
[Hugging Face][C-3] FINE-TUNING A PRETRAINED MODEL - Processing the data
0. Introduction
- 2장에서는 토크나이저와 사전 학습된 모델을 사용하여 예측을 수행하는 방법을 살펴봄
- 가지고 있는 고유의 데이터셋을 가지고 기존의 사전 학습된 모델을 미세 조정(fine-tune)하려면 어떻게 해야 할지에 대해 배우고자 함
- 허브(Hub)에서 대규모 데이터셋을 가지고 오는 방법에 대해서 배움
- 고급 Trainer API를 사용하여 모델을 미세 조정(fine-tune)하는 방법을 공부함
- 사용자 지정 학습 루프(custom training loop)을 사용하는 방법을 알아보고자 함
- Accelerate 라이브러리를 활용하여 분산 환경에서 사용자 지정 학습 루프(custom training loop)을 쉽게 실행하는 방법을 공부함
- 미세 조정된 checkpoint를 Hugging Face Hub에 업로드하려면 huggingface.co 계정이 필요함
1. Overview
시작
- 2장에서 공부한 것과 같이, PyTorch에서 단일 배치(batch)를 기반으로 sequence classifier를 학습하는 방법은 다음과 같음
import torch
from transformersimport AdamW, AutoTokenizer, AutoModelForSequenceClassification
# 2장의 예제와 동일합니다.
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
# 새롭게 추가된 코드입니다.
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
loss = model(**batch).loss
loss.backward()
optimizer.step()
Downloading: 0%| | 0.00/420M [00:00<?, ?B/s]
Some weightsof the model checkpointat bert-base-uncased werenot usedwhen initializing BertForSequenceClassification: ['cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.seq_relationship.bias']
- ThisIS expected if youare initializing BertForSequenceClassificationfrom the checkpointof a model trainedon another taskorwith another architecture (e.g. initializing a BertForSequenceClassification modelfrom a BertForPreTraining model).
- ThisISNOT expected if youare initializing BertForSequenceClassificationfrom the checkpointof a model that you expectto be exactly identical (initializing a BertForSequenceClassification modelfrom a BertForSequenceClassification model).
Some weightsof BertForSequenceClassification werenot initializedfrom the model checkpointat bert-base-uncasedandare newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this modelon a down-stream taskto be ableto use itfor predictionsand inference.
- 두 문장만으로 모델을 학습하는 것으로는 그다지 좋은 결과를 얻을 수 없음
- 더 좋은 결과를 얻으려면, 더 큰 데이터셋을 준비해야 함
- 이 섹션에서는 William B. Dolan과 Chris Brockett의 논문에서 소개된 MRPC(Microsoft Research Paraphrase Corpus) 데이터셋을 예제로 사용할 예정
- 이 데이터셋은 5,801건의 문장 쌍으로 구성되어 있으며 각 문장 쌍의 관계가 의역(paraphrasing) 관계인지 여부를 나타내는 레이블이 존재함(즉, 두 문장이 동일한 의미인지 여부). 데이터셋의 규모가 그리 크지 않기 때문에 학습 과정을 쉽게 실험할 수 있음
Hugging Face Datasets Overview with Sylvain

- Hugging Face Datasets 라이브러리는 많은 공개 데이터셋을 빠르게 다운로드하고 전처리할 수 있는 API를 제공하는 라이브러리임

- load_dataset 함수를 사용하면 데이터셋 허브의 식별자에서 데이터셋을 직접 다운로드하고 캐시할 수 있음
- 여기서는 GLUE 벤치마크에서 MRPC 데이터셋을 가져옴
- 이 데이터셋은 의역을 결정하는 작업이 있는 문장 쌍을 포함하는 데이터셋임
-
load_dataset 함수에서 반환된 개체는 데이터셋의 각 분할을 포함하는 일종의 사전인 DatasetDict임

- 이름으로 색인을 생성하여 각 분할에 액세스할 수 있음
-
이 분할은 열, 여기서는 (문장1, 문장2, 라벨 및 idx) 와 행이 있는 Dataset 클래스의 인스턴스임

- 인덱스를 통해 특정 요소에 접근할 수 있음
- Hugging Face 데이터셋 라이브러리의 좋은 점은 모든 것이 Apache Arror를 사용하여 디스크에 저장된다는 점임
- 즉, 데이터셋이 크더라도 RAM이 부족하지 않고, 요청한 요소만 메모리에 로드됨
-
데이터셋 조각에 액세스하는 것은 쉬움


- 결과는 각 키에 대한 목록이 포함된 dictionary임
- 여기서는 (라벨 목록, 첫 번째 문장 목록, 두 번째 문장 목록)
-
데이터셋의 기능 속성은 해당 열에 대한 추가 정보를 제공함


