
- Transformer는 Attention이라는 개념을 전적으로 활용하고 있음
딥러닝 기반의 기계 번역 발전 과정
- 최근의 GPT와 BERT도 Transformer 아키텍쳐를 활용함
- GPT는 트랜스포머의 디코더 활용
- BERT는 트랜스포머의 인코더 활용
- 발전과정: RNN(1986)-LSTM(1997)-Seq2Seq(2014)-Attention(2015)-Transformer(2017)-GPT(2018)-BERT(2019)-GPT-3(2020)
- Attention이 나오면서 Seq2Seq에 Attention을 적용하여 성능을 끌어올렸고, 이후에 Transfomer가 나오면서 RNN을 사용하지 않고 오직 attention 기법에 의존하여 아키텍쳐를 설계했더니 성능이 훨씬 좋아짐
- attention 이후에는 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전함
1. 기존 Seq2Seq 모델의 한계점
- context vector v에 소스 문장의 정보를 압축함 -> 이는 병목이 발생하여 성능 하락의 원인이 됨
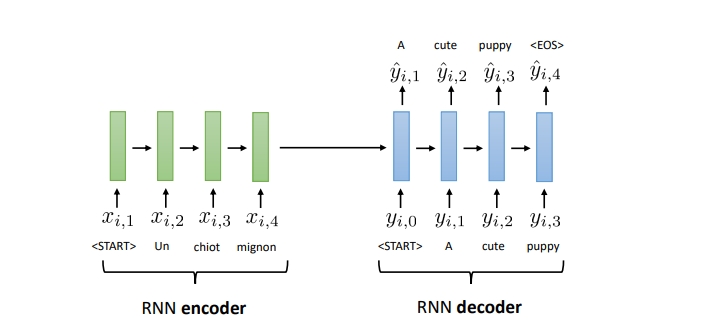
encoder part
- 각각의 독일 단어들이 하나의 sequence가 들어왔을 때 중간에서 고정된 크기의 context vector로 바꾼 뒤에 이것으로 부터 출력 문장을 만들어냄
- 한쪽의 sequence로부터 다른 sequence로 만듦
- 독일어 단어가 입력 될때마다 히든 스테이트 값이 생김 -> 이전까지 입력되었떤 단어들을 포함하고 있는 히든 스테이트를 새롭게 갱신함 -> 마지막 단어가 들어간 후 소스 문장의 전체를 대표하는 히든스테이트가 됨 -> 이 마지막 단어가 들어왔을 때의 히든 스테이트 값을 context vector로 사용할 수 있음 -> context vector에는 앞 문장의 문맥적인 정보를 담고 있다고 봄
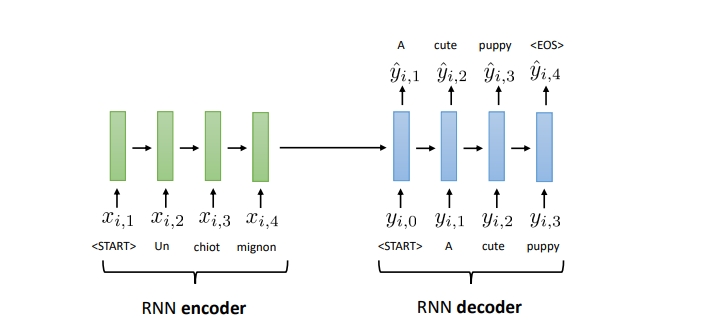
decoder part
- 이 context vector에서 시작해서 출력을 수행하는 decoder 파트에서는 매번 출력 단어가 들어올 때마다 이러한 context vector로부터 출발해서 히든 스테이트를 만들어서 출력을 내보냄
- 다음 단계에서는 이전에 출력했던 단어가 입력으로 들어와서 반복적으로 이전까지 출력했던 단어에 대한 정보를 가지고 있는 히든스테이트도 입력으로 받아 새로운 히든 스테이트를 갱신함
- 이런식으로 디코더 파트에서는 히든 스테이트 값을 갱신하면서 히든스테이트로부터 출력값이 EOS(end of sequence)가 나올때까지 반복함
한계점
- 소스 문장의 길이가 다양할 수 있는데 이를 하나의 고정된 context vector를 만들어야 한다는 점에서 전체 성능에서 병목 현상의 원인이 될 수 있음
- 하나의 문맥 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
해결방법: Sequence to Sequence + Attention

