
[Hugging Face][C-2] Tokenizers
Overview
Tokenizers Overview with Lysandre

-
토크나이저에 대해서 살펴보고자 함

- 자연어처리에서 처리하는 대부분의 데이터는 raw text로 구성됨
-
그러나 기계 학습 모델은 raw 형식의 텍스트를 읽고 이해할 수 없으며 숫자로만 작업할 수 있음
-
토크나이저의 목적은 텍스트를 숫자로 변환하는 것임

- 이 변환에는 여러가지 접근 방식이 있으며, 목표는 가장 의미있는 표현을 찾는 것임
-
3가지의 고유한 토큰화 알고리즘을 살펴보고자 함

-
일대일 비교를 하므로 1) Word-based (단어 기반) 2) Character-based (문자기반) 3) Subword-based(하위 단어 기반) 순서로 동영상을 보는 것이 좋음
- 토크나이저는 NLP 파이프라인의 핵심 구성 요소 중 하나임
- 토크나이저는 1가지 목적을 가지고 있음
- 입력된 텍스트를 모델에서 처리할 수 있는 데이터로 변환하는 것임
- 모델은 숫자만 처리할 수 있으므로, 토크나이저는 텍스트 입력을 숫자 데이터로 변환해야 함
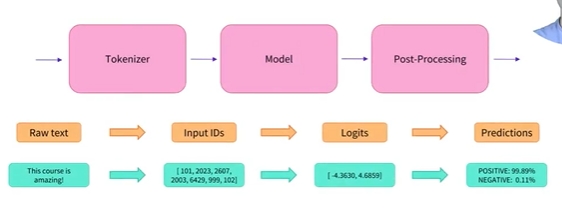
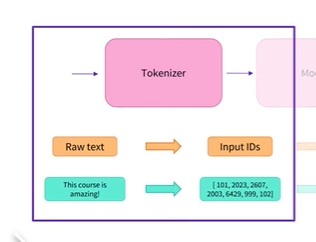
- 이 섹션에서는 tokenization pipeline에서 정확히 어떤 일이 발생하는지 살펴보고자 함
- NLP 작업에서 일반적으로 처리되는 데이터는 raw text임
- 다음은 원시 텍스트의 예시임
Jim Henson wasa puppeteer
- 그러나 모델은 숫자만 처리할 수 있으므로 raw text를 숫자로 변환하는 방법을 찾아야 함
- 이것이 토크나이저가 하는 일이며, 이를 위해서 다양한 방법이 존재함
- 토크나이저의 목표는 가장 의미있는 표현(meaningful representation), 즉 모델에 가장 적합하면서 최대한 간결한 표현을 찾는 것임
- 토큰분리 알고리즘의 몇 가지 예를 살펴보고자 함
**Word-based Tokenizers**
**Word-based Tokenizers with Lysandre**

-
단어 기반 토큰화에 대해 살펴보고자 함

-
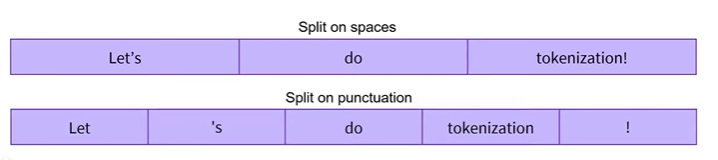
단어 기반 토큰화는 공백이나 구두점과 같은 기타 특정 규칙을 기준으로 raw text를 단어로 분할하는 아이디어임
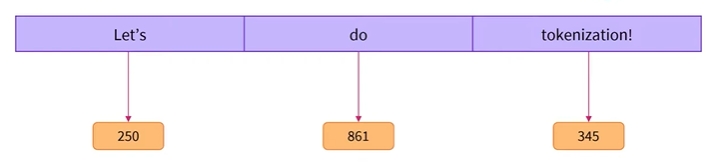
- 알고리즘에서 각 단어에는 특정 숫자, 즉 ID가 부여됨
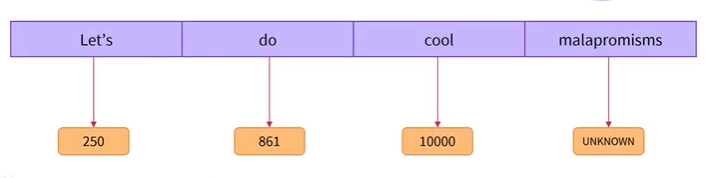
- 이 예에서 ‘Let’s’의 ID는 250, do의 ID는 861, 느낌 표 뒤에 오는 토큰화의 ID는 345임
- 모델에 전체 단어를 기반으로 한 표현이 있음
-
한 단어에는 문장 안에 많은 문맥 및 의미 정보가 포함되어 있기 때문에 단일 숫자에 담긴 정보의 비중이 높음

