
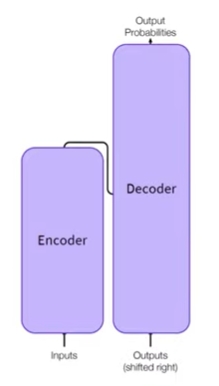
[Hugging Face][C-1] Encoders-Decoders(Sequence-to-sequence models)
Encoders-Decoders
- Encoders-Decoders(=sequence-to-sequence)은 Transformer 아키텍처의 두 부분, 즉 encoder와 decoder를 모두 사용함
- 각 단계에서 attention layer은 initial sentence의 모든 단어에 액세스할 수 있는 반면, 디코더의 attention layer는 문장에서 현재 처리 단어 앞쪽에 위치한 단어들에만 액세스할 수 있음
- 이러한 모델의 pretraining은 인코더 또는 디코더 모델의 목적 함수(objectives)를 사용하여 수행될 수 있지만 일반적으로 약간 더 복잡한 처리 과정이 수반됨
- 예를 들어, T5는 임의의 텍스트 일부분(text span, 여러 단어를 포함할 수 있음)을 하나의 마스크 특수 단어(mask special word)로 대체하여 사전 학습되며,학습 목표(objective)는 이 마스크 단어가 대체할 텍스트를 예측하는 것임
- Sequence-to-sequence 모델은 summarization, translation 또는 생성형 질의응답(generative question answering) 등과 같이 주어진 입력에 따라 새로운 문장을 생성하는 작업(task)에 가장 적합함
Encoders-Decoders 종류
Encoders-Decoders with Lysandre

- 인코더-디코더 아키텍처에 대해서 알아보자
-
널리 사용되는 인코더-디코더 모델의 예로는 T5가 있음
인코더 - 디코더
-
인코더에 관해 앞에서 살펴본 내용과 관련해서 살펴보면
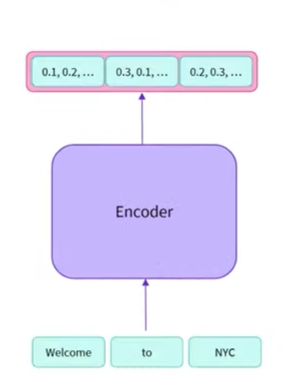
