[머신러닝] GBM
GBM
1. 부스팅 알고리즘 개요
- 부스팅 알고리즘은 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식임
- 부스팅의 대표적인 구현은 AdaBoost와 그래디언트 부스트가 있음
- AdaBoost: 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘
- 모두 트리 기반의 알고리즘
2. Adaboost

1) 가장 처음에는 약한 학습기가 분류한 기준1로 +,와 -를 분류함, -쪽에 들어가있는 +,는 데이터가 잘못 분류된 오류 데이터
2) 두번째 분류에서는 1)번의 오류 데이터에 대해 가중치 값을 부여함, 가중치가 부여된 오류 + 데이터는 다음 약한 학습기가 더 잘 분류할 수 있도록 크기가 커짐
3) 2)번의 분류 기준 2로 +,와 -를 분류함
4) 잘못 분류된 -에 대해 가중치를 부여함
5) 세번째 분류에서는 분류기준 3으로 분류하고 오류 데이터를 찾음
→ 에이다부스트는 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행함
→ 첫번째, 두번째, 세번째 약한 학습기를 모두 결합함 → 개별의 약한 학습기 보다 훨씬 정확도가 높아짐
3. 그래디언트 부스팅(GBM)
- GBM과 에이다부스트의 차이점: 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용하는 것이 차이임. (경사하강법: 오류식 h(x) = y-F(x)를 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트 하는 것임, 반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법)
- GBM은 CART 기반의 다른 알고리즘과 마찬가지로 분류와 회귀 모두 가능함
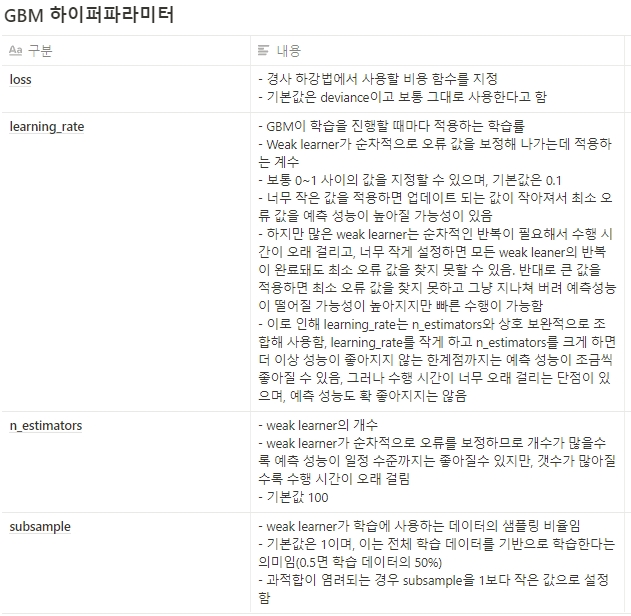
- 일반적으로 랜덤포레스트보다 더 나은 예측성능을 뛰어난 경우가 많다고 함, 그러나 수행 시간이 오래 걸리고 하이퍼 파라미터 튜닝도 더 필요함
- GBM은 과적합에도 강한 뛰어난 예측 성능을 가진 알고리즘이지만, 수행 시간이 오래 걸림
- GBM이 소개 된 후 많은 알고리즘이 GBM을 기반으로 만들어지고 있음