- 하나의 문맥 벡터에 대한 정보만 가지고 있는게 아니라 단어를 만들때마다 매번 소스 문장에서의 출력 값들 전부를 입력으로 받는 것에 대해 제안함
- seqence to seqeunce에 attention 매커니즘을 적용하는 것
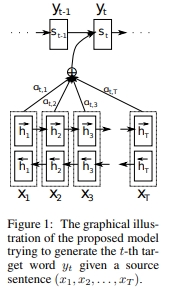
- 여기서 디코더는 인코더의 모든 출력(outputs)을 참고함
- 단어가 입력(xi)되어서 히든 스테이트(hi)가 나올 때마다 이 값들을 출력값으로 기록해둠 -> 각 단어를 거치면서 갱신되는 hidden state값을 가지고 있음
- 출력단어(si)가 생성될 때마다 소스 문장 전체를 반영하겠다는 것
- 디코더 파트에서 히든 스테이트를 갱신하게 되는데 현재 파트에서 히든 스테이트를 만든다고 하면 바로 이전의 히든 스테이트 값을 이용해서 출력단의 히든스테이트값인 si와 소스문장 단의 히든 스테이트 값 hi을 묶어서 행렬 곱을 수행해서 각각 에너지 값을 만들어냄
- 이 에너지 값은 내가 현재 어떠한 단어를 출력하기 위해서 소스 문장에서 어떠한 단어에 초점을 둘 필요가 있는지 수치화해서 표현한 값임
- 이 에너지 값에 softmax를 취해 확률값을 구한 뒤 소스 문장의 각각의 히든 스테이트 값에 대해서 어떤 벡터에 더 많은 가중치를 두어서 참고하면 좋을지를 반영해서 가중치 값을 히든 스테이트 값에 곱한 것을 각각의 비율에 맞게 더해준 다음 이러한 weighted sum을 매번 출력단어를 만들기 위해서 반영하겠다는 것
- 단순히 context vector만 참고하는 것이 아니라 소스 문장에서 출력되었던 모든 히든스테이트값을 전부 반영하는 것
- 어떤 단어에 더 주의집중해서출력결과를 만들 수 있는가를 모델이 고려하도록 만듦
- 매번 출력마다 소스 문장의 모든 단어를 참고해서 하나의 weighted sum 벡터를 구한 다음에 걔를 입력으로 넣어줘서 소스 문장을 모두 고려하도록 만들기 때문에 성능이 좋아짐
- 디코더는 매번 인코더의 모든 출력 중에 어떤 정보가 중요한지를 계산함
수식
- i: 현재 디코더가 처리 중인 인덱스
- j: 각각의 인코더 출력 인덱스
- 에너지(energy):
- 정의: 소스 문장에서 나왔던 모든 출력값들 중에서 어떤 값과 가장 연관성이 있는지를 구하기 위해서 수치를 구한 것
- 매번 디코더가 출력 단어를 만들 때마다 (i) 모든 인코더의 출력(j)을 고려함
- s는 디코더가 사용한 히든 스테이트
- h는 인코더 파트의 각각의 히든 스테이트
- 디코더 파트에서 내가 이전에 출력했던 건 s(i-1)인데
- 인코더의 모든 출력값 h(j)와 비교해서 에너지 값을 구하겠다는 것
- 어떤 hj값과 가장 많은 연관관계를 가지는지를 에너지값으로 구할 수 있는 것
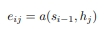
- 가중치(weight):
- 정의: 에너지를 소프트맥스에 넣어서 상대적인 확률값을 구한 것 = 가중치
- 이러한 에너지값에 softmax를 취해서 확률값을 구함
- 비율적으로 어떤 h값과 연관성이 높은지를 구함
- 이 가중치값을 h값과 곱해서 이 가중치가 반영된 각각의 인코더의 출력결과를 더해서 그것을 활용함
- weighted sum:
