

추천시스템 이해
1. Introduction
1-1. 추천시스템의 의미
추천시스템은 개인 맞춤형 서비스 제공을 위해 구매패턴 등 과거 데이터를 분석하여 상품을 추천하는 시스템을 의미함, 사용자가 생각하는 순위나 선호도를 예측하는 일종의 정보 필터링의 시스템임
1-2. 추천시스템의 필요성
- 정보가 증가함에 따라 모든 것을 볼 수 없어짐
- 사용자에게 가장 필요한 정보를 제공
- 추천은 서비스 제공자에게 경제적 이득을 줌
1-3. 추천시스템의 역할
- 사용자가 어떤 상품과 서비스를 얼마나 좋아할지 예측
- 사용자가 좋아할 N개의 상품 추출
- 특정 상품, 서비스를 좋아할 N명을 탐색
- 추천 이유 설명
2. 추천시스템의 개요
추천 시스템 분류
1. 수집 정보에 따른 분류
- Explicit feedback: item의 구체적인 점수를 수집할 수 있는 환경으로 사용자가 해당 item에 얼마나 호감할 수 있는지를 수치로 feedback 활용(ex. 왓챠의 영화 별점)
- Implicit feedback: item에 대한 구체적인 호감 점수 수집이 어려운 경우로 사용자의 간접정보(구매여부, 클릭, 조회)만을 수집하여 간접 정보를 제공(ex. 넷플릭스 컨텐츠 감상, 유튜브 뮤직 재생)
2. 알고리즘 방법에 따른 분류
추천시스템은 콘텐츠 기반 필터링과 협업 필터링 방식으로 나뉘며, 협업 필터링 방식은 최근접 이웃 협업 필터링과 잠재요인(Latent Factor) 협업 필터링으로 나뉨. 추천시스템 초기에는 콘텐츠 기반 필터링과 최근접 이웃 기반 협업 필터링이 주로 사용됐으나 넷플릭스 추천 시스템 대회에서 행렬분해(Matrix Factorization)기법을 이용한 잠재 요인 협업 필터링 방법이 우승한 후 대세 추천 기법이 됨, 하지만 서비스 아이템 특성에 따라 기존 방식을 유지하는 경우도 있으며, 아마존은 아이템 기반의 최근접 이웃 협업 필터링 방식을 추천 엔진으로 사용하고 있음, 최근에는 하이브리드 형식으로 콘텐츠 기반과 협업 기반을 섞어서 사용하는 경우도 생겨나고 있음
추천을 위한 알고리즘은 메모리 기반과 모델 기반으로 나눌 수 있는데
- 메모리 기반 알고리즘은 추천을 위한 데이터를 모두 메모리에 가지고 있으면서 추천이 필요할 때마다 이 데이터를 사용해서 계산을 해서 추천하는 방식 → 대량의 데이터를 다뤄야 하는 상용 사이트에서는 계산시간이 오래 걸림, 개별 사용자의 데이터에 집중
- 모델 기반 추천: 데이터로부터 추천을 위한 모델을 구성한 후에 이 모델만 저장하고, 실제 추천을 할 때에는 이 모델을 사용해서 추천을 하는 방식 → MF 방식이 모델 기반 추천 알고리즘, Deep learning 기반 추천 알고리즘, 전체 사용자의 평가 패턴으로부터 모델을 구성하기 때문에 데이터가 가지고 있는 weak signal도 더 잘 잡아내는 장점(weak signal: 개별 사용자의 행동 분석에서는 잘 드러나지 않는 패턴, 소수의 사용자가 소수 영화에 대해서만 특정한 평가 패턴이 있는 경우)
1) Association Rule: 연관 규칙, 장바구니 분석
2) Contents-based Filtering: 컨텐츠 기반 분석