-
특히 여기서는 라벨의 정수와 이름 사이의 대응 관계를 제공하는 것을 볼 수 있음
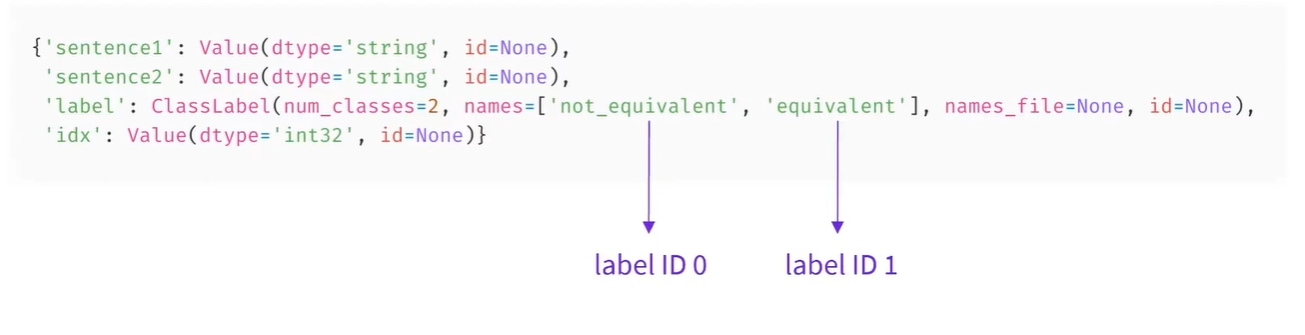
-
0은 동등하지 않음을 나타내고, 1은 동등함을 나타냄

- 데이터셋의 모든 요소를 사전 처리하려면 해당 요소를 토큰화해야 함
- 복습을 위해서는 preprocess sentence pair를 시청할 것
- 몇 가지 추가 키워드 인수를 사용하여 두 문장을 토크나이저에 보내기만 하면 됨
-
여기서는 최대 길이가 128임을 나타내며, 이 길이보다 짧은 입력은 입력하고 더 긴 입력은 자름

- 이 모든 것을 map method를 사용하여 데이터셋의 모든 분할에 직접 적용할 수 있는 tokenize_fuction에 넣음
-
함수가 사전과 유사한 객체를 반환하는 한 map method는 필요에 따라 새 열을 추가하거나 기존 열을 업데이트함

- 전처리 속도를 높이고 Hugging Face Tokenizers 라이브러리 덕분에 토크나이저가 Rust의 지원을 받는 부분을 활용하기 위해 batched = True 인수를 사용하여 토큰화 함수에 대해 여러 요소를 동시에 처리할 수 있음
- 토크나이저는 첫 번째/두 번째 문장 목록을 처리할 수 있으므로 이를 위해 tokenize_fuction을 변경할 필요가 없음
- map method으로 다중 처리를 사용할 수 있음
-
이 작업이 완료 되면 학습 준비가 거의 완료됨
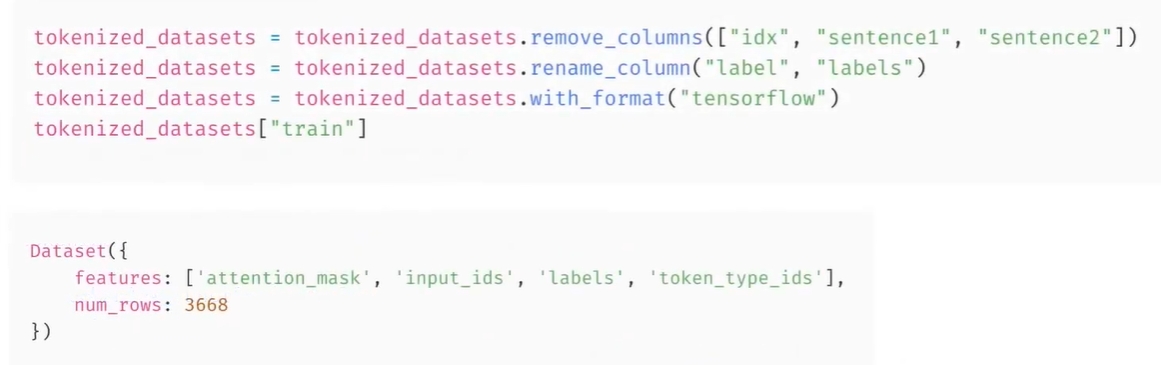
-
필요하지 않은 열을 remove_columns method로 제거하고, 라벨의 이름을 라벨로 바꾸고 출력 형식을 다음으로 설정함

