
[Hugging Face][C-2] Models
[Hugging Face][C-2] Models
**Instantiate a Transformers model (PyTorch) with Slyvain**

- Transfomers 모델을 인스턴스화하는 방법은 무엇인가?
- Transformers 라이브러리에서 모델을 만들고 사용하는 방법을 살펴보고자 함
-
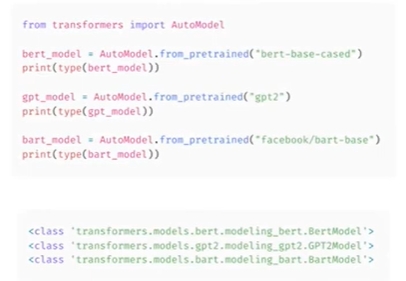
이전에 살펴본 것처럼 AutoModel 클래스를 사용하면 Hugging Face Hub의 모든 체크포인트에서 사전 학습된 모델을 인스턴스화할 수 있음

- 라이브러리에서 모델 클래스를 선택하여 적절한 아키텍처를 인스턴스화하고 그 안에서 사전학습된 모델의 가중치를 로드함
- BERT 체크포인트가 주어지면 결국 BertModel이 되고 GPT-2나 BART도 마찬가지임
- 이 API는 허브의 체크포인트 이름을 사용할 수 있으며, config 파일과 모델 가중치 파일을 다운로드하고 캐시함
-
유효한 구성파일과 모델 가중치 파일이 포함된 로컬 폴더의 경로를 지정할 수도 있음
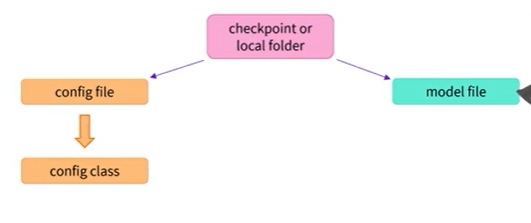
- 사전 학습된 모델을 인스턴스화하기 위해 AutoModel API는 먼저 구성파일을 열어 사용해야하는 구성 클래스를 살펴봄
- 구성클래스는 모델 유형(BERT,GPT,BART etc)에 따라 다름
- 적절한 구성 클래스가 있으면 해당 구성을 인스턴스화할 수 있음
-
모델 생성 방벙르 알기 위한 blueprint임
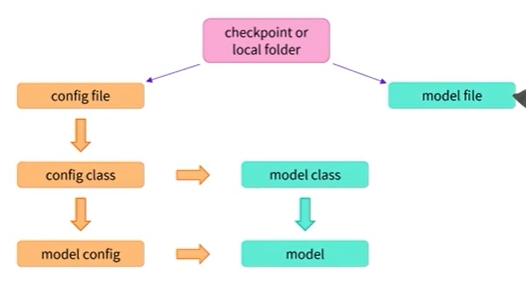
- 또한 이 구성 클래스를 사용하여 로드된 구성과 결합된 적절한 모델 클래스를 찾아 모델을 로드함
-
이 모델은 무작위 가중치로 초기화되었기 때문에 아직 사전 학습된 모델이 아님
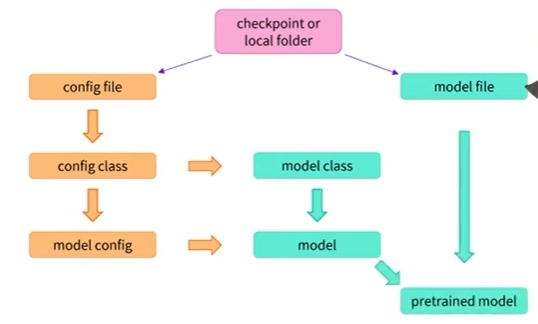
-
마지막 단계는 이 모델 내부의 모델 파일에서 가중치를 로드하는 것임
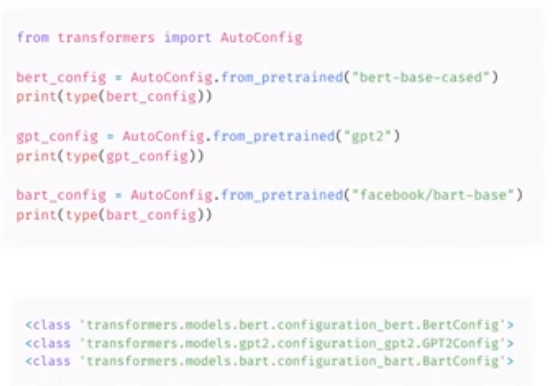
- 모델 체크포인트 또는 구성 폴더가 포함된 폴더에서 구성을 쉽게 로드하려면 AutoConfig 클래스를 사용할 수 있음
-
AutoModel 클래스와 마찬가지로 라이브러리에서 올바른 구성 클래스를 선택함
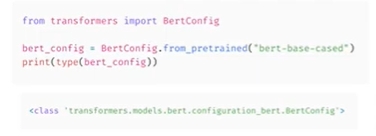
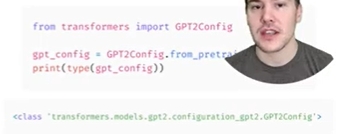
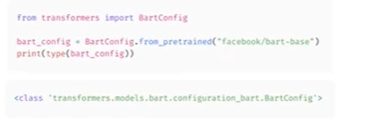
-
체크포인트에 해당하는 특정 클래스를 사용할 수도 있지만 다른 모델을 시도할때마다 코드를 변경해야 함