- 정의: 가중치 값들을 소스 문장의 히든스테이트와 각각 곱해줘서 전부 더해준 값을 디코더의 입력으로 넣어주겠다는 것
- 디코더 파트에서 현재 히든 스테이트 S(t)를 만들기 위해서 이전 히든 스테이트 S(t-1)값과 인코더 파트의 히든스테이트 값 h를 묶어서 에너지 값을 구한 뒤에 거기에 소프트맥스를 취한 뒤에 이러한 비율 값을 더할 수 있는 것
- 이렇게 곱한 값을 context vector로 사용할 수 있는 것(c 값)
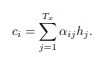
- 이를 통해 출력값을 정할 수 있는 것
장점
- 어텐션 가중치를 이용해 각 출력이 어떤 입력 정보를 참고했는지 알 수 있음
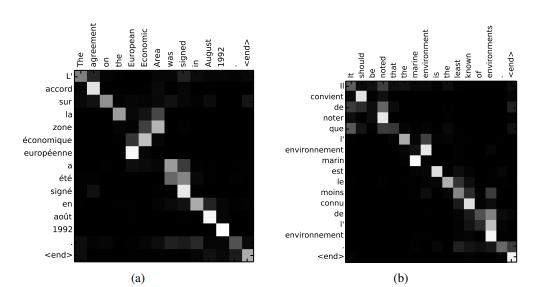
- 영어를 불어로 할 때 매번 출력할 때마다 입력 단어들 중에 어떠한 단어에 초점을 많이 뒀는지를 볼 수 있는 것 → 밝은 부분이 확률값이 높은 것
(논문 출처: https://arxiv.org/pdf/1409.0473.pdf?utm_source=ColumnsChannel)
2. 트랜스포머(Transformer)
- 최근 자연어 처리 네트워크에서의 핵심이 되는 논문
- 논문: Attention Is All You Need
- attention 기법만을 사용하므로 RNN이나 CNN은 적용하지 않음 → 사용하지 않으므로 문장 안의 순서에 대한 정보를 주기 어렵기 때문에 Positional Encoding을 사용하여 순서에 대한 정보를 줄 수 있음
- RNN을 사용하진 않지만 인코더와 디코더로 구성되는 것은 같음
- Attention을 한번만 쓰는 게 아니라 여러 레이어를 거쳐 반복하도록 만듦 (N)
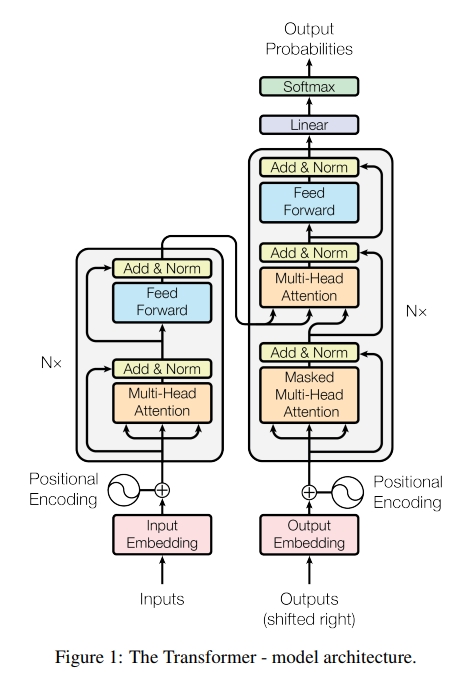
- 그림의 왼쪽 파트가 인코더, 오른쪽 파트가 디코더
트랜스포머 이전의 전통적인 임베딩
- 어떠한 단어를 네트워크에 넣기 위해서는 임베딩 과정을 거침
- 그 이유는 입력 차원 자체는 어떤 언어에서 존재할 수 있는 단어의 갯수와 같기 때문에 , 차원이 많을 뿐만 아니라 , 각각의 종류들은 원핫인코딩 형태로 표현이 되기 때문에 일반적으로 네트워크에 넣을 때는 먼저 임베딩 과정을 거쳐서 작은 차원의 continuous 값(실수값)으로 표현함
- ‘I am a teacher’라는 문장이 들어갔을 때 Input Embedding Matrix로 표현됨
- Input Embedding Matrix는 단어의 갯수만큼 행의 크기를 가짐, 열 데이터는 임베딩 차원과 같음
- 전통적인 임베딩은 네트워크에 넣기 전에 입력값들을 임베딩 형태로 표현하기 위해서 사용하는 레이어라고 볼 수 있음
트랜스포머 인코더의 임베딩(Positional Encoding)
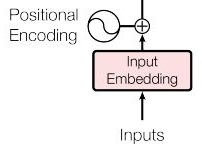
- seq2seq과 같은 RNN을 사용하지 않는다고 하면(RNN은 RNN을 사용하는 것만 하더라도 각각의 단어가 RNN에 들어갈 때 순서에 맞게 들어가기 때문에 자동으로 각각의 히든스테이트 값이 순서에 대한 정보를 가짐 )위치 정보를 가지고 있는 임베딩을 사용해야 함 → 이를 위해 트랜스포머에서는 Positional Encoding을 사용해야 함