- desired backend: torch, tensorflow, numpy, 필요할 경우, select 메소드를 사용하여 데이터셋의 짧은 샘플을 생성할 수도 있음
2. **Loading a dataset from the Hub**
**Loading a dataset from the Hub**
- 허브(hub)에는 모델만 존재하는 것이 아님
- 다양한 언어로 구축된 여러 데이터셋들도 있음
- 여기에서 다양한 데이터셋을 탐색할 수 있으며, 이 섹션을 완료한 후에는 다른 데이터셋을 로드하고 처리해 보기를 권장함 (여기에서 일반 문서 참조).
- MRPC 데이터셋을 보고자 함
- 이 데이터셋은 10개의 데이터셋으로 구성된 GLUE 벤치마크 중 하나임
- GLUE 벤치마크는 10가지 텍스트 분류 작업을 통해서 기계학습 모델의 성능을 측정하기 위한 학술적 벤치마크 데이터 집합임
- Datasets 라이브러리는 허브(hub)에서 데이터셋을 다운로드하고 캐시(cache) 기능을 수행하는 쉬운 명령어를 제공함
- 다음과 같이 MRPC 데이터셋을 다운로드할 수 있음
from datasets import load_dataset
raw_datasets = **load_dataset**("glue", "mrpc")
raw_datasets
Downloading: 0%| | 0.00/7.78k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/4.47k [00:00<?, ?B/s]
Downloading and preparing dataset glue/mrpc (download: 1.43 MiB, generated: 1.43 MiB, post-processed: Unknown size, total: 2.85 MiB) to /home/spasis/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad...
0%| | 0/3 [00:00<?, ?it/s]
Downloading: 0.00B [00:00, ?B/s]
Downloading: 0.00B [00:00, ?B/s]
Downloading: 0.00B [00:00, ?B/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
Dataset glue downloaded and prepared to /home/spasis/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad. Subsequent calls will reuse this data.
0%| | 0/3 [00:00<?, ?it/s]
DatasetDict({
**train**: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
**validation**: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
**test**: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
- 위 결과에서 보듯이, 학습(training), 검증(validation) 및 평가(test) 집합이 저장된
DatasetDict객체를 얻을 수 있음 - 이들 각각은 여러 종류의 열(columns)(
sentence1,sentence2,label및idx)과 행(row)의 개수를 포함하는데, 여기서 행(row)의 개수는 각 집합의 문장쌍의 개수를 나타냄 - 따라서, 학습 집합(training set)에는 3,668개의 문장 쌍, 검증 집합(validation set)에는 408개, 평가 집합(test set)에는 1,725개의 문장 쌍이 있음
load_dataset명령은 기본적으로 ~/.cache/huggingface/dataset에 데이터셋을 다운로드하고 임시저장(캐시, cache)함- 2장에서 보았듯이,
HF_HOME환경 변수를 설정하여 캐시 폴더를 변경할 수 있음 - 파이썬의 딕셔너리(dictionary)와 같이 키값으로
raw_datasets개체의 개별 집합(학습, 검증, 평가)에 접근할 수 있음
raw_train_dataset = **raw_datasets["train"]**
raw_train_dataset[0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0}
- 위의 예에서 보듯이, 레이블(label)이 이미 정수(integers)라서 전처리(preprocessing)가 필요 없음
- 어떤 정수가 어떤 레이블에 해당하는지 파악하기 위해서는
raw_train_dataset의features속성을 살펴보면 됨
**raw_train_dataset.features**
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
- 세부적으로, 레이블(label)은
ClassLabel타입이고 레이블 이름에 대한 정수 매핑은 names 폴더에 저장되어 있음 - 0은
not_equivalent를 의미하고, 1은equivalent를 나타냄
3. **Preprocessing a dataset**
Preprocessing Sentences pairs with Sylvain

- 문장 쌍을 전처리하는 방법은 무엇인가? ‘Batching inputs together’ 동영상에서 단일 문장을 토큰화하고 일괄 처리하는 방법을 살펴봄
- 여기서는 sentences pair를 분류하는 작업에 중점을 두고자 함
-
예를 들어, 두 텍스트가 의역인지 아닌지를 분류하고 싶을 수 잇음

- 다음은 중복 질문 식별에 초점을 맞춘 Quora Question Pairs dataset에서 가져온 예임
- 첫 번째 쌍에서 두 질문이 중복 됨
-
두 번째에서는 그렇지 않음

- 또 다른 pair classification 문제는 두 문장이 논리적으로 관련되어 있는지 여부를 알고 싶은 경우임(자연어 추론 또는 NLI라는 문제)
- MultiNLI 데이터셋에서 가져온 이 예에는 모순, 중립, 수반(첫 번째 문장이 두 번째 문장을 의미한다는 의미)과 같은 가능한 각 레이블에 대한 한 쌍의 문장이 있음
-
따라서 문장 쌍을 분류하는 것은 연구할 가치가 있는 문제임

