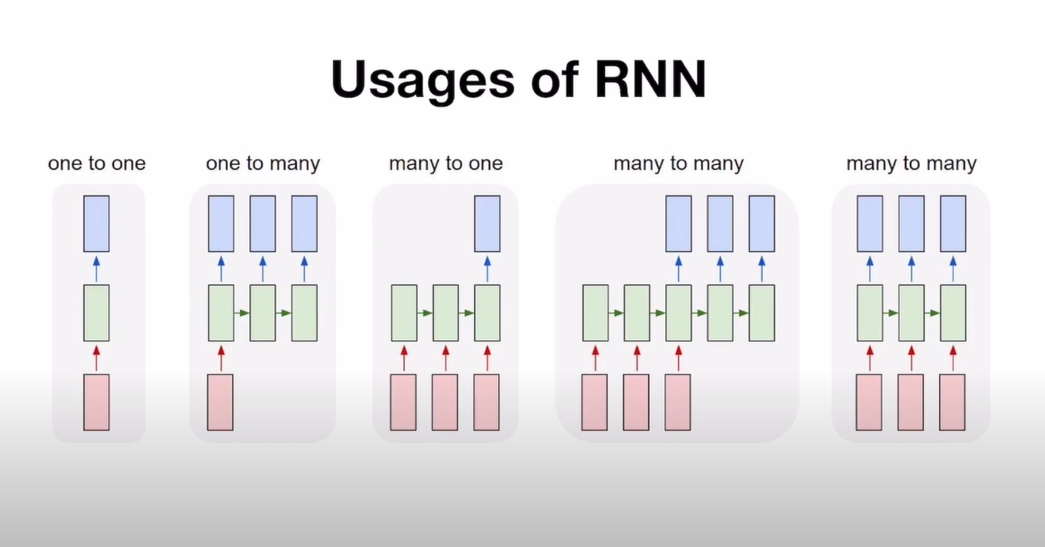
- RNN에 데이터 어떻게 넣어주고 출력값중 무엇을 취하느냐에 따라 다양한 task에 적용이 가능함
1) one to one: 일반적인 RNN
2) one to many: 하나의 입력에 여러개 출력 → 이미지하나 들어가고 문장이 출력(자막)
3) many to one : 문장이 입력되고 감성분석
4) many to many 1): 문장 들어가고 문장 출력, 문장 다 쓰고 다음 문장이 시작 → 번역
5) many to many 2) 싱크가 맞는 하나 입력에 하나 출력 매핑 → ex) 오늘 주가로 내일 주가 예측, I go to 다음 word 예측
many to many 1)과 2)가 다른 건 출력 지점이 다름 1)은 출력값이 있는데 안씀
RNN은 기본적으로 1 또는 5번째 many to many 2/synched many to many 구조임
sequence가 들어가서 sequence가 나오는 것
입력 하나 출력 하나, 입력도 많고 출력도 많음
싱크가 맞음→ RNN LSTM GRU 기본처리 모델은 synched many to many
RNN LSTM GRU는 4번 구조로 진행되어야 하는데 2)3)4) 모두 5)로 변환해서 처리해야함
5) RNN의 한계점
- RNN은 오늘 종가로 내일 종가를 계산한다고 할 때 바로 직전만 쓰는게 아니라 전전, 전전전꺼가 필요한 것 과거가 계속 영향을 줌, 과거를 기억하는 뉴럴 네트워크임 → 과거와 현재 정보를 활용해서 예측하는 것
- x1이 5번을 거친다고 할 때 w가 4번 곱해져야 함, w가 1보다 작아지면 exponential decay가 됨
- 또는 w가 너무 크면 exponential explosion이 일어남
- gradient vanishing과 explosion에 취약한 구조로 인해 long term 잘 되지 않음(10 수준)
- 즉, RNN은 아주 긴 문장을 입력할 때 기울기가 너무 커지거나 작아져 학습이 잘 되지 않음
- 짧은 시퀀스 데이터에 대해서만 효과를 보임
- RNN의 문제를 해결하기 위해서 LSTM을 사용함. LSTM은 long term dependency을 잡아내고 1천 스텝 정도 가능함
RNN의 한계점을 다시 정리하면
1) exploding/vanishing gradient 발생
→ 이러한 문제점으로 RNN은 학습이 어려울 수 있음
2) RNN 구조에는 state x(t)에는 Wxx가 계속 곱해지게 된다.
(1) 곱해지는 값이 1보다 크면 → 무한대로 발산 (exploding gradient)
-
gradient 계산할 떄 NaN 또는 Inf가 생기는 경우 학습 진행이 더 이상 불가
-
해결방법으로 gradient clipping이 있음, graident의 상하한을 정해두는 것
-
위의 방법을 쓸 수 있으나 근본적인 해결책이 되지 않음
(2) 곱해지는 값이 1보다 작다면 → 0으로 수렴 (vanishing gradient)
-
gradient가 계속 0이 되어 업데이트가 되지 않음
-
vanishing gradient는 학습 도중 파악 자체가 불가능함
-
gradient가 0이 되는 경우 1> 학습이 종료된 것인지 2> vanishing 현상이 일어났는지 알 수 없음
-
다른 네트워크 구조를 제안 → Gated RNNs
Gated RNNs
-
여기서 Gates는 수도꼭지 개념으로 gradient를 얼마나 열고 닫고를 할 것인지 , Input 정보와 State정보를 얼마나 열고 닫을 건지를 결정할 수 있는 것
-
LSTM & GRU
-
RNN은 이전에서 온 정보(메모리) + 현재 입력 같이 고려를 하는데 바로 직전이 아니라 그 전 데이터도 필요함
단순히 이전 문장만 고려하는 게 아니라 한참 이전에 있는 문장도 고려해야함 -> 현재 내용을 올바르게 유추하기 위해
- longer term dependencies를 고려해야 함 -> 이로 인해 LSTM이 나옴
2. LSTM
1) LTSM의 개요
-
1997년 제안되었으며, 장기의존성 문제를 해결하고 빠른 학습 속도의 장점이 있음
-
LSTM은 과거에서 온 정보 C(cell state)가 하나가 더 있음
-
cell state는 기존의 상태를 보존하여 전달함
-
long term dependency와 short term까지 2가지 모두 잡는 구조
-
또한, Gate 구조가 추가 되는데 Gradient flow를 제어할 수 있는 ‘수도꼭지’ 역할을 함
-
h(t-1)은 지방도로 C(t-1)은 고속도로라고 비유
1) h(t-1): short term state
-
지방도로로 모든 도시 거치면서 다양한 정보를 가지는데 잃어버리기도 함
-
다양한 정보가 있긴한데 먼 과거의 기록이 있진 않음
-
출력값 g(t)
2) c(t-1): long term state
-
먼 과거 기록이 있음
-
이 부분은 데이터를 전달하는 역할을 하는데 해당 경로에 곱셈이 없음
-
과거 정보가 더하기만 일어나서 exponenital decay, explosion 없음
-
이 Ct가 하이퍼 tanh 통과된 애를 ht라고 함
3) g(t)와 c(t-1) 비율 조정을 위한 gate 필요성
-
과거 정보 c(t-1)와 과거랑 현재 섞인 g(t) 둘을 1:1로 섞는게 맞을까? → 조정할 필요 있음
-
이에 대한 수도꼭지 역할로 gate가 존재함
-
f(t)는 과거 정보에 대한 수도꼭지
-
i(t)는 현재 정보에 대한 수도꼭지
기존 RNN

