
[머신러닝] K-means
K-means
[K-means의 개념과 활용 방법]
1.군집화
- unsupervised learning으로, 데이터 간의 유사도를 정의하고 그 유사도에 가까운 것부터 순서대로 합쳐 가는 방법이며, 유사도의 정의에는 거리나 상관계수 등이 사용됨
- 목적: 데이터의 일부 속성을 학습하고 특정 방식으로 특징의 구조를 표현
- 군집화는 단순히 점들이 서로 얼마나 유사한지에 따라 그룹에 데이터 점을 할당하는 것
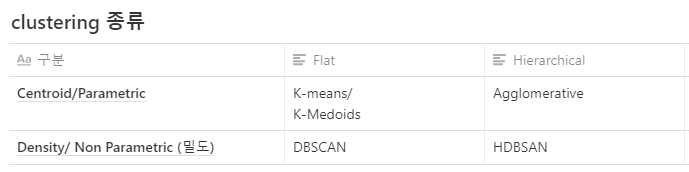
- clustering에는 centroid based와 density based 존재
2.K-means의 개념
- 직선 거리 (유클리드 거리, 다른 말로 유클리드 거리)를 사용하여 유사성을 측정
- 공간 내에 중심점이라고 하는 여러 점을 배치하여 클러스터를 만듦
- K 평균의 K는 생성하는 군집 수

3.K-means 알고리즘 작동 방법
1) 중심점을 임의로 선정 2) 각 데이터 포인트에 대해 가장 가까운 중심점을 찾고, 해당 군집을 할당 3) 할당된 군집을 기반으로 새로운 중심점 계산 4) 각 클러스터의 중심점이 더 이상 움직이지 않거나 최대 반복 횟수가 될때까지 2)와 3)의 단계를 반복함
- 중심점이 더 이상 움직이지 않거나 최대 반복 횟수가 지날때까지 이 단계를 반복함
- 중심부의 초기 랜덤 위치가 군집화가 잘 되지 않은 상태로 끝나는 경우가 있는데 이러한 이유로 여러번 반복(n_init)하고 각 점과 해당 중심 사이의 총 거리가 가장 작은 군집을 반환함
- 초기 중심부에 대한 결과의 의존성과 수렴될때까지 반복하는 것이 필요함 3) 최적의 K를 찾기(Elbow method)
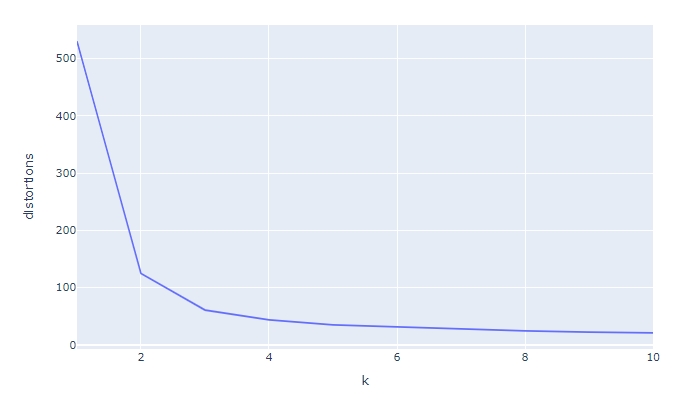
4.K-means 최적의 K 찾는 방법1 (Elbow method)
-Elbow method: total intra-cluster variation (or total within-cluster sum of square (=WSS))**가 최소가 되는 k를 찾는 방법(cluster내의 거리)
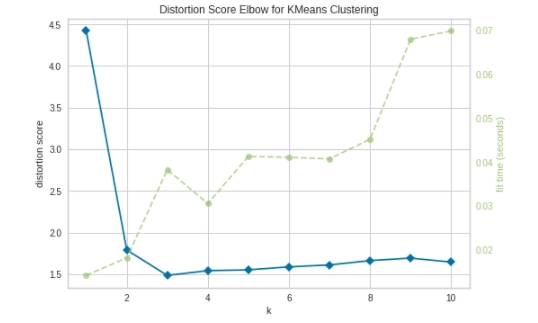
- KElbowVisualizer를 사용하면 elbow method 그래프 뿐만 아니라 훈련시간까지 확인이 가능함
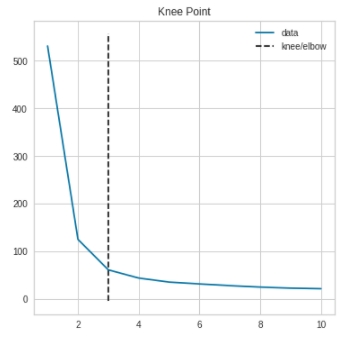
- Kneed 모듈을 사용하면 그래프를 사용하지 않고도 최적의 k값을 자동으로 찾아줌
5. K-means 최적의 K 찾는 방법2 (Silhouette method)
- cluster내의 거리와 cluster간의 거리를 계산하여 Silhouette coefficient(SC)값이 최대가 되는 k를 찾는 방법.
- SC: 각 cluster 사이의 거리가 멀고 cluster 내 데이터의 거리가 작을수록 군집 분석의 성능을 좋다고 봄, SC 값은 -1~1로 구성되며, 0의 경우 클러스터간 변별력이 없다는 의미이며, -1에 가까울수록 클러스터링 결과가 좋지 않음
6. K-means clustering 평가 방법
- 다차원이 될수록 그래프를 통해 클러스터링 결과 확인이 어려우므로, 객관적인 수치 평가 방법이 필요하여 accuruacy score를 계산함
7. K-means의 단점
1) Noise와 outlier에 민감 2) 처음 시작 점이 결과에 영향을 줌 3) K값을 직접 설정해야하는 어려움 존재
이러한 단점을 보완해주는 클러스터링 방법이 있음
#3 8.Hierarchical clustering
장점 1) clustering 수인 K를 정하지 않아도 사용 가능 2) 랜덤 포인트에서 시작하지 않아 시작점이 결과에 영향을 주지 않음 3) dendrogram을 통해 전체적인 군집 확인이 가능함
단점 1) 계산이 많아 대용량 데이터에 비효율적임
reference https://www.kaggle.com/ryanholbrook/clustering-with-K-means
Leave a comment