
[Hugging Face][C-2] Behind the pipeline
What happens inside the Pipeline Fuction? with Sylvain

- 파이프라인 기능 내부에서 어떻게 작동하는가
-
Transformers 라이브러리의 파이프라인 기능을 사용할 떄 실제로 어떤 일이 발생하는지 살펴보고자 함
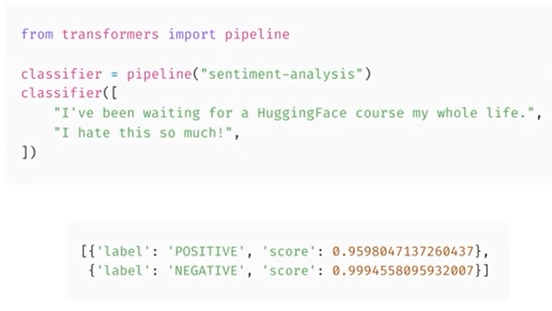
- sentimental analysis에서 다음 두 문장에서 각각의 점수와 함께 긍정적인 라벨로 어떻게 이동했는지 살펴보고자 함
-
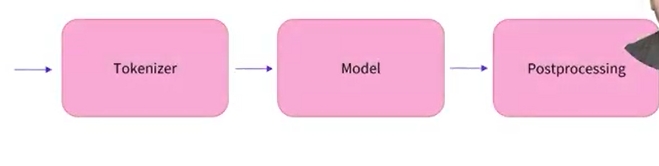
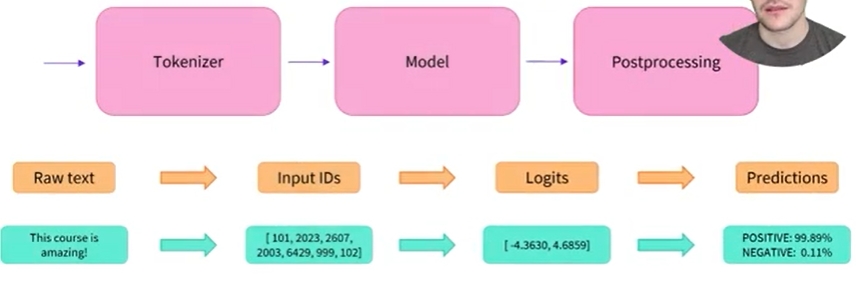
파이프라인 프레젠테이션에서 살펴본 것처럼 파이프라인에는 세 가지 단계가 있음
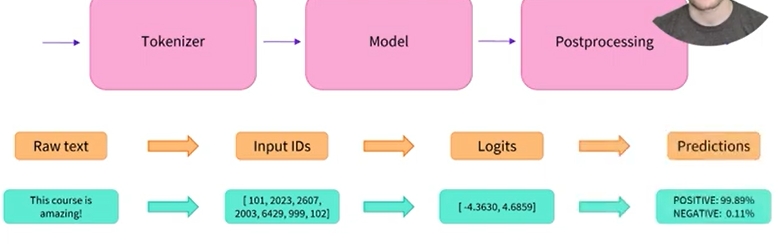
1) 먼저 토크나이저를 사용하여 raw text를 모델이 이해할 수 있는 숫자로 변환함
2) 그런 다음 해당 숫자는 모델을 통과하여 logit을 출력함
3) 마지막으로 사후 처리 단계에서는 해당 logit을 라벨과 점수로 변환함
- 각 단계를 자세히 살펴보고자 함
- 첫 번째 단계인 토큰화부터 시작하여 Transformers 라이브러리를 사용하여 이를 복제하는 방법을 살펴보고자 함
1. Tokenizer
-
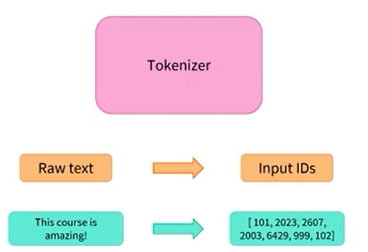
Tokenizer 프로세스에는 여러 단계가 있음
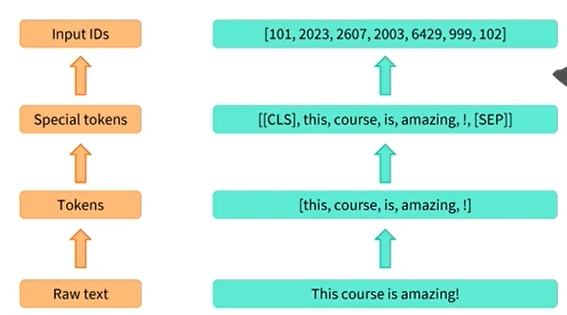
1) 먼저, text는 token이라는 작은 덩어리로 분할됨
단어, 단어의 일부 또는 구두점 기호일 수 있음
2) Tokenizer 에는 몇 가지 special tokens이 있음
모델은 분류를 위해 문장 시작 부분에 CLS 토큰이 있고, 문장 끝 부분에 SEP 토큰이 있을 것으로 예상함
3) 마지막으로 Tokenizer는 각 토큰을 사전 학습된 모델의 vocabulary에 있는 unique ID와 매칭시킴
이러한 Tokenizer를 로드하기 위해 Transformers 라이브러리는 AutoTokenizer API를 제공함
Tokenizer 코드
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
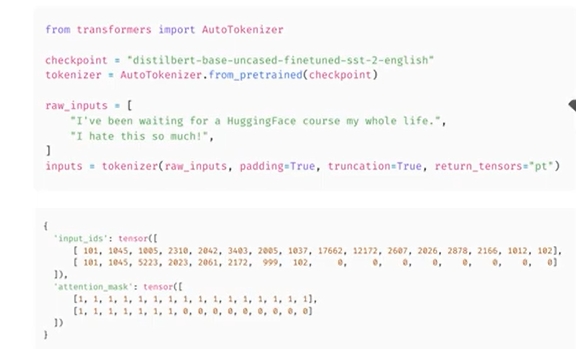
- 이 클래스에서 가장 중요한 method는 from_pretrained로 지정된 체크포인트와 관련된 구성 및 어휘를 다운로드하고 캐시함
- 여기서 sentiment analysis 파이프라인에 기본적으로 사용되는 체크포인트는 distillbert base uncased Fintuned sst2 english임
- 해당 체크포인트와 연결된 Tokenizer를 인스턴스화한 다음 2무장을 제공함