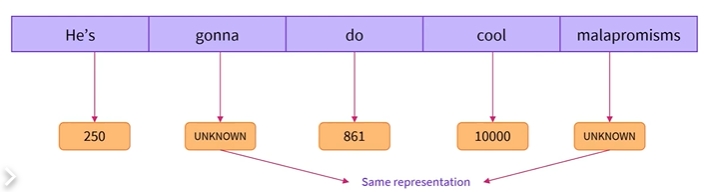
- 그러나 이 방법에는 한계가 있는데 예를 들어 개(do)라는 단어와 개(dogs)라는 단어는 매우 유사하며 의미도 가까움
- 그러나 단어 기반 토큰화는 이 두 단어에 완전히 다른 ID를 부여하므로 모델은 이 두 단어에 대해 서로 다른 의미를 학습하게 됨
-
모델이 단어를 실제로 서로 관련되어 있고, 개는 dog라는 단어의 복수형이라는 것을 이해하길 원함

- 이 접근 방식의 또 다른 문제는 한 언어에 다양한 단어가 있다는 것임
-
모델이 해당 언어의 가능한 모든 문장을 이해하도록 하려면 각 단어에 대한 ID가 필요하며, 어휘 크기라고도 알려진 총 단어의 수는 빠르게 커질 수 있음

-
이는 각 ID가 단어의 의미를 나타내는 큰 벡터에 매핑되고, 어휘 크기가 클 때, 이러한 매핑을 추적하려면 엄청난 수의 가중치가 필요하기 때문에 문제가 됨