3) Collaborative Filtering: 협업필터링
- Memory-based: user based, item based
- Model-based: Matrix Factorization(ALS)
2-1. Contents based
1) Contents based Filtering 개념
- 아이템이나 유저의 컨텐츠 자체를 분석하여 비슷한 아이템 추천
- 사용자가 특정 아이템을 선호하는 경우, 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식으로 사용자가 특정 영화에 높은 평점을 줬다면 해당 영화의 장르, 배우, 내용 등 유사한 콘텐츠를 추천하는 방식
- 많은 양의 유저 액션을 요구하지 않음(cold start X)
- 컨텐츠의 타입과 양에 따라 적용 가능 여부가 결정되고, 가능하더라도 비슷한 아이템끼리만 추천하는 한계가 있음
2) Contents based Filtering 예시
- 사용자: 나이, 성별 기반
2-2. Collaborative Filtering
1) collaborative filtering 개념
- 아이템이나 유저의 유사도를 모델링하고 측정하여 추천
- 아이템을 분석하지 않고 유저의 평가 내역을 이용
- 복잡하고 많은 아이템을 정의하며 분석하지 않아도 되는 장점이 있음
2) collaborative filtering의 한계
- Cold Start : 처음에 수집정보(아이템, 유저)가 없어서 모델 학습이 어려움
- Scalability: 데이터가 커져서 메모리를 많이 사용함
- Sparseness: 사용자 정보가 부족할 때 추천이 어려움
- Popularity Bias: 대다수의 사람을 따라감
2-2-1. 최근접 이웃 협업 필터링
- 협업 필터링의 주요 목표는 사용자-아이템 평점 매트릭스와 같은 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가를 하는 것
- 아이템 기반 최근접 이웃 방식: 사용자 기반 최근접 이웃 방식은 특정 사용자와 유사한 다른 사용자를 TOP-N으로 선정해 이 TOP-N 사용자가 좋아하는 아이템을 추천하는 방식, 특정 사용자와 타 사용자 간의 유사도를 측정한 뒤 가장 유사도가 높은 TOP-N 사용자를 추출해 선호하는 아이템을 추천하는 것, 아이템 간의 속성이 얼마나 비슷한지를 기반으로 추천하는게 아니고, 사용자들이 그 아이템을 좋아하는지, 싫어하는지의 평가 척도가 유사한 아이템을 추천하는 기준이 되는 알고리즘
- 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 높음, 비슷한 상품을 좋아한다고 해서 사람들의 취향이 비슷하다고 판단하기 어려운 경우가 많음. 유명한 영화는 취향과 관계없이 대부분의 사람이 관람하는 경우가 많기 때문 이러한 이유로 최근접 이웃 협업 필터링은 대부분 아이템 기반의 알고리즘을 적용함, 유사도 측정방법인 코사인 유사도는 추천 시스템 유사도 측정에 가장 많이 적용되는데 추천 시스템에 사용되는 데이터는 피처 벡터화된 텍스트 데이터와 동일하게 다차원 희소 행렬이라는 특징이 있으므로 유사도 측정을 위해 주로 코사인 유사도를 이용함