1) padding = True:
- 두 문장의 크기가 동일하지 않기 때문에 배열을 만들려면 가장 짧은 문장을 채움
2) truncation = True:
- 모델이 처리할 수 있는 최대 길이보다 긴 문장은 잘림
3) return_tensors=”pt” :
- return_tensors=”pt”
- Tokenizer에게 Pytorch 텐서를 반환하도록 함


- 결과를 보면 2개의 key가 있는 dictionary가 있는 것을 알 수 있음
- 입력 ID에는 2 문장의 ID가 모두 포함되며 패딩이 적용된 위치는 0임
- 두 번째 키인 attenion mask는 패딩이 적용된 위치를 나타내므로 모델은 이에 주의를 기울이지 않음
2. Model
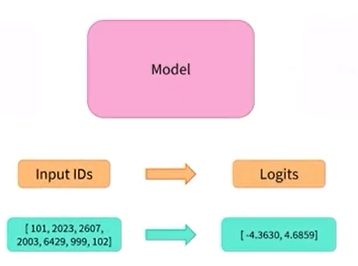
- 2 번째 단계인 모델을 살펴보고자 함
- 토크나이저의 경우, from_pretrained 메서드가 포함된 AutoModel API가 있음
-
모델의 구성과 사전 학습된 가중치를 다운로드하고 캐시함

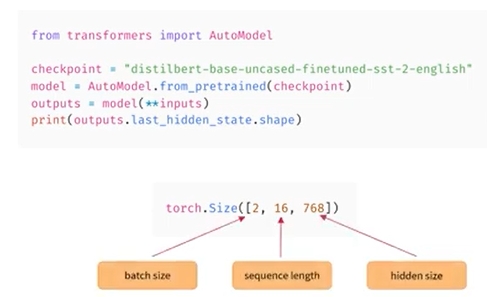
- AutoModel API는 모델의 본문, 즉 pretraining head가 제거된 후 남은 모델 부분만 인스턴스화함
- 전달된 문장을 표현하지만 분류 문제에 직접적으로 유용하지는 않은 고차원 텐서를 출력함
-
여기서 텐서는 두 개의 문장으로 구성되어 있으며 각 토큰은 16개이며 마지막 차원은 모델 768의 hidden size임

- 분류문제와 연결된 출력을 얻으려면 AutoModelForSequenceClassification 클래스를 사용해야함
- classification head가 있는 모델을 구축한다는 점을 제외하면 AutoModel 클래스와 동일하게 작동함
-
Transformers 라이브러리에는 일반적인 NLP task마다 하나의 auto class가 있음

- 여기서는 모델에 2개의 문장을 제공한 후 2X2 크기의 텐서를 얻음
- 각 문장과 possible label이 생성됨
- 이러한 출력은 아직 확률은 아님(합계가 1이 아님)
- 이는 Transformers 라이브러리의 각 모델이 로그를 반환하기 때문임
3. Preprocessing
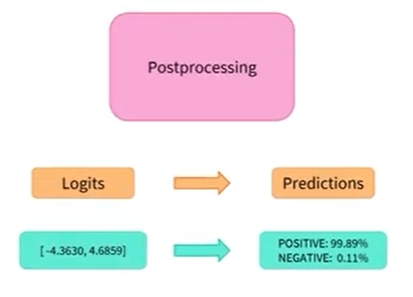
- 파이프라인의 세번째 이자 마지막 단계인 preprocessing을 살펴봐야 함
-
logit을 확률로 변환하려면 softmax 레이어를 적용 해야 함

-
합이 1이 되는 양수로 변환됨

- 마지막 단계는 양수 또는 음수 라벨에 해당하는지 아는 부분임
- 이는 모델 구성의 id2label 필드를 통해서 제공됨
- 첫번째 확률(index 0)은 음수이고, index 1은 양수 라벨에 해당됨
-
이것이 파이프라인 기능으로 구축된 분류기가 해당 라벨을 선택하고 해당 점수를 계산하는 방법임
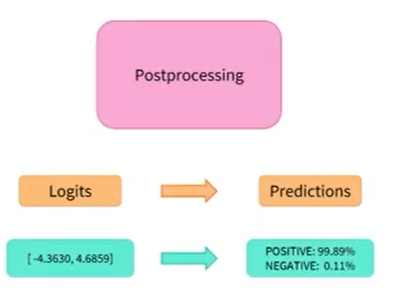