- 모델을 간결하게 유지하려면 토크나이저가 반드시 필요하지 않은 특정 단어를 무시하도록 선택할 수 있음
-
예를 들어, 텍스트에 대해 토크나이저를 훈련할 때 해당 언어의 모든 단어를 사용하는 대신 해당 텍스트에서 가장 자주 사용되는 10,000개의 단어를 사용하여 기본 어휘를 생성할 수 있음
-
토크나이저는 10,000개의 단어를 숫자로 변환하는 방법을 알지만 다른 단어는 ‘어휘에 없는 단어’ 또는 ‘알 수 없는 단어’로 변환됨
-
이는 문제가 될 수 있는데, 모델은 자신이 모르는 모든 단어에 대해 동일한 표현을 갖게 되며 이로 인해 많은 정보가 손실됨
- 가장 먼저 생각할 수 있는 tokenization 형태는 단어기반 (word-based)임
- 일반적으로 몇 가지 규칙만 가지고도 설정 및 사용이 매우 쉽고, 괜찮은 결과를 얻을 수 있음
-
예를 들어, 아래 그림에서의 토큰화 과정은 원시 텍스트를 단어로 나누고 각각에 대한 숫자 표현을 찾는 것임
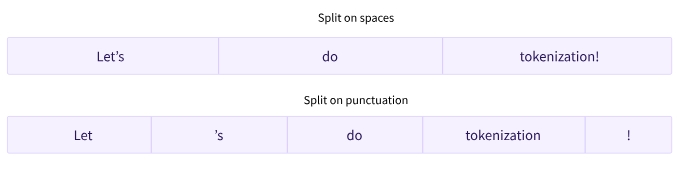
- 텍스트를 분할하는 방법에는 여러 가지가 있음
- 예를 들어, Python의
split()함수를 적용하여 공백을 기준으로 텍스트를 단어로 토큰화할 수 있음
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
['Jim', 'Henson', 'was', 'a', 'puppeteer']
- 구두점에 대한 추가 규칙이 있는 단어기반 토크나이저(word-based tokenization)의 변형도 있음
- 이러한 토크나이저를 사용하여 말뭉치에 존재하는 독립적인 토큰들의 총합으로 구성되는 꽤 큰 규모의 vocabulary들을 얻을 수 있음
- 각 단어에는 0에서부터 시작하여 어휘집(vocabulary) 크기(개수) 사이의 ID(식별자)가 할당됨
- 모델은 이러한 ID를 사용하여 각 단어를 식별함
- 단어기반 토크나이저로 특정 언어를 완전히 커버하려면, 해당 언어의 모든 단어에 대한 식별자가 필요하고, 이는 엄청난 양의 토큰을 생성함
- 예를 들어, 영어에는 500,000개 이상의 단어가 있으므로 개별 단어에 대한 input ID(입력 식별자)로의 매핑을 구성하기 위해서 그만큼의 식별자가 있게 됨
- 게다가, “dog”와 같은 단어는 “dogs”와 같은 단어와 다르게 표현되며, 모델은 처음에는 “dog”와 “dogs”가 유사한 단어들인지 파악하기 어려움
- 따라서, 두 단어를 관련이 없는 것으로 인식함
- 이는 “run”과 “running”과 같은 다른 유사한 단어들도 마찬가지임
- 마지막으로, 어휘집(vocabulary)에 없는 단어를 표현하기 위해 사용자 정의 토큰이 필요합니다. 이는 “unknown” 토큰으로 알려져 있으며, 종종 “[UNK]” 또는 ““로 표시됩니다. 토크나이저가 이러한 “unknown” 토큰을 많이 생성한다는 것은 토크나이저가 해당 단어의 합당한 표현(sensible representation)을 찾을 수 없고, 그 과정에서 정보를 잃어버린다는 뜻임
- 어휘집(vocabulary)을 만들 때, 토크나이저가 이러한 “unknown” 토큰들을 최대한 적게 출력하게끔 하는 것이 목표가 되어야 함
- “Unknown” 토큰의 양을 줄이는 한 가지 방법은 문자기반 (character-based) 토크나이저를 사용하여 한 단계 더 깊이 들어가는 것임
**Character-based Tokenizers**
**Character-based Tokenizers with Lysandre**

-
문자 기반 토큰화(character-based Tokenizers)에 대해 알아보기 전에 이러한 유형의 토큰화가 필요한 이유를 보려면 단어 기반 토큰화의 단점을 이해해야 함

- 이제 텍스트를 단어가 아닌 개별 문자로 분할함
- 일반적으로 언어에는 다양한 단어가 있지만 문자 수는 적음
-
예를 들어, 약 170,000개의 서로 단어가 있는 영어의 경우, 모든 단어를 포함하려면 매우 큰 어휘가 필요함


- 문자 기반 어휘를 사용하면 256자만으로 충분함
- 중국어와 같이 다양한 문자를 사용하는 언어에도 최대 20,000개의 문자와 375,000개 이상의 단어로 구성된 사전이 있음
-
문자 기반 어휘를 사용하면 다른 방법으로 사용하는 단어 기반 토큰화 사전보다 더 적은 양의 토큰을 사용할 수 있음
- 또한 이러한 어휘는 단어 기반 어휘보다 더 완전함
- 어휘에는 언어에 사용되는 모든 문자가 포함되어 있으므로 토크나이저 훈련 중에 표시되지 않는 단어도 토큰화될 수 있으므로 어휘 외 토큰의 빈도는 줄어듦
- 여기에는 철자가 틀린 단어를 즉시 알 수 없는 단어로 삭제하는 대신 올바르게 토큰화하는 기능이 포함됨
- 하지만 이 알고리즘도 완벽하지는 않음
- 직관적으로 문자는 단어가 보유하는 것만큼 개별적으로 많은 정보를 보유하지 않음
- 예를 들어 Let’s는 I보다 더 많은 정보를 담고 있음
- 물론 표의 문자 기반 언어와 같은 일부 언어에는 단일 문자로 많은 정보가 포함되어 있기 때문에 이는 모든 언어에 해당되는 것은 아니지만 로마 기반 언어와 같은 다른 언어의 경우, 모델은 한 번에 여러 토큰을 이해해야 함
-
한 단어에 담긴 정보를 얻어야 함