-
실제로 텍스트 분류에 대한 학문적 벤치마크인 GLUE 벤치마크에서 10개 데이터셋 중 8개는 문장 쌍을 사용하는 작업에 중점을 두고 있음
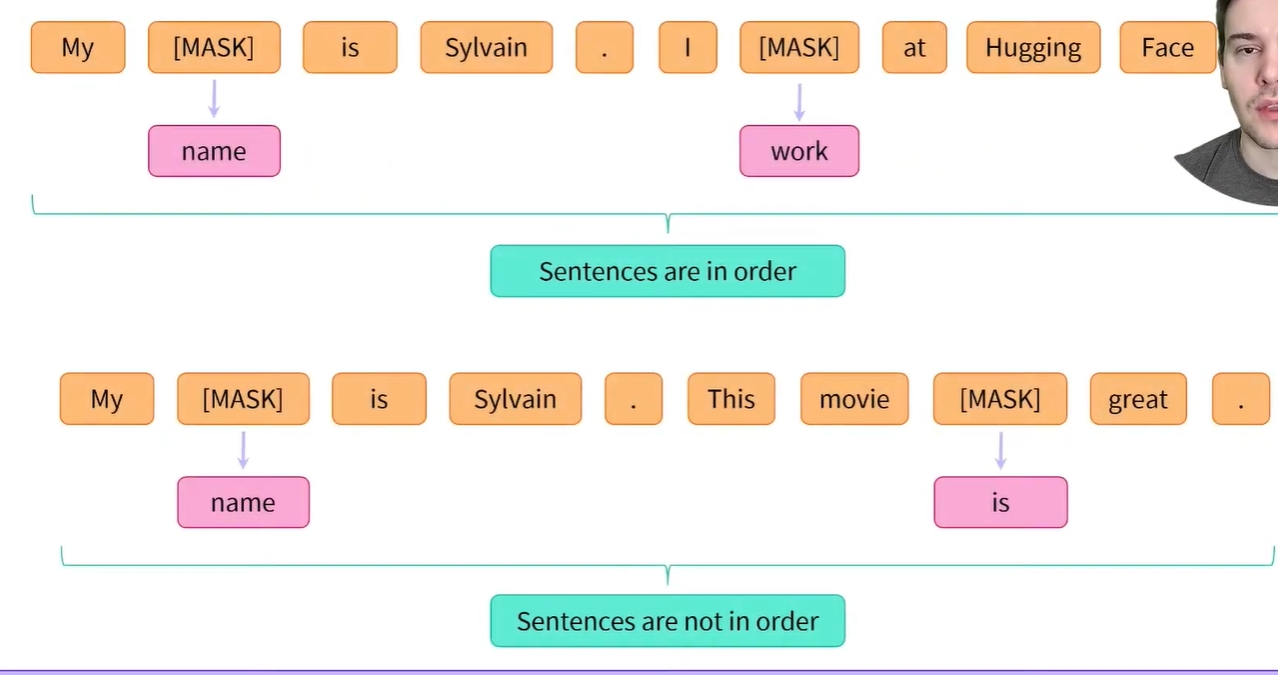
- 그렇기 때문에 BERT와 같은 모델은 이중 목표로 사전 학습되는 경우가 많음
- 언어 모델링 목표 외에도 문장 쌍과 관련된 목표를 갖는 경우가 많음

- 예를 들어, 사전 학습 중에 BERT는 문장 쌍으로 표시되며 무작위로 마스킹된 토큰의 값과 두 번째 문장이 첫 번째 문장에서 이어지는지 여부를 모두 예측해야 함
- 다행히 Transformers 라이브러리의 토크나이저에는 문장 쌍을 처리할 수 있는 API가 있음
- 문장 쌍을 토크나이저에 두 개의 인수로 전달하기만 하면 됨
- 이미 연구한 입력ID와 attetnion mask위에 토큰 유형 ID라는 새로운 필드를 반환함
- 이 필드는 어떤 토큰이 첫 번째 문장에 속하고 어떤 토큰이 두 번째 문장에 속하는지 모델에 알려줌
-
조금 확대하면 여기에 해당하는 토큰, 해당 토큰 유형 ID 및 attention mask에 맞춰 정렬된 입력ID가 있음

-
토크나이저가 특수 토큰도 추가하여 CLS 토큰, 첫번째 문장의 토큰, SEP 토큰, 두 번째 문장의 토큰, 최종 SEP 토큰이 있는 것을 볼 수 있음

-
여러 쌍의 문장이 있는 경우, 첫 번째 문장 목록을 전달한 다음 두 번째 문장 목록과 이미 연구한 모든 키워드 인수 (예: padding =T)를 전달하여 함께 토큰화할 수 있음

- 결과를 확대하면 토크나이저가 문장의 두 번째 쌍에 패딩을 추가하여 두 문장에 대한 토큰 유형 IDS 및 attetnion mask를 올바르게 처리한 방법을 확인할 수 있음