2-2-2. 잠재 요인 협업 필터링
- 대규모 다차원 행렬을 SVD와 같은 차원 감소 기법으로 분해하는 과정에서 잠재 요인을 추출하는데 이러한 기법을 행렬 분해(Matrix Factorization)이라고 하며, 행렬 분해 기반의 잠재 요인 협업 필터링은 넷플릭스 대회에서 우승을 하며 유명해짐. 우승을 한 모델은 행렬 분해 기반의 여러 모델을 결합해 만든 모델
- 잠재 요인 협업 필터링은 사용자-아이템 평점 행렬 데이터만을 이용해 말 그대로 ‘잠재 요인’을 끄집어 내는 것을 의미
- 잠재요인을 기반으로 다차원 희소 행렬인 사용자0아이템 행렬 데이터를 저차원 밀집 행렬의 사용자-잠재 요인 행렬과 아이템-잠재 요인 행렬의 전치 행렬(잠재 요인-아이템 행렬)로 분해할 수 있으며, 이렇게 두 행렬의 내적을 통해 새로운 예측 사용자-아이템 평점 행렬 데이터를 만들어서 사용자가 아직 평점을 부여하지 않는 아이템에 대한 예측 평점을 생성하는 것이 잠재 요인 협력 필터링 알고리즘
- 행렬 분해에 의해 추출되는 ‘잠재 요인’이 정확히 어떤 것인지는 알 수 없지만, 즉, 사용자-잠재 요인 행렬은 사용자의 영화 장르에 대한 선호도로, 아이템-잠재 요인 행렬은 영화의 장르별 특성값으로 정의할 수 있음
- 잠재 요인 협업 필터링은 숨겨져 있는 ‘잠재요인’을 기반으로 분해된 매트릭스를 이용해 사용자가 아직 평가하지 않은 아이템에 대한 예측 평가를 수행
[행렬 분해(Matrix Factorization)]
- 행렬 분해는 다차원의 매트릭스를 저차원 매트릭스로 분해하는 기법으로서 대표적으로 SVD(Singular Vector Decomposition), NMF(Non Negative Matrix Factorization) 등이 있음
- Factorization(분해): 인수분해, 일반적으로 하나의 복잡한 다항식을 두 개 이상의 좀 더 단순한 인수의 곱으로 분해하는 것, 행렬 분해는 단지 대상이 행렬이라는게 다름
- M개의 사용자(User)행과 N개의 아이템(Item) 열을 가진 평점 행렬 R은 MXN 차원으로 구성되며, 행렬 분해를 통해서 사용자 K 차원 잠재 요인 행렬P(P는 M X K 차원)와 K 차원 잠재 요인 - 아이템 행렬 Q.T(Q.T는 K X N차원)으로 분해됨(Q는 아이템-잠재 요인 행렬이며, Q.T는 Q의 전치 행렬인 잠재요인-아이템행렬)
- 행렬 분해는 주로 SVD(singular value decomposiotion)방법을 이용하는데 SVD는 널(NaN) 값이 없는 행렬에만 적용할 수 있음, 널 값이 있는 경우, SVD 방식으로 분해가 어려우며, 이런 경우 확률적 경사 하강법(Stochastic Gradient Descent,SGD)나 ALS(Alternating Least Squares) 방식을 이용해 SVD를 수행함
- 확률적 경사 하강법을 이용한 행렬 분해 방법: P와 Q 행렬로 계산된 예측 R 행렬 값이 실제 R 행렬 값과 가장 최소의 오류를 가질 수 있도록 반복적인 비용 함수 최적화를 통해 P와 Q를 유추해내는 것
- 확률적 경사하강법의 단계
- P와 Q를 임의의 값을 가진 행렬로 설정
