
[추천시스템] AutoInt (개념/수식/구현 코드)
AutoInt
모델 개요
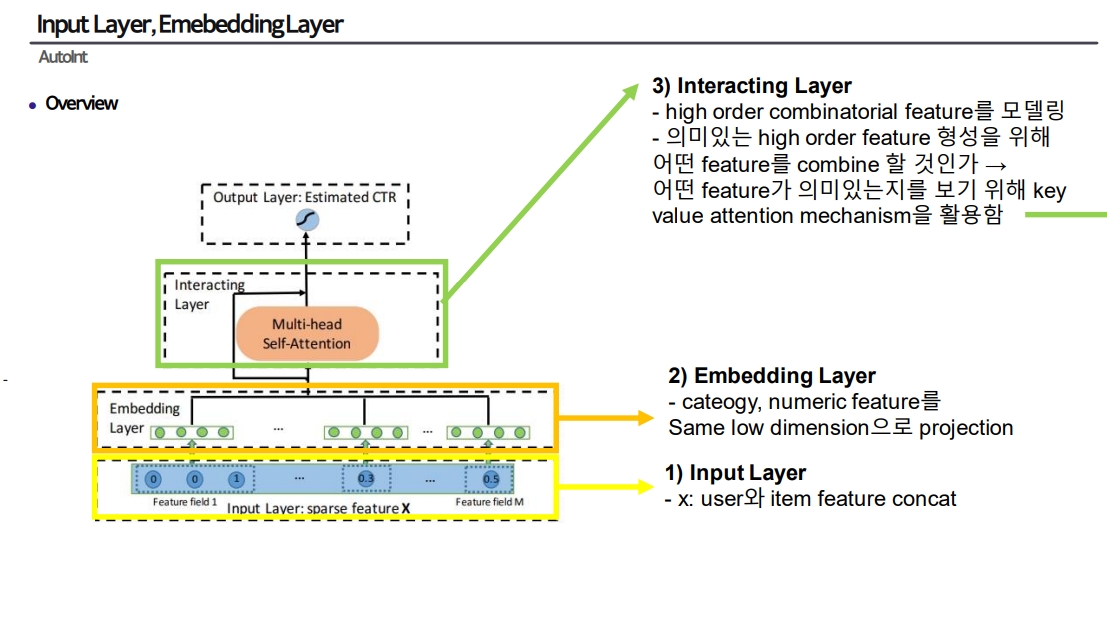
Layer 구성
Main Layer 1: Embedding Layer
Main Layer 2: Interacting Layer
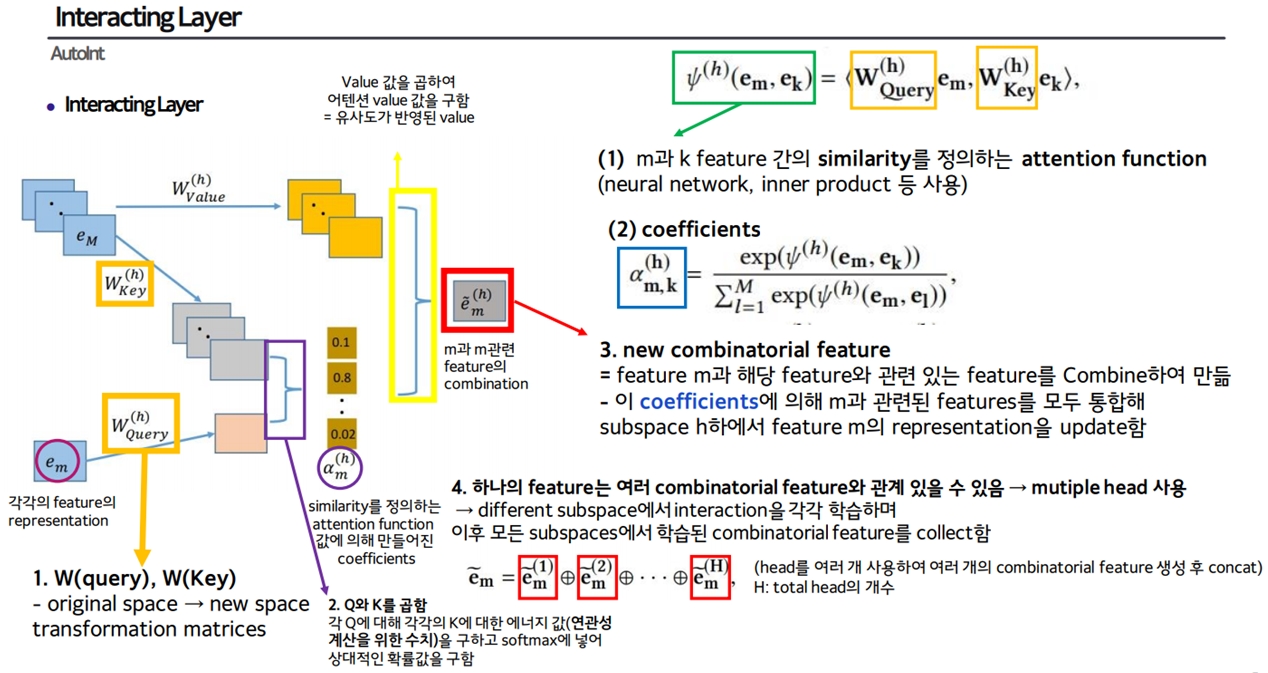
- MultiHeadSelfAttention
- Scaled Dot Product Attention: MultiHeadSelfAttention 안에 있는 dot attention
코드 분석
LR_Layer, MLP_Layer
def get_activation(activation):
if isinstance(activation, str): # activation 값이 str인가
if activation.lower() == "relu":
return nn.ReLU()
elif activation.lower() == "sigmoid":
return nn.Sigmoid()
elif activation.lower() == "tanh":
return nn.Tanh()
else:
return getattr(nn, activation)()
# getattr: 스트링을 Attribute화
# ex: . getattr(np, 'array')([1])= np.array([1])
else:
return
# LR_Layer: Input X → Embedding Layer 통과
# self.lr_layer = LR_Layer(feature_map, output_activation=None, use_bias=False)
class LR_Layer(nn.Module):
def __init__(self, feature_map, output_activation=None, use_bias=True):
super(LR_Layer, self).__init__()
self.bias = nn.Parameter(torch.zeros(1), requires_grad=True) if use_bias else None
self.output_activation = output_activation
# A trick for quick one-hot encoding in LR
self.embedding_layer = EmbeddingLayer(feature_map, 1, use_pretrain=False)
def forward(self, X):
embed_weights = self.embedding_layer(X)
output = embed_weights.sum(dim=1)
if self.bias is not None:
output += self.bias
if self.output_activation is not None:
output = self.output_activation(output)