- 이제 각 단계의 작동 방식을 알았으므로 필요에 맞게 쉽게 조정할 수 있음
**Behind the pipeline**
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)
# result
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
-
파이프라인은 전처리(preprocessing), 모델로 입력 전달 및 후처리(postprocessing)의 3단계를 한번에 실행함
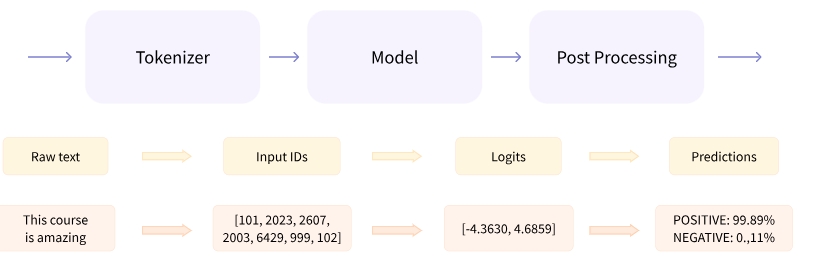
Preprocessing with a tokenizer
- 다른 neural networks과 마찬가지로 Transformer 모델은 원시 텍스트를 직접 처리할 수 없으므로 파이프라인의 첫번째 단계는 텍스트 입력을 모델이 이해할 수 있는 숫자로 변환해야 함
-
이를 위해, 다음 기능들을 수행하는 tokenizer를 사용함
1) Splitting the input into words, subwords, or symbols (like punctuation) that are called tokens
- 입력을 words, subwords, symbols로 splitting
2) Mapping each token to an integer
- 각 토큰(token)을 정수(integer)로 매핑(mapping)
3) Adding additional inputs that may be useful to the model
- 모델에 유용한 additional inputs 추가
- 이 모든 preprocessing는 모델이 pretraining될 때와 정확히 동일한 방식으로 수행되어야 하므로 먼저 Model Hub에서 해당 정보를 다운로드야 함
- 이를 위해
AutoTokenizer클래스와from_pretrained()메서드를 사용함 - 모델의 checkpoint 이름을 사용하여 모델의 tokenizer와 연결된 데이터를 자동으로 가져옴
- 그래서 아래 코드를 처음 실행할 때만 해당 정보가 다운로드됨
sentiment-analysis파이프라인의default checkpoint는distilbert-base-uncased-finetuned-sst-2-english(여기)이므로 다음을 실행함
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- 위와 같이 tokenizer를 생성하면, 아래의 코드에서 보는 것처럼, 이 tokenizer에 문장을 입력하여 모델에 바로 전달할 수 있는 파이썬 dictionary 정보를 구할 수 있음 이후 해야할 일은 input IDs 리스트를 tensors로 변환하는 것임
- tokenizer가 반환하는 텐서의 유형(PyTorch, TensorFlow 또는 일반 NumPy)을 지정하려면