LSTM

2) LSTM 구조

1) 노랑색 박스: 뉴럴 넷 레이어
2) 동그라미: point wise operation: 12개에 12개면 각각을 12 dimension 만큼 곱해서 더하는 것

(1) 초록 부분
이전 정보가 100 dim이고 input이 100 dim이면 concat하면 200 dim이 됨
(2) 주황 부분:
200 dim에서 100dim으로 가는 network가 됨
3) LSTM 구성

1) Input X(t):
- t번째 시간의 단어가 들어감
2) Cell state:
- Internal memory
- Cell State: 이전의 Hidden state와 함께 다음 레이어로 기존의 상태를 보존하여 전달
-
거치는 부분이 거의 없으므로 backpropagation 할 때도 과거로 잘 전달됨

- 시그마 -> x는 정보를 여닫는 Gate 역할을 함
3) Hidden state:
- 이전 출력(output)
4) Forget Gate, Input Gate, Output Gate
- Gate가 총 3가지로 있고, 이 3개의 조합으로 Long term & Short term을 둘 다 잘 고려함
- Core는 Cell state: 일종의 컨베이어 벨트 같은 것으로 지금까지의 정보를 잘 취합해서 cell state로 잘 흘러감
4) 수식 구성요소
1) W(f): weight of layer in forget gate
2) b(f): bias of layer in forget gate
3) W(xf): 입력 벡터 x(t)에 연결된 레이어에 대한 weight matrix
4) W(hf): t-1 시점의 hidden state인 h(t-1)에 연결된 레이어에 대한 weight matrix
5) W(c): weight of layer in input gate
6) b(g), b(c): bias of layer input gate
7) W(xg): 입력 벡터 x(t)에 연결된 레이어에 대한 weight matrix
8) W(hg): t-1 시점의 hidden state(h(t-1))에 연결된 레이어에 대한 weight matrix
5) Gate 별 역할
(1) Foget Gate: f(t)
- 새로운 입력과 이전 상태를 참조해서 이 정보를 얼마의 비율로 잊어버릴 것인가=사용할 것인가를 결정
- Decide what information we’re going to throw away from the cell state
- 과거의 정보를 얼만큼 버릴지, 가져와야할지를 결정
-
gate controller로, simoide를 통해 0~1사이의 값을 받게 되는데 0에 가까울 수록 이전 cell state 값이 0에 가까워지고 많은 정보를 잊어버림