- Positional Encoding: Input Embedding Matrix와 같은 dim을 가지는 위치에 대한 정보를 가지는 Positional Encoding 정보를 넣어줘서 각각 element wise로 더해줌으로 각각의 단어가 어떤 순서를 가지는 지를 알 수 있게 함
- 위치에 대한 정보까지 포함하는 입력값(입력값(’I am a teacher’) + 위치정보)을 실제 multi head 어텐션에 넣어줄 수 있도록 함 → 각각의 단어들을 사용해서 어텐션을 수행함
트랜스포머 인코더의 attention
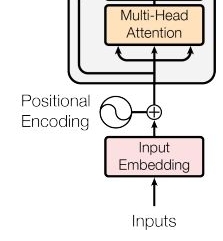
- 인코더 파트의 attention은 self attention : 각각 단어가 서로에게 어떤 연관성을 가지고 있는지 알기 위해 사용함 I am a teacher의 각각의 단어가 서로에게 어텐션 스코어를 구해서 다른 어떠한 단어와 높은 연관성을 가지는지에 대한 정보를 학습할 수 있음
- 여기서의 multi head attention은 입력 문장에 대한 문맥에 대한 정보를 잘 학습하도록 만드는 것임
트랜스포머 인코더의 Residual
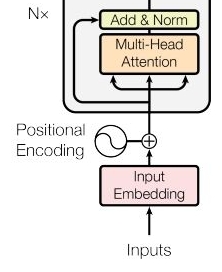
- residual learning 테크닉이 사용됨
- residual learning은 이미지 분류 네트워크인 Resnet에서도 사용되는 기법으로 어떠한 값을 레이어를 거쳐서 단순히 반복적으로 갱신하는 것이 아니라 특정 레이어를 건너 뛰어서 복사된 값을 그대로 넣어주는 것을 의미함 → 이렇게 건너 뛰어서 입력할 수록 만드는 것을 일반적으로 residual connection이라고 부름
- 이렇게 해줌으로써 전체 네트워크는 기존 정보를 입력 받으면서 추가적으로 잔여 부분만 학습하게 됨 → 이로 인해 전반적인 학습 난이도가 낮고 초기 모델 수렴 속도가 높게 되고 그로 인해 더욱 더 글로벌 optimal을 찾을 확률이 높아지기 때문에 전반적으로 다양한 네트워크에 대해서 residual learning을 사용했을 때 성능이 좋아짐 → 트랜스포머도 이러한 아이디어를 채택하여 성능을 높임
- 1) 어텐션을 수행해서 나온 값과 2) residual connection을 통해 바로 더해진 값을 바로 받아서 Normalization까지 수행해서 나오도록 만들어줌
- 여기까지가 인코더의 수행 과정임
트랜스포머 인코더의 전체 과정
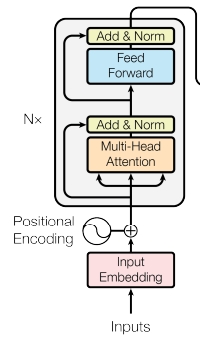
- 입력값이 들어온 이후 부터 어텐션을 거치고 → residual connection 후 normalization → 다시 feedforward layer를 거친 다음에 → residual connection 후 normalization를 추가해서 결과적으로 하나의 인코더 레이어에서 그 결과값을 뽑아낼 수 있음 → 이렇게 어텐션과 정규화 과정을 반복하는 방식으로 여러개의 레이어를 중첩해서 사용함