return_tensors인수(argument)를 사용하면 됨
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
padding과truncation은 이후에 설명 예정- 중요한 점은 단일 문장 또는 다중 문장 리스트를 tokenizer 함수로 전달할 수 있을 뿐만 아니라 출력 텐서 유형을 지정할 수 있다는 부분임
- 텐서 유형이 지정되지 않으면 결과로 이중 리스트(list of list)가 표시됨
- PyTorch 텐서 유형의 결과는 위와 같습니다. 위 결과에서 보듯이, 출력은 두 개의 키(key) 즉,
input_ids및attention_mask를 가지는 파이썬 딕셔너리임 input_ids에는 각 문장에 있는 토큰의 고유 식별자로 구성된 두 행의 정수(각 문장에 하나씩)가 값(value)으로 들어가 있음- 해당 장 뒷 부분에
attention_mask설명 예정
**Going through the model**
- tokenizer와 동일한 방식으로 pretrained model을 다운로드할 수 있음
- Transformers는 위의
AutoTokenizer클래스와 마찬가지로,from_pretrained()메서드가 포함된AutoModel클래스를 제공함
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
- 위 code snippet에서는 이전에 파이프라인에서 사용한 것과 동일한 체크포인트를 다운로드하고 모델을 인스턴스화(instantiate)함
- 해당 아키텍처에는 기본 Transformer 모듈만 포함되어 있음
- 따라서, 입력이 주어지면 feature라고도 불리는 hidden states 를 출력함
- 각 모델 입력에 대해 Transformer 모델에 의해서 수행된 해당 입력의 문맥적 이해(contextual understanding) 결과 를 나타내는 high-dimensional vector를 가져옴
- hidden states는 그 자체로도 유용할 수 있지만 일반적으로 head 라고 알려진 모델의 다른 부분에 대한 입력으로 들어감
- 1장에서 이야기했듯이, 같은 아키텍처로 서로 다른 task를 수행할 수 있지만 각 task에 대해서는 다른 head가 연결되어 있음.
**A high-dimensional vector?**
-
Transformer 모듈의 벡터 출력은 일반적으로 규모가 큽니다. 일반적으로 세 가지 차원이 있음
1) Batch size:
- 한 번에 처리되는 시퀀스(sequence)의 개수
- 위 예제 2개
2) Sequence length:
- 시퀀스 숫자 표현의 길이
- 위 예제 16 3) 은닉 크기(Hidden size):
- 각 모델 입력의 벡터 차원.
- 위에서 마지막 값 때문에 high-dimensional 벡터라고 부름
- Hidden size는 매우 클 수 있음(768은 작은 모델에 일반적이고 큰 모델에서는 3072 이상).