- 인코더는 단어를 입력 받아 인코더를 통해 전송하고 이를 통해 전송된 각 단어에 대한 숫자 표현을 검색함
- numerical representation에 meaning of sequence 정보가 담겨 있음
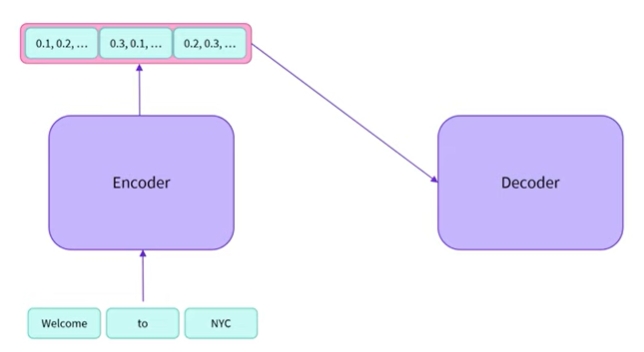
-
이 그림에서는 인코더의 출력을 디코더에 직접 전달하고 있음
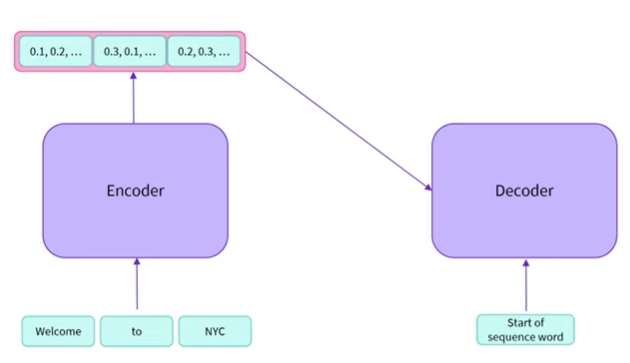
- 인코더 출력 외에도 디코더에 시퀀스를 제공함
- 초기 시퀀스가 없는 출력을 디코더에 요청하는 경우 시퀀스의 시작을 나타내는 값을 제공할 수 있음
- 인코더는 시퀀스를 입력으로 받아들임, 예측을 계산하고 numerical representation을 출력함
- 그런 다음 이를 디코더로 보냄, 어떤 의미에서 시퀀스를 인코딩함
-
그리고 디코더는 일반적인 시퀀스 입력과 함께 이 입력을 사용하여 시퀀스 디코딩을 시도함
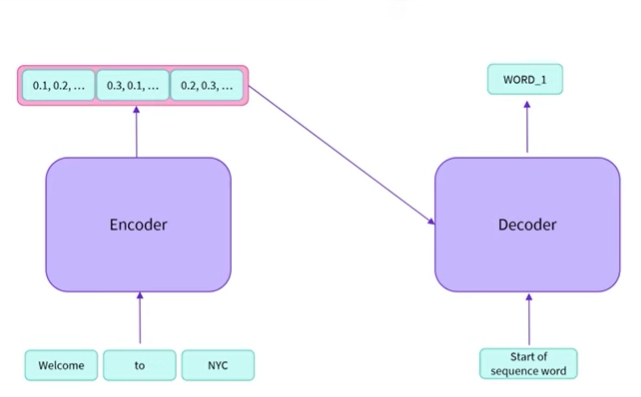
- 디코더는 시퀀스를 디코딩하고 단어를 출력함
- 디코더가 기본적으로 인코더의 출력을 디코딩하고 있다는 점은 이해할 수 있음
- 시퀀스 단어 시작은 시퀀스 디코딩을 시작해야 함을 나타냄
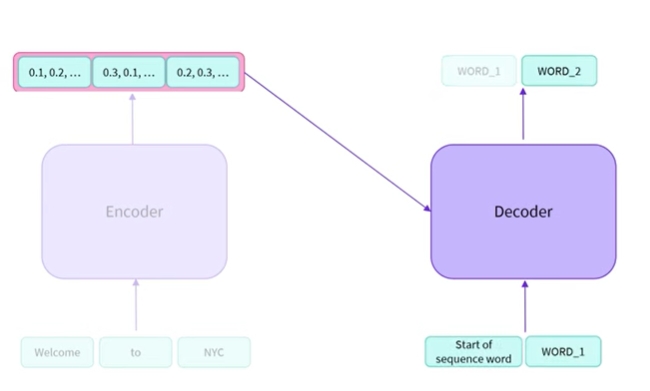
- 이제 feature vector와 초기 생성 단어가 모두 있으므로 더 이상 인코더가 필요하지 않음
- 이전에 디코더에서 본 것 처럼 auto regressive 방식으로 작동할 수 있음
- 방금 출력한 단어를 이제 입력으로 사용할 수 있음
- 이는 인코더에서 출력되는 numerical representation과 결합하여 두 번째 단어를 생성하는데 사용될 수 있음
-
첫번쨰 단어는 계속 있는데 모델이 계속 출력하기 때문임
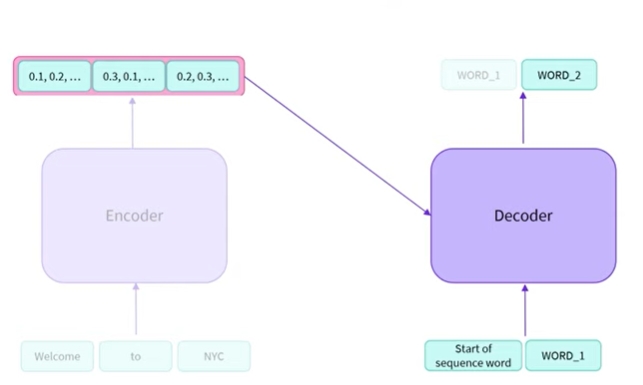