- 여기서 한 가지 주의할 점은 각각의 레이어는 서로 다른 파라미터를 가짐(각 레이어의 attention과 feedforward layer에서 사용되는 파라미터는 다름)
- 각각 레이어의 입력 dim과 출력 dim은 같음
트랜스포머의 디코더
- 인코더에서 입력값 들어와서 여러 개의 인코더 레이어를 반복해서 가장 마지막에 나온 인코더의 출력값(N번째)은 디코더에 넣어줌
- seq2seq의 attention 매커니즘 활용했듯이 디코더 파트에서는 매번 출력할 때마다 입력소스 문장 중에서 어떤 단어에 가장 많은 초점을 둬야하는지를 알려주기 위함임
- 디코더 파트도 여러개의 레이어로 구성되고 마지막 레이어에서의 출력값이 실제 번역을 수행한 결과, 출력 단어가 됨
- 디코더의 각각의 레이어는 인코더의 마지막 레이어의 출력값을 입력을 받음
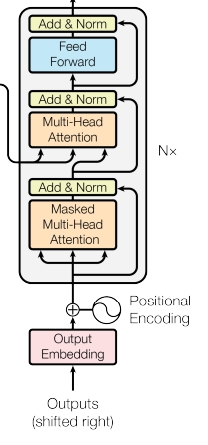
- 디코더도 마찬가지로 1) 각각 단어정보를 받아서 2) positional encoding을 추가한 다음에 3) 2개의 attention을 사용하는데 첫번째는 self attention으로 각 단어들이 서로가 서로에게 어떠한 가중치를 가지는지를 구하도록 만들어서 출력되는 문장에 대한 전반적인 표현을 학습하도록 만듦 이어서 디코더 레이어의 두번째 어텐션은 인코더에 대한 정보를 어텐션할 수 있게 만듦 → 다시 말해 각각의 출력 단어가 인코더의 출력 정보를 받아와 사용할 수 있게 만듦 = 각각의 출력되는 단어가 소스 문장에서의 어떤 단어와 연관성이 있는지를 구해주는 것임 그래서 두번째 어텐션은 인코더 디코더 어텐션이라고 불림(입력: I am a teacher, 출력: 선생님 → 선생님이라는 단어는 입력 문장의 단어중 어떤 단어와 가장 연관이 있는지를 봄) 이러한 정보를 매번 어텐션을 통해 계산하도록 만들어서 인코더 파트에서 나온 출력결과를 전적으로 활용하도록 네트워크를 설계할 수 있는 것
- 디코더도 마찬가지로 입력 dim과 출력 dim이 같도록 만들어서 디코더 레이어를 여러번 중첩되게 만듦
- 정리: 트랜스포머에서 마지막 인코더 레이어의 출력이 모든 디코더 레이어에 입력으로 들어감 : 디코더 파트의 두번째 어텐션에 들어감
- 트랜스포머는 RNN을 사용하지 않으며 인코더와 디코더를 다수 사용함
- RNN에서는 고정된 크기로 사용하고 입력하는 단어의 갯수만큼 반복적으로 인코더 레이어를 거쳐서 매번 히든 스테이트를 만들었다고 하면 트랜스포머는 입력 단어자체가 하나로 쭉 연결되어 한벌에 입력이 되고 한번에 그에 대한 어텐션 값을 구할 수 있음 → 다시 말해 RNN과는 다르게 위치정보를 한번에 넣어서 인코더를 거칠때마다 병렬적으로 출력값을 구해낼 수 있기 때문에 RNN과 비교했을 때 계산복잡도가 낮음
Multi head attention
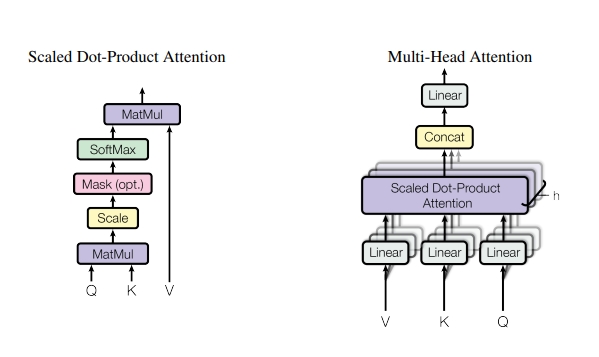
- 트랜스포머에서 사용되는 어텐션은 여러 head를 가진다고 해서 multi head attention이라고 불림
- multi head attention의 중간에는 scaled dot product attention이 있음