1) Forget Gate의 입력:
- 이전 output(h(t-1))과 현재 입력(x(t))
2) Forget Gate의 출력:
-
cell state로 넘어가는 어떤 값, sigmoid로 인해 범위는 0~1 값
-
Forget Gate의 출력f(t)의 dim이 100 dim(주황)이고, 이전 cell state (c(t))값인 100 dim(초록)을 곱함
3) Forget Gate의 역할
-
forget gate가 1이면 이전 cell state가 1로 다 넘어옴
-
cell state의 어떤 값을 버릴지를 결정하는 것
(2) Input Gate: i(t)
-
새로운 입력과 이전 상태를 참조해서 이 정보들을 얼마나 활용할 것인가를 결정
-
Decide what new information we’re going to store in the cell state
-
현재 정보를 얼마나 저장해야할지 버릴지를 결정
-
Input Gate로부터 새로운 기억 일부를 추가하는 과정
1> i(t)
-
신규 입력 데이터에 대해 얼마나 버릴지 결정하는 값
-
gate controller로 sigmoid로 0~1 사이의 값을 가짐
-
값이 0에 가까울수록 신규 input data가 0에 가까워짐
2> C(t) 틸다
-
g(t)라고도 표현되며, tanh로 -1~1 사이의 값을 가짐
-
1에 가까울수록 현재 정보를 최대한 많이 cell state에 더하자는 의미
1) C(t) 틸다 입력:
- 이전 output(h(t-1))과 현재 입력(x(t))의 네트워크.
2) C(t) 틸다 출력:
-
tanh(-1~1)
-
현재 cell state의 candidate


3> Input Gate의 출력:
- C(t) 출력값과 i(t) 출력값에 대한 element wise product가 일어나는데,
지금 가지고 있는 cell state에 c(t)틸다 값을 얼마나 반영해줄지를 결정함
5) Forget Gate와 Input Gate의 역할:
- Forget과 Input Gate 모두
(이전 Cell state 값을 얼마나 버릴지)와
(현재 입력과 이전 출력으로 얻어지는 cell state candidate인 c(t) 틸다 값을 cell state 값에 얼마나 올리고 반영할지)를 결정함
이 둘의 주체는 cell state임
(3) Update(Cell state)
-
Forget Gate와 Input Gate → 얼마나 잊을지, 얼마나 이용할지 → 이 둘을 적절히 섞음
-
Update, scaled by how much we decide to update
-
Forget Gate로 이전 cell state를 얼마나 버릴지와, Input Gate로 현재 cell state를 얼마나 업데이트 할지를 정해졌으니 그 후 그 둘을 더해주는 부분임


-
input_gatecurr_state + forget_gateprev_state
-
과거의 cell state를 새로운 state로 업데이트하는 과정
-
과거 정보를 위한 f(t) & 현재 정보를 위한 i(t)와 C(t)를 구한 후 이들을 element wise product 진행
-
f(t)*C(t-1): 이전 시점의 cell state를 얼마나 유지할지 계산
-
i(t)*C(t) 틸다: 현재 기억할 정보
-
최종적으로 서로 더해 Update
(4) Output Gate
-
일련의 정보를 모두 종합하여 다음 상태를 결정
-
Input & Forget Gate로 나온 정보가 Cell state이고 Input & Forget & Cell 3개를 가지고 만든 정보를 합쳐서 Output Gate로 넘김

- 최종적으로 얻어진 cell state의 값을 어떻게 밖으로 빼낼지를 결정함


-
O(t): 현재 cell state의 얼마만큼을 h(t)로 내보낼지 결정하는 역할
-
hidden state: 현 시점의 cell state와 함께 계산되어 출력됨과 동시에 다음 state로 넘겨짐
결론: 이 모든 것의 목적은 현재 입력과 이전 출력을 가지고 cell state에 어떻게 값을 집어넣고
이 cell state에 있는 값을 어떻게 빼줄지임