-
하지만 더 이상 필요하지 않으므로 회색으로 표시함
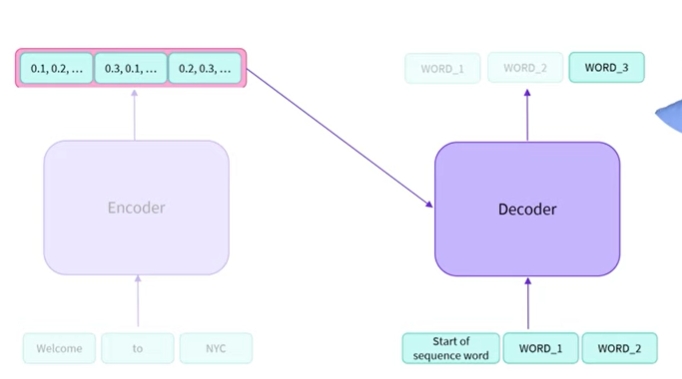
- 계속해서 진행할 수 있는데 디코더가 점과 같이 시퀀스의 끝을 의미하는 stopping value중지 값으로 간주되는 값을 출력할 때까지
- 인코더로 전송되는 초기 시퀀스가 있음, 그런 다음 해당 인코더 출력은 디코딩을 위해 디코더로 전송됨, 인코더는 한번 사용한 후 폐기할 수 있지만 디코더는 필요한 모든 단어를 생성할 때까지 여러번 사용됨
번역 언어 모델링 사용
-
시퀀스를 번역하는 행위
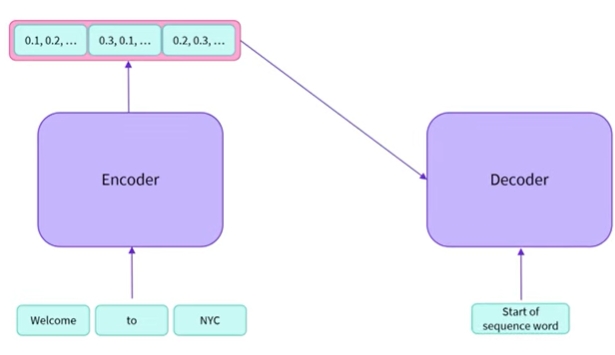
- ‘Welcome to NYC’를 프랑스어로 번역하고 싶음
- 해당 작업을 위해 명시적으로 학습된 변환기 모델을 사용하고 있음
-
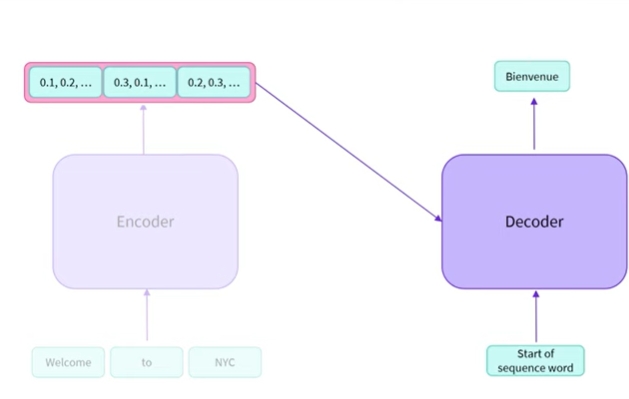
인코더를 사용하여 영어 문장의 표현을 만듦 , 이것을 디코더에 캐스팅하고 시퀀스 단어의 시작을 사용하여 첫번째 단어를 출력하도록 요청함
-
welcome을 뜻하는 Bienvenue를 출력함
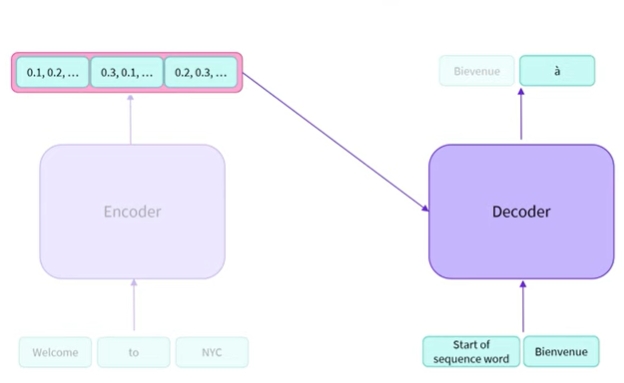
- 그런 다음 디코더의 입력 시퀀스로 Bienvenue를 사용함
-
이를 통해 feature vector와 함께 디코는 영어로 to인 두번째 단어 a를 예측할 수 있음
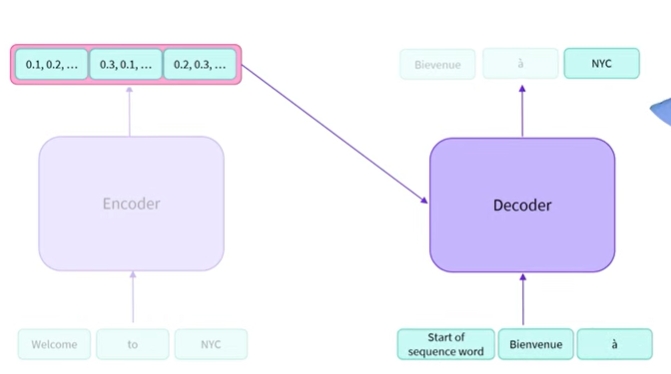
- 마지막으로 디코더에게 세번째 단어를 예측하도록 요청함
-
NYC를 예측함
- 인코더와 디코더는 종종 가중치를 공유하지 않음
- 시퀀스를 이해하고 관련 정보를 추출하도록 훈련할 수 있는 전체 블럭(인코더)를 보유함
-
번역 시나리오의 경우, 영어로 말하 내용을 구문 분석하고 이해하는 것을 의미함
-
해당 언어에서 정보를 추출하고 모든 정보를 정보가 밀집된 벡터에 넣음