- 이제 모델을 통과할 준비가 완료됨
데이터셋 전처리
- 데이터셋 전처리를 위해서는 우선적으로 텍스트를 모델이 이해할 수 있는 숫자로 변환해야 함
- 이전 장에서 보았듯이 이는 토크나이저가 담당해야 함
- 토크나이저에 단일 문장 또는 다중 문장 리스트를 입력할 수 있으므로, 다음과 같이 각 쌍의 모든 첫 번째 문장과 두 번째 문장을 각각 직접 토큰화할 수 있음
from transformersimport AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
- 하지만 두 개의 시퀀스를 모델에 바로 전달(각각의 문장을 모델에 별도로 매개변수로 전달)하여 두 문장이 의역인지 아닌지에 대한 예측을 얻을 수는 없음
- 두 시퀀스를 쌍(pair)으로 처리(단일 매개변수로 처리)하고 적절한 전처리를 적용해야 함
- 다행히도 토크나이저(tokenizer)는 다음과 같이 한 쌍의 시퀀스를 가져와 BERT 모델이 요구하는 입력 형태로 구성할 수 있음
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
{'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- 위 코드에서 만일 첫번째 및 두번째 매개변수가 단일 문자열이 아니고 다중 문자열이 담긴 파이썬 리스트라면 각 리스트에 저장된 문자열(문장)의 순서대로 한 쌍씩 토큰화됨
- 다시 말해서, 첫번째 리스트의 첫번째 문자열과 두번째 리스트의 첫번째 문자열이 하나의 문자열 쌍으로 입력되는 방식임
- 2장에서
input_ids및attention_mask키값에 대해서는 논의했지만,token_type_ids에 대한 이야기는 하지 않았음 - 위의 예에서 보듯이,
token_type_ids는 전체 입력(input_ids)의 어느 부분이 첫 번째 문장이고 어느 것이 두 번째 문장인지 모델에 알려줌 input_ids내부의 ID들을 다시 단어로 디코딩하면:
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
['[CLS]',
'this',
'is',
'the',
'first',
'sentence',
'.',
'[SEP]',
'this',
'is',
'the',
'second',
'one',
'.',
'[SEP]']
- 따라서 모델은 두 개의 문장으로 구성되고 입력의 형태가 “[CLS] 문장1 [SEP] 문장2 [SEP]”와 같이 될 것으로 짐작할 수 있음.
- 이를
token_type_ids와 정렬하면 다음과 같음
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
- 위에서 보는 바와 같이, “[CLS] 문장1 [SEP]”에 해당하는 입력 부분은
token_type_id가 0이고 “문장2 [SEP]”에 해당하는 다른 부분은 모두 1임 - 다른 체크포인트(checkpoint)를 선택한다면, 토큰화된 입력(tokenized inputs)에
token_type_ids가 존재하지 않을 수도 있음 - 예를 들어, DistilBERT 모델을 사용하는 경우에는
tokenizer가token_type_ids를 반환하지 않음 - 모델이 사전학습 과정에서 이러한 형태의 입력 형식으로 학습을 진행했을 경우에만 반환됨
- 여기서, BERT는 토큰 타입 IDs를 사용하여 사전 학습되며, 1장에서 설명한 masked language modeling objectives 외에 다음 문장 예측(next sentence prediction) 이라는 추가 objectives가 있음.
- 이 작업의 목표는 문장 간의 관계를 모델링하는 것임
- 사전 학습 과정에서 다음 문장 예측(next sentence prediction)을 사용하면 모델에 무작위로 마스킹된 토큰(masked tokens)이 포함된 문장 쌍이 입력되고 두 번째 문장이 첫 번째 문장을 따르는지 여부를 예측하도록 요구됨
- 학습 과정에서 이 작업(next sentence prediction)의 난도를 높이기 위해서, 입력의 약 50% 정도는 두 문장이 원본 문서에서 연속적으로 나타나는 쌍 집합이며, 나머지 50%는 문장 쌍을 서로 다른 문서에서 추출된 문장들로 구성함
- 일반적으로, 토큰화 완료된 입력에
token_type_ids가 있는지 여부에 대해 걱정할 필요가 없음 - 토크나이저와 모델 모두에 동일한 체크포인트(checkpoint)를 사용하는 한, 토크나이저는 모델에 무엇을 제공해야 하는지 알고 있기 때문에 아무런 문제가 되지 않음
- 이제 토크나이저가 한 쌍의 문장을 처리하는 방법을 보았으므로, 이를 전체 데이터셋을 토큰화(tokenize)하는데 사용할 수 있음.
- 이전 장에서처럼, 우리는 토크나이저에게 첫 번째 문장 리스트를 제공하고 그 다음 두 번째 문장 리스트를 제공함으로써 문장 쌍 리스트를 입력할 수 있음
- 이것은 2장에서 본 패딩(padding) 및 절단(truncation) 옵션과도 호환됩니다. 따라서 학습 데이터셋을 전처리하는 한 가지 방법은 다음과 같음
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
- 이 방법은 잘 작동하지만,
input_ids,attention_mask,token_type_ids및 데이터가 담겨진 다차원 리스트가 키로 지정된tokenized_dataset이라는 별도의 파이썬 딕셔너리를 반환하는 단점이 있음 - 또한 이 방법은 토큰화하는 동안 전체 데이터셋을 저장할 충분한 공간의 RAM이 있는 경우에만 작동함
- 반면, Datasets 라이브러리의 데이터셋들은 디스크에 저장된 Apache Arrow 파일이므로, 요청한 샘플만 메모리에 로드된 상태로 유지함
- 특정 데이터를
dataset객체로 유지하기 위해[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map)메서드를 사용함 - 이 방법은 토큰화(tokenization) 외에 더 많은 전처리가 필요한 경우 유연성을 발휘함
map()메서드는 데이터셋의 개별 요소에 함수(function)를 적용하여 작동하므로 입력을 토큰화하는 함수를 정의해 보고자 함
deftokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
- 이 함수는 데이터셋의 개별 항목이 담겨진 딕셔너리를 매개변수로 입력받아서
input_ids,attention_mask및token_type_ids키가 지정된 새로운 딕셔너리를 반환함 - 이전에 본 것처럼 토크나이저(tokenizer)는 문장 쌍 리스트에서 작동하기 때문에
example딕셔너리에 여러 샘플(각 키가 문장 목록임)이 포함된 경우에도 작동함 - 이렇게 하면
map()호출에서batched=True옵션을 사용할 수 있어 토큰화 속도가 크게 빨라짐 - 토크나이저는 Tokenizers 라이브러리에서 Rust로 작성된 또 다른 토크나이저에 의해 지원됨