- P와 Q.T 값을 곱해 예측 R 행렬을 계산하고 예측 R 행렬과 실제 R 행렬에 해당하는 오류 값을 계산
- 이 오류 값을 최소화할 수 있도록 P와 Q 행렬을 적절한 값으로 각각 업데이트
- 만족할 만한 오류 값을 가질 때까지 2,3번 작업 반복하여 P와 Q 값 업데이트해 근사화
2-2-3. 딥러닝 기반 추천
현재 wide and deep, autorec, factorization machine, dlrm 등 다양한 딥러닝 기반의 추천 방법이 나와있는 상황임
3. 추천시스템 평가 방법
3-1. 정확도 측정
먼저 데이터를 train set과 test set으로 나누어 train으로 추천 모형을 학습시키고, test set으로 정확도를 계산함.
정확도 측정은 두 가지로 나뉘는데 1) 각 아이템의 예상 평점과 실제 평점의 차이를 계산하는 방법 2) 추천한 아이템과 사용자의 실제 선택을 비교하는 방법이 있음
3-1-1. 각 아이템의 예상 평점과 실제 평점의 차이를 계산하는 방법
예측값과 실제값의 차이가 적을수록, 즉 측정지표가 작을수록 정확하며, MSE와 RMSE가 많이 사용됨
3-1-2. Ranking 기반 추천 시스템 성능 평가 지표 :
- 추천한 아이템과 사용자의 실제 선택을 비교하는 방법
- 현실 데이터가 연속값 아닌 이진값(선택여부)의 형태가 많음
-
정밀도와 재현율, 정밀도와 재현율의 조화평균과 범위도 측정지표로 사용됨
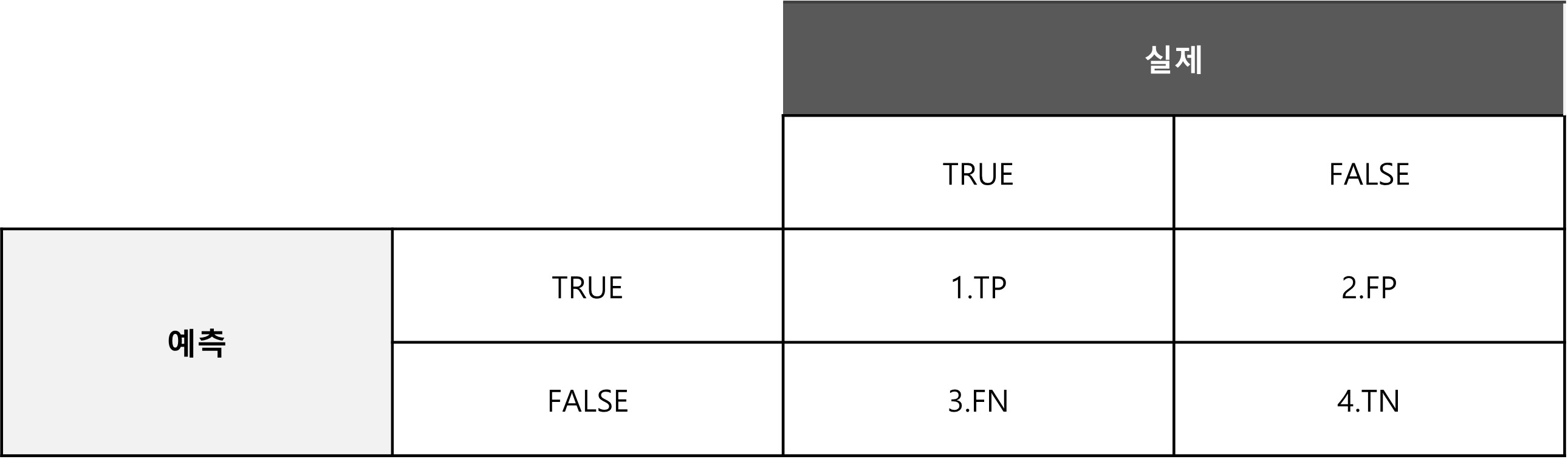
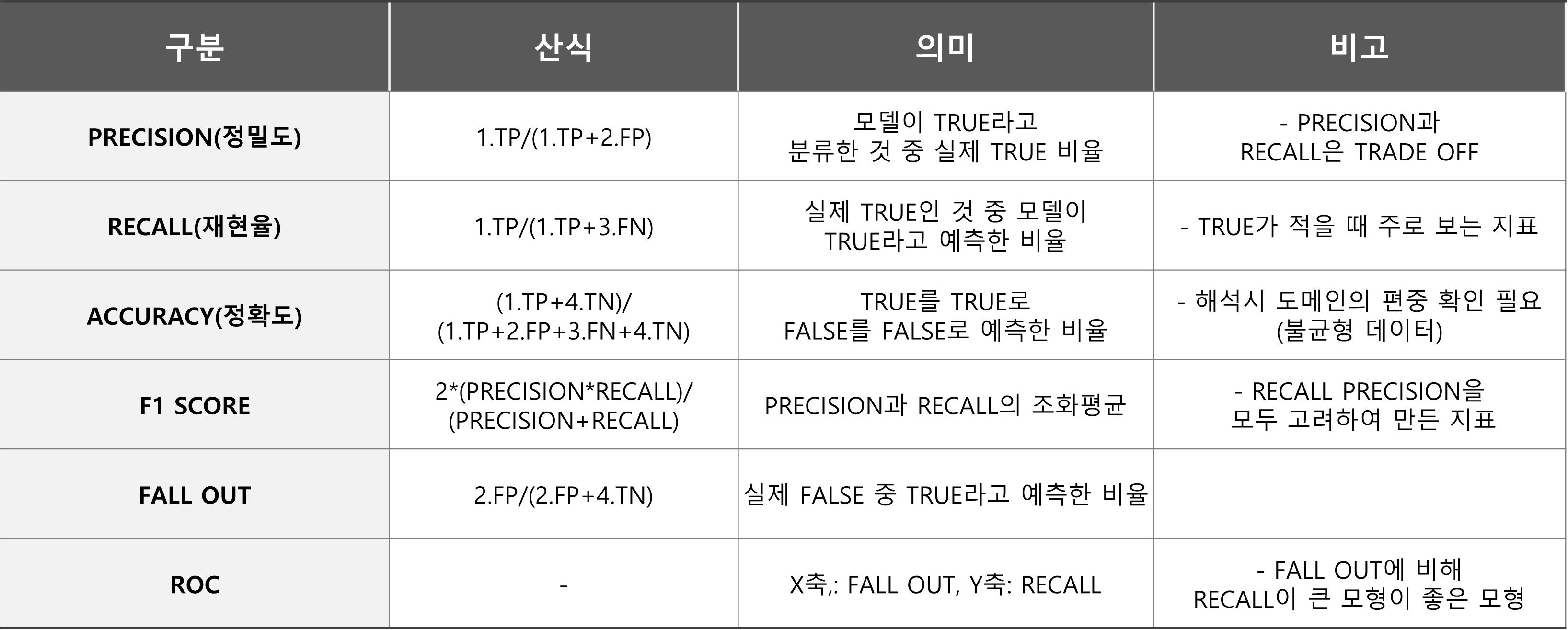
K개의 아이템을 추천한 경우 측정하는 지표: precision top k , recall top k, ndcg top k, hit rate
1.Hit Rate
전체 사용자 수에 대해 Hit/적중한 사용자 수를 의미함

사용자에 대한 상위 n개의 추천을 생성하고 사용자가 선호를 나타낸 결과와 비교함, 각 사용자의 상위 N개 train data에서 하나의 데이터를 제거하고 해당 데이터를 사용하여 모델을 평가하는 one out cross validation 방법을 사용할 수 있음, 생성된 상위 N개 목록에 train set에 누락된 데이터가 포함되어 있으면 Hit(적중)으로 간주함
2) Precision@K
Precision은 TRUE로 예측한 것 중 실제 TRUE의 비율을 의미하는데 Precision top K는 추천한 아이템 K 중 사용자가 실제로 반응한 아이템의 비율을 의미함
3) Recall@K
모든 TRUE 중 TRUE로 예측한 것이 얼마나 되는지의 비율을 나타냄, Recall@K는 사용자가 관심있는 모든 아이템 중 추천한 아이템 K개 얼마나 포함되는지의 비율임
4) Average Precision @K
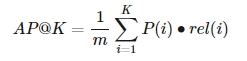
- 성능평가에 순서 개념을 도입한 지표
- P(i): 해당 index까지의 precision 값
- rel(i): 해당 index에서 사용자의 engagement가 일어났는지 여부
- m: 사용자가 engage한 횟수를 의미, 일정 기간 내 일어난 이벤트 횟수