- 이로 인해 문자 기반 토크나이저에 또 다른 문제가 발생하는데 해당 시퀀스는 모델에서 처리할 매우 많은 양의 토큰으로 변환됨
- 이는 모델이 전달할 컨텍스트의 크기에 영향을 미칠 수 있으며, 모델의 입력으로 사용할 수 있는 텍스트의 크기가 줄어듦
-
이 토큰화는 몇 가지 이슈가 있지만 과거에는 매우 좋은 결과를 보였으며, 단어 기반 알고리즘에서 발생한 일부 문제를 해결하므로 새로운 문제 접근할 때 고려해야 함
- 문자기반 토크나이저는 텍스트를 단어(words)가 아닌 문자(characters)로 나눔
- 두가지 장점이 있음
- 어휘집(vocabulary)의 크기가 매우 작음
- 모든 단어들이 문자를 가지고 만들어질 수 있기 때문에, out-of-vocabulary (OOV, unknown) 토큰이 훨씬 적음
- 그러나 여기에서도 공백과 구두점에 관한 몇 가지 이슈가 발생함

- 이 방식 역시 완벽하지 않음
- 분리된 토큰 표현 자체가 단어가 아닌 문자 기반이므로 직관적으로 볼 때 각 토큰의 의미 파악이 어려움
- 그러나 이 또한 언어에 따라 다름. 예를 들어, 중국어에서 각 문자(한자)는 라틴(Latin) 언어의 문자보다 더 많은 정보를 전달함
- 고려해야 할 또 다른 사항은 모델에서 처리할 매우 많은 양의 토큰이 발생하게 된다는 것임
- 단어기반 토크나이저를 사용하면 각 단어는 하나의 단일 토큰이지만, 문자로 변환하면 10개 이상의 토큰으로 쉽게 변환될 수 있음
- 위 두가지 방식의 장점을 최대한 활용하기 위해 이를 결합한 세 번째 기법인 subword tokenization(하위단어 토큰화)임
Subword **Tokenizers**
Subword **Tokenizers with Lysandre**

-
하위 단어 기반 토큰화에 대해 살펴보고자 함
-
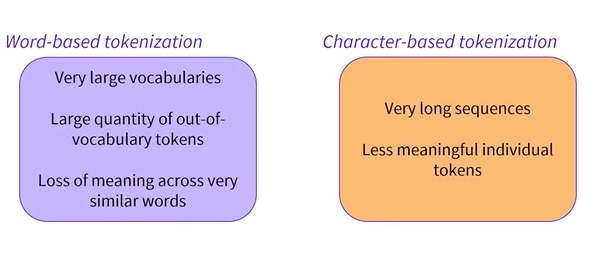
하위 단어 기반 토큰화는 문자 기반 토큰화와 단어 기반 토큰화 알고리즘의 중간임
1) 단어 기반 토크나이저
- 매우 큰 어휘, 어휘에 없는 대량의 토큰, 매우 유사한 단어의 의미 손실
2) 문자 기반 토크나이저
- 매우 긴 시퀀스, 의미가 없는 개별 토큰
1)2)의 중간 지점을 찾는 것임