- 이 토크나이저는 매우 빠를 수 있지만, 한 번에 많은 입력을 제공하는 경우에만 그럼
- 일단 현재는 토큰화 함수에서
padding매개변수를 생략함. - 이는 모든 샘플들을 최대 길이로 채우는 것(padding)이 효율적이지 않기 때문임
- 배치(batch) 형태로 실행할 때 샘플을 채우는 것(padding)이 효과를 발휘함
- 그러면 전체 데이터셋에서의 최대 길이가 아니라 해당 배치(batch) 내에서의 최대 길이로 채우기만(padding) 하면 되기 때문임
- 이것은 입력의 길이가 매우 가변적일 때 많은 시간과 처리 능력을 절약할 수 있음
- 다음은 한 번에 모든 데이터셋에 토큰화 기능을 적용하는 방법임.
map메서드 호출에서batched=True를 사용하므로 함수가 각 요소에 개별적으로 적용되지 않고 데이터셋의 하부집합, 즉 각 배치(batch) 내에 존재하는 모든 요소들에 한꺼번에 적용됩니다. 이 방법은 더 빠른 전처리를 가능하게 함
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
0%| | 0/4 [00:00<?, ?ba/s]
0%| | 0/1 [00:00<?, ?ba/s]
0%| | 0/2 [00:00<?, ?ba/s]
DatasetDict({
train:Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation:Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test:Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
- Datasets 라이브러리는 데이터셋(datasets)에 새로운 필드들을 추가함
- 이 필드들은 전처리 함수에서 반환된 사전의 각 키(
input_ids,token_type_ids,attention_mask)에 해당함 num_proc매개변수를 전달하여map()으로 전처리 기능을 적용할 때 다중 처리(multi-processing)를 사용할 수도 있음.- Tokenizers 라이브러리는 샘플을 더 빠르게 토큰화하기 위해 이미 다중 스레드(multiple threads)를 사용하지만, 이 라이브러리에서 지원하는 “빠른 토크나이저(fast tokenizer)”를 사용하지 않는 경우 전처리 속도가 빨라질 수 있음
- 위의
tokenize_function은input_ids,attention_mask및token_type_ids키가 존재하는 딕셔너리를 반환하므로 이 3 개의 새로운 필드가 데이터셋의 모든 분할(학습, 검증, 평가)에 추가됨 - 전처리 함수가
map()을 적용한 데이터셋의 기존 키들 즉,idx,label등에 대한 새로운 값을 반환한 경우 기존 필드(idx,label,sentence1,sentence2등)를 변경할 수도 있음 - 마지막으로 해야 할 일은 전체 요소들을 배치(batch)로 분리할 때 가장 긴 요소의 길이로 모든 예제를 채우는(padding) 것임
- 이를 동적 패딩(dynamic padding)이라고 함
4. **Dynamic padding**
동적 패딩
- 샘플들을 함께 모아서 지정된 크기의 배치(batch)로 구성하는 역할을 하는 함수를 콜레이트 함수(collate function) 라고 함
- 이 함수는
DataLoader를 빌드(build)할 때 전달할 수 있는 매개변수임 - 기본값은 단순히 샘플들을 PyTorch 텐서로 변환하고 결합하는 함수임
- 만일 대상 샘플들이 리스트, 튜플 혹은 딕셔너리면 재귀적으로 이 작업이 수행됨
- 우리 예제의 경우, 입력값이 모두 동일한 크기(길이)가 아니기 때문에 이 작업이 불가능함
- 지금까지 우리는 일부러 패딩(padding) 작업을 미뤄왔는데 그 이유는 전체 데이터셋이 아닌 개별 배치(batch)에 대해서 별도로 패딩(padding)을 수행하여 과도하게 긴 입력으로 인한 과도한 패딩(padding) 작업을 방지하기 위함임
- 이렇게 하면 학습 속도가 상당히 빨라지지만 TPU에서 학습하는 경우 문제가 발생할 수 있음
- TPU는 추가적인 패딩(padding)이 필요한 경우에도 전체 데이터셋이 고정된 형태를 선호함
- 실제로 이를 수행하려면, 배치(batch)로 분리하려는 데이터셋의 요소 각각에 대해서 정확한 수의 패딩(padding)을 적용할 수 있는 콜레이트 함수(collate function)를 정의해야 함
- 다행히도, Transformers 라이브러리는
DataCollatorWithPadding을 통해 이러한 기능을 제공함 - 이 함수는 토크나이저를 입력으로 받음
- 그 이유는 사용하려는 패딩 토큰(padding token)이 무엇인지와 모델이 입력의 왼쪽 혹은 오른쯕 중 어느 쪽에 패딩(padding)을 수행할지를 파악하기 위함임
- 이 입력 하나면 모든 것이 해결됨
from transformersimport DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
- 이 새로운 함수를 테스트하기 위해 학습집합에서 배치(batch)로 묶을 몇개의 샘플들을 가져오고자 함
- 여기서는 필요하지도 않을 뿐더러 심지어 문자열까지도 포함하는
idx,sentence1및sentence2열을 제거함(문자열로는 텐서를 생성할 수 없음) - 아래에서 배치(batch) 내의 각 요소들의 길이를 살펴볼 예정임
samples = tokenized_datasets["train"][:8]
samples = {k: vfor k, vin samples.items()if knotin ["idx", "sentence1", "sentence2"]}
[len(x)for xin samples["input_ids"]]
[50, 59, 47, 67, 59, 50, 62, 32]
- 당연히, 32에서 67까지 다양한 길이의 샘플을 얻을 수 있음
- 동적 패딩(dynamic padding)은 이 배치(batch) 내의 모든 샘플들이 배치 내부에서 최대 길이인 67 길이로 패딩(padding)되어야 함을 의미함
- 동적 패딩(dynamic padding)이 없으면 모든 샘플들은 전체 데이터셋의 최대 길이 또는 모델이 허용할 수 있는 최대 길이로 채워져야 함
data_collator가 동적으로 배치(batch)를 적절하게 패딩(padding)하는지 다시 확인하고자 함
batch = data_collator(samples)
{k: v.shapefor k, vin batch.items()}
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
- 이제 raw 텍스트에서 모델이 처리할 수 있는 배치(batch) 형태로 변경되었으므로, 이제 미세 조정(fine-tuning)할 준비가 됨
What is Dynamic Padding?