- 사전 처리한 입력을 모델에 넘기면 다음과 같은 내용을 볼 수 있음
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
- Transformers 모델의 출력은
namedtuple또는 dictionary처럼 동작함. - 요소에 접근하기 위해서 속성 또는 키(
outputs["last_hidden_state"])를 사용할 수 있음 - 또한, 찾고 있는 항목이 어디에 있는지 정확히 알고 있는 경우 인덱스(
outputs[0])로도 액세스할 수 있음
**Model heads: Making sense out of numbers**
- model head는 hidden states의 high-dimensional vector를 입력으로 받아 다른 차원에 project함
- 일반적으로 head는 하나 또는 몇 개의 linear layers로 구성됨
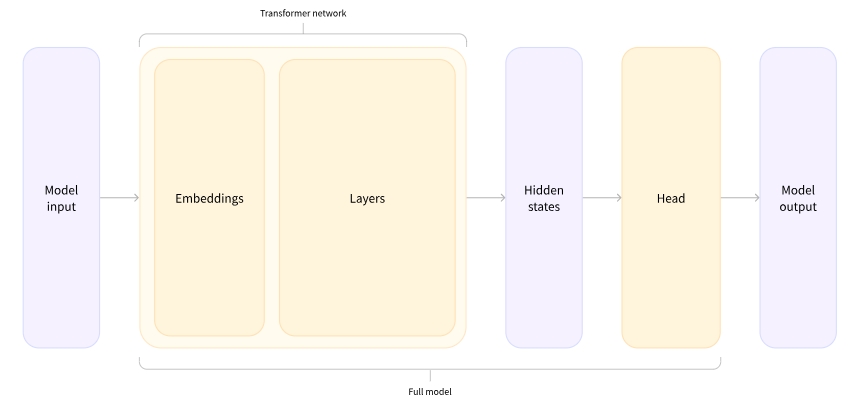
- Transformer 모델의 출력은 처리할 model head로 직접 전달됨
- 위 그림에서 모델은 embeddings layer와 subsequent layers로 표현됨
- embeddings layer는 tokenized input의 각 입력 ID를 해당 토큰을 나타내는 벡터(embeddings vector)로 변환함
- 그 이후의 후속 레이어는 attention mechanism을 사용하여 이들 embeddings vector를 조작하여 문장의 final representation을 생성함
- Transformers에는 다양한 아키텍처가 있으며 각 아키텍처는 특화된 작업을 처리하도록 설계되었음
- 다음은 일부 아키텍처임
Model(retrieve the hidden states)ForCausalLMForMaskedLMForMultipleChoiceForQuestionAnsweringForSequenceClassificationForTokenClassification- and others 🤗
- 이 섹션에서의 예시에서는 sequence classification head가 포함되어 있는 모델이 필요함(문장을 긍정 또는 부정으로 분류하기 위해서).
- 따라서 실제로
AutoModel클래스를 사용하지 않고 대신AutoModelForSequenceClassification를 사용함
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
# result:
torch.Size([2, 2])
- 이제 출력의 shape을 보면 차원이 훨씬 낮아짐
- model head는 고차원 벡터를 입력으로 사용하고 두 개의 값(레이블당 하나씩)을 포함하는 벡터를 출력함
- 두 개의 문장과 두 개의 레이블만 있기 때문에, 모델에서 얻은 결과의 모양(shape)은 2 x 2임
**Postprocessing the output**
- 모델에서 출력으로 얻은 값은 반드시 그 자체로 의미가 있는 것은 아님
print(outputs.logits)
# result
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
- 모델은 첫 번째 문장에 대해
[-1.5607, 1.6123], 두 번째 문장에 대해[4.1692, -3.3464]를 예측함 - 이는 확률이 아니라 모델의 마지막 계층에서 출력된 정규화되지 않은 점수인 logits 임
- 이들 값을 확률로 변환하려면 SoftMax 계층을 통과해야 함
- all Transformers models output the logits, as the loss function for training will generally fuse the last activation function, such as SoftMax, with the actual loss function, such as cross entropy
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
# 결과
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
- 이제 모델이 첫 번째 문장에 대해
[0.0402, 0.9598], 두 번째 문장에 대해[0.9995, 0.0005]를 예측했음을 알 수 있음 → 확률 점수
model.config.id2label
# result
{0: 'NEGATIVE', 1: 'POSITIVE'}
- 각 위치에 해당하는 레이블을 가져오기 위해, model.config의
id2label속성값을 확인함 - 이제 모델이 아래 내용을 예측함을 알 수 있음
- 첫번째 문장 : NEGATIVE: 0.0402, POSITIVE: 0.9598
- 두번째 문장 : NEGATIVE: 0.9995, POSITIVE: 0.0005
지금까지 파이프라인(pipeline)의 내부에서 실행되는 3단계인 토크나이저를 사용한 전처리(preprocessing), 모델을 통한 입력 전달(passing the inputs through the model) 및 후처리(postprocessing)를 성공적으로 실행해봄.
Leave a comment