- 이러한 알고리즘은 다음 원칙을 따름
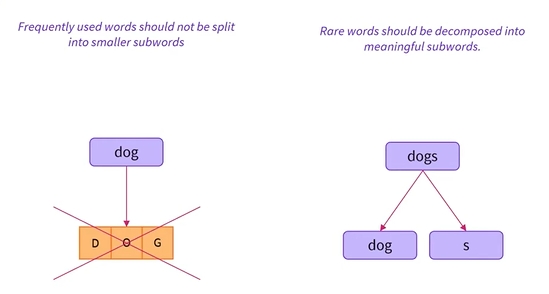
- 자주 사용되는 단어는 작은 단어로 분할되어서는 안 되지만, 희귀한 단어는 의미있는 하위 단어로 분해되어야 함
-
예를 들어, dog라는 단어가 있다고 할때, 토크나이저가 dog라는 단어에 대해 d,o,g 문자로 분할하는 대신 단일 ID를 갖도록 하려고 함
-
그러나 개라는 단어를 접할 때 우리는 토크나이저가 이 단어가 여전히 개라는 단어이며, 원래 개념을 유지하면서 의미가 약간 변경되면서 s가 추가된다는 점을 이해하기를 원함
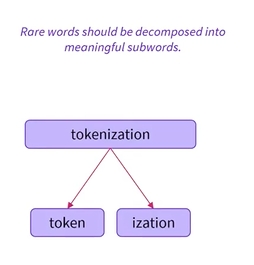
- 또 다른 예로는 의미있는 하위 단어로 분할될 수 있는 토큰화와 같은 복잡한 단어임
- 단어의 어근은 ‘토큰’이며, ‘화’는 어근을 완성하여 약간 다른 의미를 부여함
- ‘토큰’을 root of the word(start라는 label) 인지
-
‘화’를 추가정보로 인지(completion이라는 label)
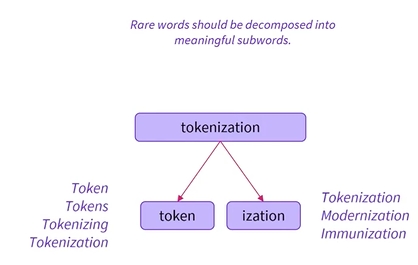
- 결과적으로 모델은 이제 다양한 상황에서 토큰을 이해할 수 있게 됨
- words를 token, tokens, tokenizing, tokenization이라는 단어가 서로 연결되어 있고, 비슷한 의미를 가지고 있다는 것을 이해하게 될 것임
-
또한, 동일한 접미사를 갖는 tokenization, modernization, immunization이 아마도 동일한 구문 상황에서 사용된다는 점을 이해할 것임
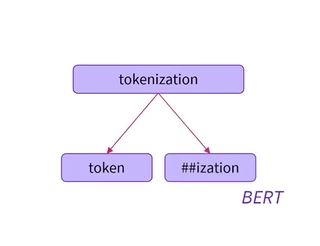
- 하위 단어 기반 토크나이저에는 일반적으로 어떤 토큰이 단어의 시작인지, 어떤 토큰이 단어의 시작을 완료하는지 식별하는 방법이 있음
- 토큰은 단어의 시작임
- 단어 완성으로서의 ‘##화’
- 여기서 ## 접두사는 ization이 단어의 시작이 아닌 단어의 일부임을 나타냄
- ‘##’은 WordPiece 알고리즘을 기반으로 하는 BERT 토크나이저에서 가져옴
-
다른 토크나이저는 다른 접두사를 사용하는데, 여기에 표시된 것과 같은 단어의 일부를 나타내거나 대신 단어의 시작을 나타내기 위해 배치할 수 있음
- 하위 단어 토큰화에 사용할 수 있는 다양한 알고리즘이 있으며, 오늘날 영어로 최점단 결과를 얻는 대부분의 모델은 일종의 하위 단어 토큰화 알고리즘을 사용함
- 이러한 접근 방식은 다양한 단어에 걸쳐 정보를 공유하고 접두사와 접미사를 그 자체로 이해하는 기능을 가짐으로써 어휘 크기를 줄이는데 도움이 됨
-
단어를 구성하는 유사한 토큰을 인식하여 매우 유사한 단어 전체에서 의미를 유지함
- 하위 단어 토큰화(subword tokenization) 알고리즘은 빈번하게 사용하는 단어(frequently used words)는 더 작은 하위단어(subword)로 분할하지 않고, 희귀 단어(rare words)를 의미있는 하위 단어(meaningful subwords)로 분할해야 한다는 원칙에 기반함
- 예를 들어, “annoyingly”는 희귀 단어로 간주될 수 있으며, “annoying”와 “ly”로 분해될 수 있습니다. 이들은 둘 다 독립적인 하위단어(standalone subwords)로 더 자주 출현할 가능성이 높으며 동시에 “annoyingly”의 의미는 “annoying”와 “ly”의 합성 의미(composite meaning)로 유지됨
-
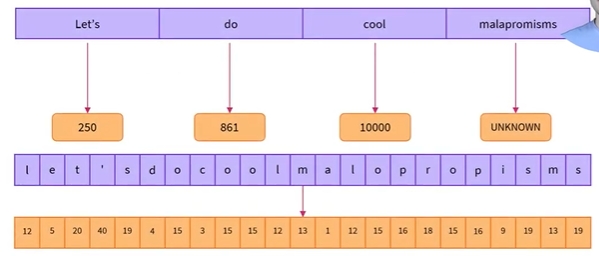
다음은 하위 단어 토큰화(subword tokenization) 알고리즘이 “Let’s do tokenization!” 시퀀스를 토큰화하는 방법을 보여주는 예임