-
동적 패딩이란 무엇인가

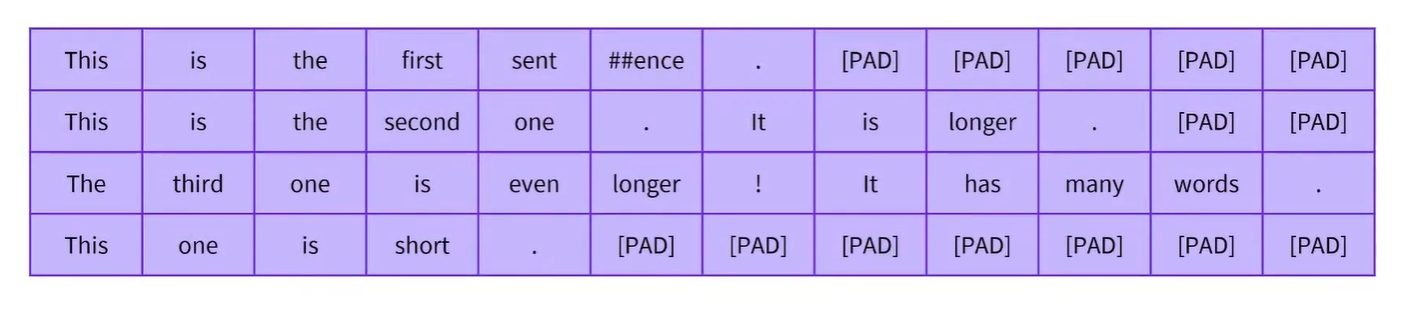
- Batching inputs together 비디오에서 동일한 배치에서 서로 다른 길이의 입력을 그룹화하려면 길이가 모두 같아질때까지 모두 짧은 입력에 패딩 토큰을 추가해야한다는 것을 확인함
- 예를 들어, 가장 긴 문장은 세 번째 문장이고, 같은 길이의 문장 4개를 만들려면 다른 문장에 5,2,7개의 패드 토큰을 추가해야함
- 전체 데이터셋을 처리할 때 적용할 수 있는 다양한 패딩 전략이 있음
데이터셋의 가장 긴 샘플 길이로 채우는 방식