- 앞서 말했듯이 모델 구성은 모델 아키텍처를 만드는 데 필요한 모든 정보가 포함된 blueprint임
-
예를 들어 bert-base-cased 체크포인트와 연결된 BERT 모델에는 12개 레이어, hidden size 768, vocab size 28,966이 있음

- 체크포인트와 아키텍처가 동일하지만 무작위로 초기화되는 모델을 생성할 수 있음
- 그런 다음 PyTorch 모듈, TensorFlow 모델처럼 처음부터 학습할 수 있음
- 키워드 인수를 사용하여 구성의 일부를 변경할 수도 있음
-
두 번째 코드는 12개가 아닌 10개의 레이어로 무작위로 초기화된 BERT 모델을 인스턴스화함

- 학습되거나 미세 조정된 모델을 저장하는 것은 쉬움
- saved_pretrained 메서드를 사용하면 됨
- 모델은 현재 작업 디렉터리 내의 my-bert-model 폴더에 저장됨
- 그런 다음 from_pretrained 메서드를 사용하여 이 모델을 다시 로드할 수 있음
Models
- 해당 섹션에서는 모델을 생성하고 사용하는 방법을 자세히 살펴보고자 함
- 이를 위해, 우리는 지정된 checkpoint를 바탕으로 모델을 인스턴스화할 때 편리한
AutoModel클래스를 사용할 예정임 AutoModel클래스와 이와 관련된 모든 항목들은 실제로 라이브러리에서 사용할 수 있는 다양한 모델에 대한 wrapper임- 선택한 checkpoint에 적합한 model architecture를 자동으로 추측한 다음, 이 아키텍처로 모델을 인스턴스화할 수 있음
- 사용하려는 모델의 유형을 알고 있다면 해당 아키텍처를 직접 정의하는 클래스를 사용할 수도 있음
- 이 부분이 BERT 모델과 함께 어떻게 작동하는지 살펴보고자 함
**Creating a Transformer**
- BERT 모델을 초기화하기 위해 가장 먼저 해야 할 일은 configuration 객체를 로드하는 것임
from transformers import BertConfig, BertModel
# config(설정)을 만듭니다.
config = BertConfig()
# 해당 config에서 모델을 생성합니다.
model = BertModel(config)
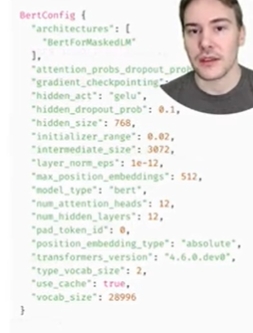
print(config)
# result
BertConfig {
[...]
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}
- 이 configuration 객체에는 모델을 빌드하는데 필요한 많은 속성이 포함되어 있음
- 아직 이 모든 속성들이 담당하는 일들을 살펴보지는 않았지만, 그 중 일부는 이미 알 수도 있음
hidden_size:hidden_states벡터의 크기 정의num_hidden_layers: Transformer 모델의 layers 수를 정의함
**Different loading methods**
- configuration에서 모델을 생성하면 해당 모델을 임의의 값으로 초기화함
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# 모델은 무작위로 초기화됩니다.
- 모델을 먼저 학습을 해야 함
- 수행해야할 task를 위해서 모델을 처음부터(from scratch) 학습할 수도 있지만, 1장에서 보았듯이 이를 위해서는 오랜 실행 시간과 많은 데이터가 필요하기 떄문에 불필요하고 중복되는 노력을 피하기 위해서는 이미 학습된 모델을 공유하고 재사용할 수 있어야 함
- 이미 사전 학습된 Transformer 모델을 로드하는 것은 간단함
from_pretrained()메서드를 사용하여 이 작업을 수행할 수 있음
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")