- 전체적인 과정을 정리하자면 아래와 같음

input(x(t))와 cell state와 hidden state가 들어가고 -> input gate, forget gate, output gate를 통과하여
→ cell state를 얼마나 업데이트하고 밖으로 빼낼지를 결정해주고 -> output이 나오면 다음 cell state와 hidden state로 넘겨줌
- tf와 pytorch에서의 코드 상에서는 4개의 뉴럴넷을 다 고려할 필요가 없고, 입력과 출력을 정해주고 초기 cell state만 잘 초기화 시켜주면 tf나 pytorch에서 알아서 진행됨
3. GRU
1) GRU 개요
-
GRU는 2014년에 제안되었고, 기존 LSTM의 복잡하고 많은 연산을 개선한 간소한 버전임
-
GRU의 경우, Gate가 4개에서 2개로 축소됨
1) LSTM의 Forget Gate + Input Gate ⇒ Update Gate로 병합
2) Cell State + Hidden State를 병합
2) GRU 구조

1) LSTM의 c(t) cell state와 h(t) hidden state가 h(t)로 합쳐짐
2) Reset Gate: r(t)

-
이전 상태/정보 h(t-1)에서 얼만큼을 선택해서 내보낼지 제어함
-
새로운 입력 정보를 이전 메모리와 어떻게 합칠지 결정함
-
LSTM과 달리 Output Gate가 없어서 h(t)가 타임 스텝마다 출력됨
-
직전 시점의 hidden state인 h(t-1)과 현재의 입력정보인 x(t)에 대해 sigmoid를 적용하여 산출함
3) Update Gate: z(t)

-
LSTM의 Forget Gate와 Input Gate를 병합하여, 과거 & 현재 정보를 얼마나 반영할지 구하는 단계
-
z(t)가 이전 정보의 비율을 결정, (1-z(t))가 현재 정보의 비율을 결정함 → 전자가 Forget Gate, 후자가 Input Gate의 역할을 함
-
z(t)가 1이면 Forget Gate가 열리며, 0이면 Input Gate가 열림

- h(t) 틸다는 reset gate를 사용하여 만들어짐

-
z(t)는 현재 입력 정보인 x(t)를 얼마나 반영할지를 결정하고
-
z(t)가 이전 정보의 비율을 결정, (1-z(t))가 현재 정보의 비율을 결정하여 최종 hidden state(출력값)인 h(t)를 구함
-
(t-1)의 기억이 저장될 때마다 t의 입력은 삭제됨
4) Hidden state
- Reset Gate, Update Gate를 모두 적용하여 Hidden State를 계산함

(1) 이전 정보인 h(t-1)에 reset gate인 r(t)를 곱하여 이전 정보 중 출력(h(t))로 내보낼 정보를 추려냄
(2) 위의 결과에 tanh을 적용하여 -1~1 값으로 만듦
(3) Update Gate인 z(t)는 (2)의 결과인 h(t) 틸다에 곱하여 현재 정보 중 내보낼 정보를 계산하며 , (1-z(t))는 이전 정보인 h(t-1)에 곱하여 이전 정보 중 내보낼 값을 고른다.
(4) (3)의 결과 2가지를 더하여 최종으로 output을 계산하는데 이것은 hidden state 값이 된다.
3) LSTM과 GRU 대응
LSTM

GRU


4) GRU 수식
1) Gate는 z(t)와 r(t)로 2개로 구성
-
z(t): Forget & Input Gate 역할
-
r(t): h(t-1) 제어하는 역할
4. RNN/LSTM/GRU 정리
1. RNN
-
sequence data를 다루기 위해 처음 제안된 모델
-
장기 의존성 문제 존재: Gradient Vanishing/Exploding
2.LSTM
-
장기의존성문제에 대한 해결과 빠른 학습 속도
-
계산량이 많음
3. GRU
-
LSTM 게이트 수를 줄여 간결한 구조
-
LSTM의 Forget Gate & Input Gate → Update Gate
-
Cell state + Hidden state 병합
References
RNN
https://www.youtube.com/watch?v=rbk9XFaoCEE
모두의 딥러닝 Lab-11-0 RNN intro
https://www.youtube.com/watch?v=6niqTuYFZLQ&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=11
LSTM
https://yjs-program.tistory.com/165
https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://cs231n.stanford.edu/schedule.html
GRU
https://www.youtube.com/watch?v=pYRIOGTPRPU
https://velog.io/@lighthouse97/Gated-Recurrent-UnitGRU의-이해
코드
핸즈온머신러닝
Leave a comment