- 위 그림에서의 하위 단어들(subwords)은 충분한 양의 의미 정보(semantic meaning)을 제공하고 있음
- 예를 들어, 위의 예에서 “tokenization”는 “token”과 “iztion”으로 분리됨. 두 개의 토큰은 각각이 의미 정보(semantic meaning)을 가지면서도 공간 효율적(space-efficient)임. 즉, 길이가 긴 한 단어를 표현하기 위해서 단 두 개의 토큰만 필요함. 이를 통해 우리는 규모가 작은, 다시 말해서, 구성 어휘가 많지 않은 어휘집(vocabulary)으로도 충분히 많은 수의 토큰들을 표현할 수 있고, “unknown” 토큰이 거의 없음
- 이 방식은 하위 단어(subwords)를 연결하여 길이가 긴 복잡한 단어를 임의로 만들 수 있는 터키어(Turkish)와 같은 교착 언어(agglutinative languages)에서 특히 유용함
세부 기법들
- 하위 단어 토큰화와 관련된 더 많은 기법들이 있음
- 몇 가지 예를 들면 다음과 같습니다:
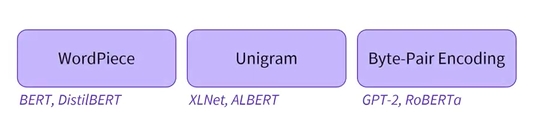
- Byte-level BPE (GPT-2에 사용됨)
- WordPiece (BERT에 사용됨)
- SentencePiece, Unigram (몇몇 다국어 모델에 사용됨)
Loading and Saving
- 토크나이저를 로드하고 저장하는 것은 모델을 로드하고 저장할 때와 같이,
from_pretrained()및save_pretrained()메서드(method)를 그대로 사용함. - 이들 메서드(method)들은 토크나이저(모델의 아키텍처와 약간 비슷함)와 어휘집(vocabulary, 모델의 가중치(weights)와 비슷함)에서 사용하는 알고리즘을 로드하거나 저장함
- BERT와 동일한 체크포인트(checkpoint)로 학습된 BERT 토크나이저를 로드하는 것은
BertTokenizer클래스를 사용한다는 점을 제외하고는 모델을 로드하는 것과 동일한 방식으로 수행됨
from transformers import BertTokenizer
tokenizer = **BertTokenizer**.from_pretrained("bert-base-cased")
AutoModel클래스와 유사하게AutoTokenizer클래스는 라이브러리에서 체크포인트 이름에 해당하는 토크나이저 클래스를 가져옴- 라이브러리 내의 다른 모든 체크포인트와 함께 직접 사용할 수 있음
from transformers import AutoTokenizer
tokenizer = **AutoTokenizer**.from_pretrained("bert-base-cased")
- 이제 위에서처럼 동일하게 토크나이저를 사용할 수 있음
tokenizer("Using a Transformer network is simple")
{'input_ids': [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
- 토크나이저를 저장하는 것은 모델을 저장하는 것과 동일함
tokenizer.save_pretrained("saving_folder")
('saving_folder/tokenizer_config.json',
'saving_folder/special_tokens_map.json',
'saving_folder/vocab.txt',
'saving_folder/added_tokens.json',
'saving_folder/tokenizer.json')
- 위 토크나이저 출력 결과 먼저
input_ids가 어떻게 생성되는지 살펴보고자 함 - 이를 위해서는 토크나이저의 중간 메서드(intermediate methods)를 살펴봐야 함
Encoding
Encoding (The Tokenization Pipeline with Sylvain)