BertModel을 동일한 기능을 수행하는AutoModel클래스로 대체할 수 있음- 이렇게 하면 checkpoint에 구애받지 않는 코드를 구현할 수 있으므로 지금부터 이 클래스를 사용함
- 이 코드가 특정 체크포인트에서 작동한다면 다른 체크포인트에서도 원활하게 작동해야 함
- 이는 심지어 모델의 architecture가 다르더라도, 변경할 체크포인트가 현재 체크포인트와 유사한 task, 예를 들어, sentiment analysis task로 학습되었다면 변경이 가능해야 함
- 위의 코드 샘플에서는
BertConfig를 사용하지 않고 대신bert-base-cased식별자를 통해 사전 학습된 모델(pretrained model)을 로드함. - 이것은 BERT 개발자가 직접 학습한 모델 체크포인트(model checkpoint)(모델 카드(model card))
- 해당 모델은 체크포인트의 모든 가중치로 초기화됨
- 학습된 task에 대한 추론(inference)에 직접 사용할 수 있으며, 새로운 task에 대해 미세 조정할(fine-tune) 수도 있음
- 처음부터 신규로 학습하지 않고 사전 훈련된 가중치로 학습하면 좋은 결과를 빠르게 얻을 수 있음
- 자동으로 가중치가 다운로드되고 캐시되어(따라서
from_pretrained()메서드를 다시 호출해도 가중치가 다시 다운로드되지 않음) 캐시 폴더에 저장됨 - 기본 캐시 폴더 위치는 ~/.cache/huggingface/transformers
HF_HOME환경 변수를 설정하여 캐시 폴더를 변경할 수 있음- 모델을 로드하는 데 사용되는 식별자(checkpoint 명칭)는 BERT 아키텍처(BERT architecture)와 호환되는 모든 Model Hub 내의 식별자들을 사용할 수 있음
- 사용 가능한 BERT 체크포인트(checkpoint)의 전체 목록은 여기에서 찾을 수 있음
**Saving methods**
- 모델을 저장하는 것은
from_pretrained()메서드와 유사하게save_pretrained()메서드를 사용함
model.save_pretrained("directory_on_my_computer")
- 이는 2가지로 저장됨
ls directory_on_my_computer
config.json pytorch_model.bin
- config.json 파일은 model architecture를 구축하는 데 필요한 다양한 속성들을 볼 수 있음
- 이 파일에는 또한 몇몇 metadata, 즉 해당 checkpoint를 구축한 출처, 체크포인트(checkpoint)를 마지막으로 저장할 때 사용하고 있던 Transformers 버전 등과 같은 정보가 저장되어 있음
- pytorch_model.bin 파일은 state dictionary 라고 부름
- 여기에는 모델의 모든 가중치가 저장되어 있음
- 이 두 파일은 함께 사용됨
- configuration objects는 model architecture를 파악하는데 필요한 반면, 모델 가중치는 모델의 parameters임
**Using a Transformer model for inference**
- 모델을 로드하고 저장하는 방법을 알았으므로 모델을 사용하여 몇 가지 예측을 해보고자 함.
- Transformer 모델은 토크나이저가 생성하는 숫자만 처리할 수 있음
- 그러나 토크나이저에 대해 논의하기 전에 모델이 허용하는 입력을 살펴보고자 함
- 두 개의 시퀀스가 있다고 가정해 보겠습니다:
sequences = ["Hello!", "Cool.", "Nice!"]
- 토크나이저는 이를 일반적으로 input IDs 라고 하는 어휘 인덱스로 변환함
- 이제 각 시퀀스는 숫자의 리스트(list)임
- 결과 출력은 다음과 같음
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]
- 이는 인코딩된 시퀀스의 리스트임
- 파이썬 중 리스트(list of list)입니다.
- 텐서(tensor)는 직사각형(rectangular) 모양(shape)만 허용함
encoded_sequences는 이미 “배열(array)” 형태의 직사각형(rectangular) 모양이므로 텐서로 변환하는 것은 쉬움
import torch
model_inputs = torch.tensor(encoded_sequences)
**Using the tensors as inputs to the model**
- 모델과 함께 텐서를 사용하는 것은 간단함
- 입력을 매개변수로 지정하여 모델을 호출하기만 하면 됨
output = model(model_inputs)
- 모델은 다양한 추가적인 매개변수를 입력받을 수 있지만 여기서는 input IDs만 있으면 됨
- 다른 매개변수가 어떤 것인지, 언제 필요한지에 대해서는 나중에 설명하겠지만 먼저 Transformer 모델이 이해할 수 있는 입력(inputs)을 구성할 수 있는 토크나이저(tokenizer)를 자세히 살펴볼 필요가 있음
Leave a comment