- 3가지 요소를 가짐 1) 쿼리 Q 2) 키 K 3) 값 V
- 쿼리는 무언가를 물어보는 주체
- 키는 물어보는 대상
- I am a teacher(여기서 각 단어가 키 K)에서 I(쿼리 Q)가 각 단어와 얼마나 연관성이 있는가
- 그리고 value 값과 곱해서 어텐션 value값을 구할 수 있음
- scaled dot product attention: 물어보는 주체(Q)가 들어오고 각각 어텐션을 수행할 단어들인 K가 들어가서 행렬곱(matmul)을 수행해주고 scale을 진행해주고 필요하면 mask를 씌워준다음에 softmax를 취해서 각각의 키 중에서 어떤 단어와 가장 높은 연관성을 가지는지 비율을 구할 수 있음 → 이 확률값과 Value 값을 곱해서(matmul) → 결과적인 어텐션 벨류를 얻을 수 있음
- 실제로 입력값이 들어왔을 때 그런 입력값들은 h개로 구분됨 → 어떠한 입력 문장이 들어왔을 때 그것은 V,K,Q로 구분되는데 h개의 서로 다른 V, K, Q로 구분되게 만드는데 이유는 h개의 서로 다른 어텐션 컨셉을 학습하도록 만들어서 더욱더 구분된 다양한 특징들을 학습할 수 있도록 유도해준다는 장점이 있음 → 이와 같이 입력으로 들어온 값은 3개로 복제가 되어서 V, K, Q로 들어가게 되고 이들은 linear layer(행렬곱)을 수행해서 h개로 구분된 각각의 쿼리쌍들을 만들어내게 되고 여기에서 h는 head의 갯수이기 때문에 서로 다른 head끼리 V, K, Q 쌍을 받아서 각각 어텐션을 수행해서 결과를 내보냄 → 어텐션의 입력과 출력의 dim은 같아야 하므로 각 head로 부터 나온 어텐션 값을 concat해서 일자로 쭉 붙이고 마지막으로 linear로 아웃풋 값을 내보내게 됨
- 하나의 어텐션은 Q,K,V를 가지고 Q와 K를 곱해서 각 Q에 대해서 각각의 K에 대한 에너지 값을 구해서 softmax로 확률값으로 만들고 scale을 함(각각의 K dim) → 그리고 V값과 곱해줌
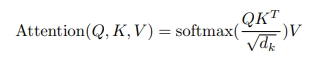
- 입력으로 들어오는 각각의 값에 대해서 서로 다른 linear layer를 거치도록 만들어서 h개의 서로 다른 각각의 Q,K,V를 만들도록 함 →h개의 서로 다른 컨셉을 네트워크가 구분해서 학습하도록 함 → 어텐션을 수행하도록 다양한 피처들을 학습하게 만듦

- 결과적으로 각 head에 대한 출려값들을 구할 수 있고 (head1~headh) 이것을 일자로 쭉 붙인 다음에 마지막으로 output matrix(Wo)와 곱해서 multihead attention을 구해낼 수 있음
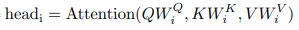
References
- 유튜브 영상:
https://www.youtube.com/watch?v=AA621UofTUA
- 강의 자료:
- 논문:
- Seq2Seq + Attention: NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
- Transformer: Attention Is All You Need
4.코드:
Leave a comment