- 토크나이저 파이프라인에 대해 살펴보고자 함
- 이 코드를 실행할 때와 같이 토크나이저가 raw text를 Transformer 모델이 이해할 수 있는 숫자로 변환하는 방법을 살펴보고자 함
-
다음은 토크나이저 개체 내부에서 발생하는 일에 대한 간략한 개요임
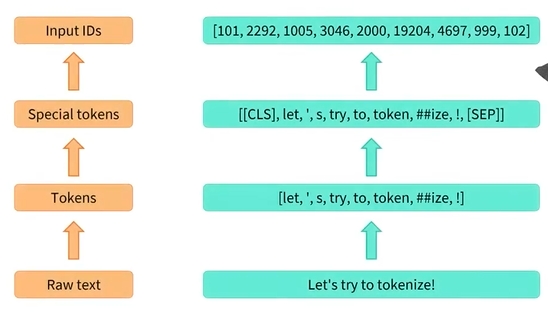
- 먼저 텍스트는 단어, 단어의 일부 또는 구두점 기호인 토큰으로 분할됨
- 그런 다음 토크나이저는 잠재적인 특수 토큰을 추가하고 토크나이저의 어휘에 정의된 대로 각 토큰을 고유한 ID로 변환함
-
실제로 순서는 이렇게 발생하지 않지만 이렇게 보는 것이 무슨 일이 일어나는지 이해하기 좋음

토큰화 파이프라인의 첫번째 단계
- 첫 번째 단계는 토큰화 방법을 사용하여 입력 텍스트를 토큰으로 분할 하는 것
- 이를 위해 토크나이저는 먼저 모든 단어를 소문자로 바꾸는 것과 같은 일부 작업을 수행한 다음 규칙 집합에 따라 결과를 작은 텍스트 덩어리로 분할할 수 있음
- 대부분의 Transformers 모델은 하위 단어 토큰화 알고리즘을 사용함
- 즉, 여기에서 토큰화하는 것과 같이 주어진 단어 하나가 여러 토큰으로 분할될 수 있음을 의미함
- ‘##ize’ : ize 앞에 보이는 ##접두사는 이 토큰이 단어의 시작이 아님을 나타내기 위해 BERT에서 사용하는 규칙임
-
그러나 다른 토크나이저는 다른 규칙을 사용할 수 있음

- 예를 들어 ALBERT 토크나이저는 앞에 공백이 있는 모든 토큰 앞에 긴 밑줄을 추가함
- 이는 문장 토크나이저에서 사용하는 규칙임
토큰화 파이프라인의 두번째 단계

- 토크나이저의 어휘에 정의된 대로 해당 토큰을 해당 ID에 매핑하는 것
- 이것이 바로 from_pretrained 메소드를 사용하여 토크나이저를 인스턴스화할 때 파일을 다운로드해야 하는 이유임
- 모델이 사전 학습되었을 때와 동일한 매핑을 사용해야 함
- 이를 위해 Convert_tokesn_to_ids 메소드를 사용함
- 첫번째 슬라이드와 완전한 동일한 결과가 없음
-
첫번쨰 결과를 상기하면 아래와 같은데

-
처음에는 숫자가 있었고, 끝 부분에는 누락된 숫자가 있었는데 이게 special token임

-
special token은 어휘에서 해당 토큰의 색인을 알고 적절한 숫자를 추가하는 prepare_for_model 메소드에 의해 추가됨

- 토크나이저 객체의 출력에 대한 디코드 메소드를 사용하여 특수토큰(더 일반적으로는 토크나이저가 텍스트를 어떻게 변경했는지)을 볼 수 있음
- 단어 시작/단어 부분에 대한 접두어의 경우, 이러한 특수 토큰은 사용 중인 토크나이저에 따라 다름