- 가장 확실한 방법은 데이터셋의 모든 요소를 동일한 길이, 즉 가장 긴 샘플의 길이로 채우는 것임
- 그러면 최대 시퀀스 길이에 따라 결정된 동일한 모양을 갖는 배치가 제공됨
- 단점은 짧은 문장으로 구성된 배치에는 궁극적으로 필요하지 않은 모델에 더 많은 계산을 도입하는 많은 패딩 토큰이 있다는 점임
배치별 가장 긴 샘플 길이로 채우는 방식
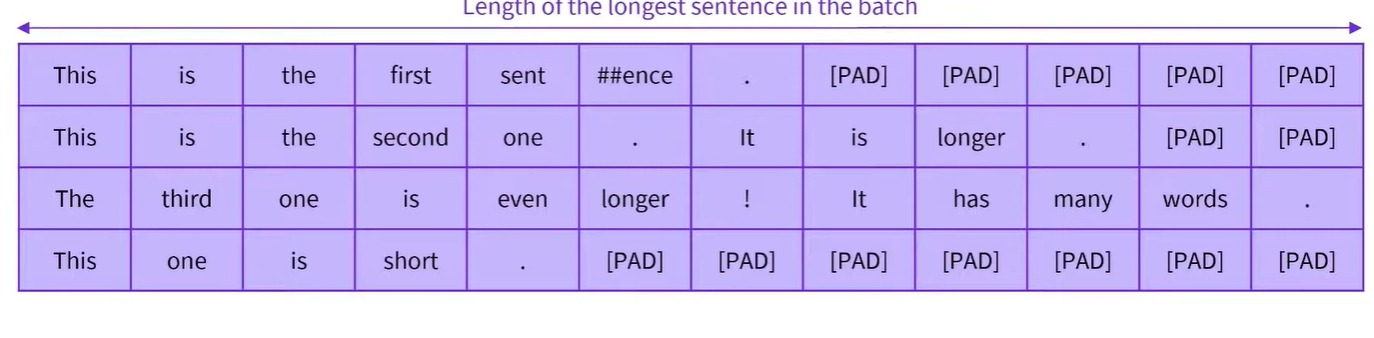

- 이를 방지하기 위한 또 다른 방법은 batch를 진행할 때 batch 처리 내 가장 긴 문장까지의 요소를 채우는 것임
- 이렇게 하면 짧은 입력으로 구성된 배치가 데이터셋에서 가장 긴 문장을 포함하는 배치보다 작아짐
- 이렇게 하면 CPU와 GPU의 속도가 상당히 향상됨
- 단점은 모든 배치의 모양이 다르기 때문에 TPU와 같은 다른 가속기에서는 훈련 속도가 느려짐
적용


- 두 가지를 모두 적용해보자
- 우리는 MRPC 데이터셋을 전처리할 때 고정 패딩을 적용하는 방법을 보았음
- 데이터셋과 토크나이저를 로드한 후 패딩과 truncation을 사용하여 모든 데이터셋에 대한 토큰화를 적용하여 길이가 128인 샘플을 만듦
-
결과적으로 이 데이터셋을 Pytorch DataLoader에 전달하면 배치크기(16) x 128의 배치를 얻음

-
동적 패딩을 적용하려면 패딩을 batch preparation으로 해야하기 때문에 토큰화에서 해당 부분을 제거함

- 모델이 허용하는 최대길이(일반적으로 512)보다 큰 입력이 해당 길이로 잘리도록 잘린 부분을 그대로 둠
- 그런 다음 Datacollator를 사용하여 샘플을 동적으로 채움
- Transformers 라이브러리의 해당 클래스는 배치를 형성하기 전에 필요한 모든 최종 처리를 적용하는 역할을 담당한
-
여기서 DataCollatorWithPadding은 문장 배치 내부의 최대 길이까지 샘플을 채움

- 이를 Pytorch DataLoader에 전달한 다음 생성된 배치의 길이가 이전의 128보다 훨씬 낮아진 것을 볼 수 있음
- Dynamic Batch는 거의 항상 CPU와 GPU에서 더 빠르므로 가능하면 적용해야 함
- 하지만 TPU에서 학습 스크립트를 실행하거나 고정된 모양의 배치가 필요한 경우에는 고정 패딩으로 다시 전환해야 함
DataCollatorWithPadding
https://github.com/huggingface/transformers/blob/v4.33.0/src/transformers/data/data_collator.py#L215
@dataclass
class DataCollatorWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
tokenizer ([`PreTrainedTokenizer`] or [`PreTrainedTokenizerFast`]):
The tokenizer used for encoding the data.
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
- `True` or `'longest'` (default): Pad to the longest sequence in the batch (or no padding if only a single
sequence is provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'`: No padding (i.e., can output a batch with sequences of different lengths).
max_length (`int`, *optional*):
Maximum length of the returned list and optionally padding length (see above).
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
return_tensors (`str`):
The type of Tensor to return. Allowable values are "np", "pt" and "tf".
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
return_tensors: str = "pt"
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
batch = self.tokenizer.pad(
features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
if "label" in batch:
batch["labels"] = batch["label"]
del batch["label"]
if "label_ids" in batch:
batch["labels"] = batch["label_ids"]
del batch["label_ids"]
return batch
Leave a comment