- 디코더의 유일한 목적은 인코더에 의해 출력된 기능을 디코딩하는 것임
-
이 디코더는 완전히 다른 언어 또는 이미지나 음성과 같은 양식에 특화될 수 있음

- 인코더-디코더는 여러가지 이유로 특별함
1) 방금 본 번역과 같은 sequence to sequence가 가능함
2) 인코더와 디코더 부분 간의 가중치가 반드시 공유되는 것은 아님
sequence to sequence: translation
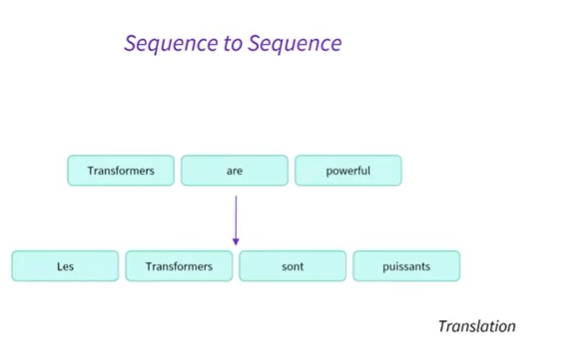
- Transformers are powerful을 프랑스어로 번역하고자 함
세 단어의 시퀀스에서 네 단어의 시퀀스를 생성할 수 있음
auto regressive 방식으로 번역을 생성함
sequence to sequence: summarization
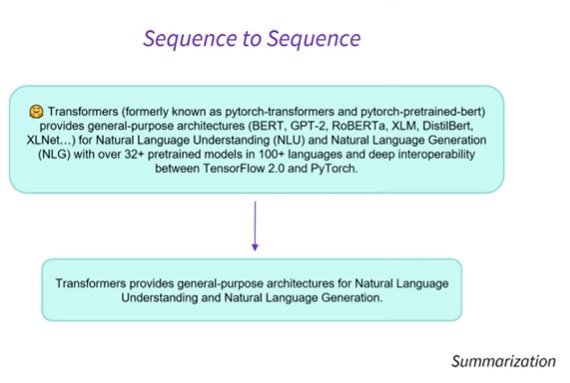
- sequence to sequence에서 적용되는 또 다른 예는 요약임
- 여기에는 일반적으로 전체 텍스트인 매우 긴 시퀀스가 있으며, 이를 요약하고 자함
- 인코더와 디코더가 분리되어 있으므로 context의 길이가 다를 수 있음
- 예를 들어 텍스트를 처리하는 인코더의 매우 긴 context와 요약된 시퀀스를 처리하는 디코더의 더 작은 context
sequence to sequence: many others
- sequence to sequence 많은 모델이 있음
- 라이브러리에서 사용할 수 있는 인기 있는 인코더-디코더 모델의 예임
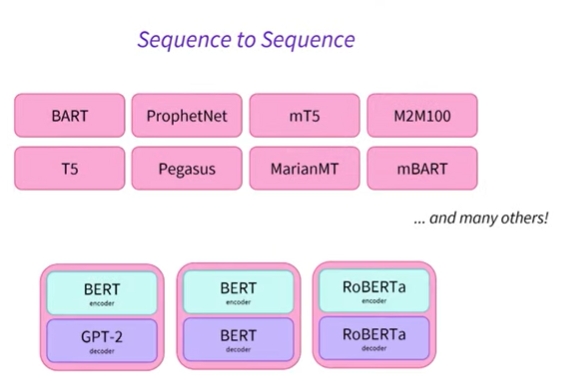
- 또한, 인코더-디코더 모델 내부에 인코더와 디코더를 로드할 수 있음
- 따라서 목표로 삼고 있는 특정 작업에 따라 이러한 특정 작업에서 그 가치가 입증된 특정 인코더 및 디코더를 사용하도록 선택할 수 있음
Leave a comment