-
BERT 토크나이저는 [CLS] 및 [SEP]를 사용하지만 roberta 토크나이저는 html-like anchors
and를 사용함
- 이제 토크나이저의 작동 방식을 알았으므로 모든 intermediaries methods를 잊어버리고, 입력 텍스트에서 이를 호출하기만 하면 된다는 점을 기억하면 됨
- 입력에는 입력ID가 포함되어있지 않음
- attention mask가 궁금하면 Batch inputs together 시청
- 토큰 유형 ID에 대해 알아보려면 ‘process pairs of sentences’ 시청
Encoding
- 텍스트를 숫자로 변환하는(translating text to numbers) 과정을 인코딩(encoding) 이라고 함
- 인코딩(encoding)은 토큰화와 입력 식별자(input IDs)로의 변환이라는 2단계 프로세스로 수행됨
**<첫 번째="" 단계="">**
- 텍스트를 토큰(tokens) 이라고 부르는 단어(또는 단어의 일부, 구두점 기호 등)로 분리하는 것임
- 다양한 토큰화 방법들이 존재하고 각 모델들이 사전학습될 때 사용한 토큰화 방법이 다양하기 때문에, 본인이 사용하고자 하는 모델의 이름을 이용하여 토크나이저도 인스턴스화(instantiate)해야 함
- 그래야 해당 모델에서 사용한 토크나이저를 동일하게 사용할 수 있음
**<두 번째="" 단계="">**
- 두 번째 단계는 토큰화 결과인 토큰들을 숫자로 변환하여 텐서(tensor)를 만들고 이를 모델에 입력할 수 있도록 하는 것
- 이를 위해 토크나이저는
from_pretrained()메서드로 인스턴스화할 때 다운로드되는 파일 중의 하나로 vocabulary 를 포함하고 있음 -
여기서도, 모델이 사전학습될 때 사용한 것과 동일한 어휘집(vocabulary)을 사용해야 함
- 위 두 단계를 개별적으로 살펴보고자 함
- 토큰화 파이프라인(tokenization pipeline) 전체 과정에서 내부적으로 호출되는 몇가지 메소드들을 실행하여 중간 단계의 결과물들을 출력할 예정
- 실제로는 입력에 대해서 토크나이저를 한번에 호출하는 것이 일반적임
**Tokenization**
- 토큰화 프로세스는 토크나이저의
tokenize()메서드에 의해 수행됨
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
['Using', 'a', 'Trans', '##former', 'network', 'is', 'simple']
- 이 메서드의 출력은 문자열 또는 토큰들의 리스트임
- 위에서 보듯이 여기서 실행한 토크나이저는 하위 단어 토크나이저(subword tokenization)임
- 해당 어휘집(vocabulary)에 존재하는 토큰들을 얻을 수 있을 때까지 단어를 분할함
Transformer는Trans와##former라는 두 개의 토큰으로 나뉨- 이들 토큰들은 모두 어휘집(vocabulary)에 존재하는 토큰임
**From tokens to input IDs**
- 이후 각 토큰들의 입력 식별자(input IDs)로의 변환은
convert_tokens_to_ids()메서드에 의해 처리됨
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
[7993, 170, 13809, 23763, 2443, 1110, 3014]
- 위 출력은 일단 적절한 프레임워크 텐서(framework tensor)로 변환되면, 이 장의 앞부분에서 본 것처럼, 모델에 대한 입력으로 사용할 수 있음
Decoding
- 디코딩(decoding)은 반대 방향으로 진행됨
- 변환된 입력 식별자(input IDs)를 이용해서 어휘집(vocabulary)에서 해당 문자열을 찾음
- 이것은 다음과 같이
decode()메서드를 사용하여 수행할 수 있음
decoded_string = tokenizer.decode([7993, 170, 13809, 23763, 2443, 1110, 3014])
print(decoded_string)
Using a Transformer network is simple
decode()메서드는 인덱스를 다시 토큰으로 변환할 뿐만 아니라 하위 단어(subword)로 분할된 토큰을 병합하여, 읽을 수 있는 원본 문장을 도출함- 이 동작은 새로운 텍스트를 생성하는 모델, 다시 말해서, 프롬프트(prompt)에서의 텍스트 생성, 번역(translation), 요약(summarization) 등과 같은 시퀀스-투-시퀀스(sequence-to-sequence) 문제 등을 다룰 때 매우 유용함
- 지금까지, 토크나이저가 수행하는 세부적인 작업들 즉, 토큰화(tokenization), 식별자(ID)로 변환(conversion to IDs), 식별자(ID)를 문자열로 다시 변환(converting IDs back to string) 작업들을 파악함.
- 다음 섹션에서는 위 방법들의 한계를 알아보고 이를 극복하는 방법을 살펴보고자 함
Leave a comment