-
같은 양의 추천을 한 경우, 아이템이 앞쪽에 배치될 수록 높은 점수가 나옴

- 사용자가 좋아한 아이템의 추천 순서에 따라 AP값에 차이 남
5) Mean Average Precision @K
-
AP는 개인마다의 추천한 결과이며, MAP는 전체 사용자에 대해 평가하는 것을 의미함
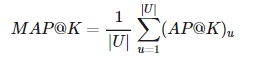
-
U : 유저의 수 - 총 사용자가 3명이라고 하면 각 유저의 AP@K 값을 평균하면 MAP@K를 구할 수 있음
6) NDCG@K
(1) CG(Cumulative Gain)
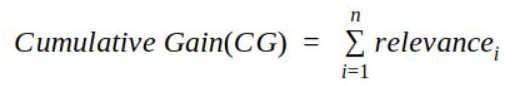
- relevance 점수를 합한 값
- relevance는 사용자가 추천된 각 아이템을 어마나 선호하는지를 나타내는 점수, 보통 rating 값 사용
- rel_uj : 사용자 u가 item j에 대한 관련성 점수
-
g_uj : relevance_Uj의 지수함수 형태, 관련성 점수가 높은 아이템이 낮게 랭크 되었을때 더 패널티를 줄 수 있음
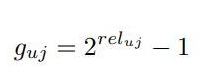
(2) DCG(Discounted Cumulative Gain)
- CG에 discount를 도입한 DCG, 추천아이템의 순서가 뒤에 있을수록 전체 DCG 영향을 적게 주게 됨 그러나 사용자별로 추천 아이템 수가 다르면 정확한 평가가 어렵다는 한계점이 존재(추천 아이템 수 많아질 수록 DCG 값 증가하므로 정확한 평가 위해 스케일 맞출 필요가 있음)
- Vj는 test set에서 item j에 대한 랭킹 → 랭킹이 아래로 갈수록 분모가 커지므로 랭킹이 낮은 아이템은 영향이 줄어듦
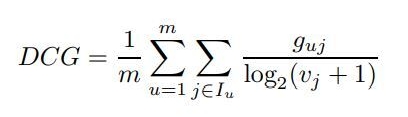
-
DCG는 모든 아이템에 적용하기 보다는 특정 L개에서 계산함
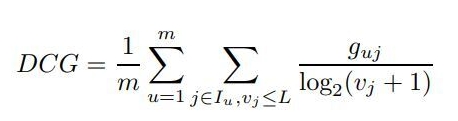
(3) NDCG(Normalized Discounted Cumulative gain)
- DCG의 한계(추천아이템 갯수에 따라 DCG 다름) 보완하기 위해 DCG에 정규화를 적용한 것
- IDCG(Ideal Discounted Cumulative gain): 최선의 추천을 했을 때 산출되는 DCG 값
- NDCG = DCG/IDCG
- 이상적인 추천 조합 대비 현재 추천이 얼마나 좋은지를 보여주는 지표이며 정규화를 통해 0~1사이의 값을 가지게 됨
- 추천하는 아이템 K개를 볼 때 K가 증가함에 따라 DCG는 증가하는데 NDCG는 K에 독립적이어서 K 갯수를 적절한지 판단이 가능함
- Top K개 아이템을 추천하는 경우, 추천 순서에 가중치를 두어 평가하며 1에 가까울수록 좋다. 랭킹에 민감한 추천서비스에 유용한 평가지표, NDCG는 등급, 범위 매기거나, binanry relevance 둘다 평가가 가능함
References
Recommender systems from achievements to requirements
파이썬 머신러닝 완벽 가이드
Python을 이용한 개인화 추천 시스템
Leave a comment