return output
class MLP_Layer(nn.Module):
def __init__(self,
input_dim,
output_dim=None,
hidden_units=[],
hidden_activations="ReLU",
output_activation=None,
dropout_rates=0.0,
batch_norm=False,
use_bias=True):
super(MLP_Layer, self).__init__()
dense_layers = []
if not isinstance(dropout_rates, list):
dropout_rates = [dropout_rates] * len(hidden_units)
if not isinstance(hidden_activations, list):
hidden_activations = [hidden_activations] * len(hidden_units)
hidden_activations = [get_activation(x) for x in hidden_activations]
hidden_units = [input_dim] + hidden_units
for idx in range(len(hidden_units) - 1):
dense_layers.append(nn.Linear(hidden_units[idx], hidden_units[idx + 1], bias=use_bias))
if batch_norm:
dense_layers.append(nn.BatchNorm1d(hidden_units[idx + 1]))
if hidden_activations[idx]:
dense_layers.append(hidden_activations[idx])
if dropout_rates[idx] > 0:
dense_layers.append(nn.Dropout(p=dropout_rates[idx]))
if output_dim is not None:
dense_layers.append(nn.Linear(hidden_units[-1], output_dim, bias=use_bias))
if output_activation is not None:
dense_layers.append(get_activation(output_activation))
self.dnn = nn.Sequential(*dense_layers) # * used to unpack list
def forward(self, inputs):
return self.dnn(inputs)
Attention 관련 Class
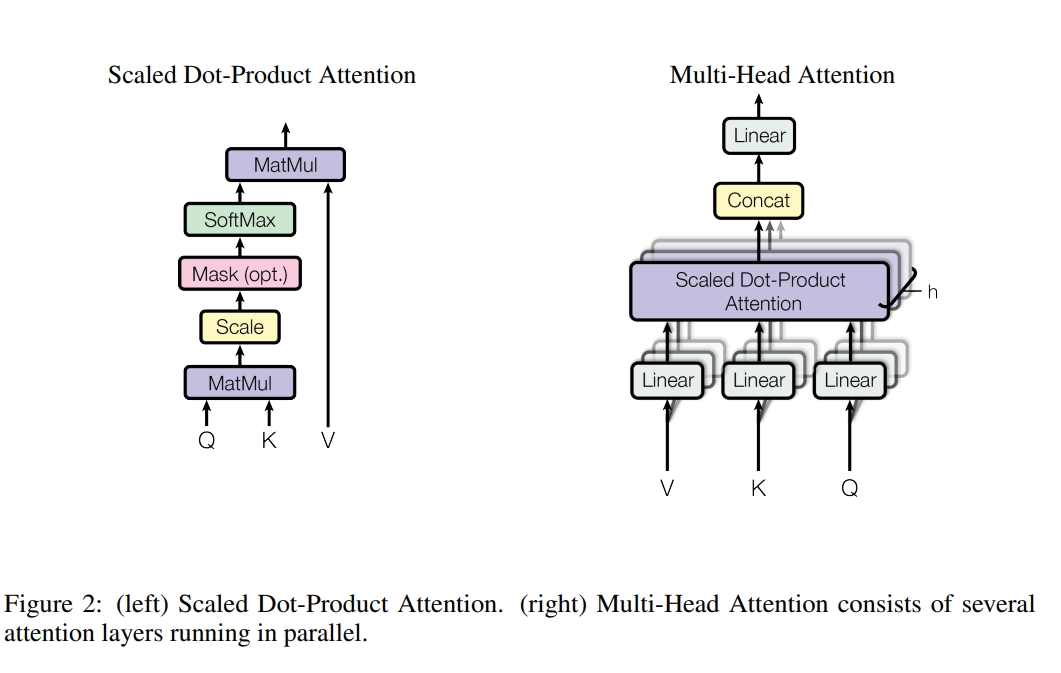
- Multi head attention의 구성: (O,K,V) → (linear) → (scaled dot product attention) * h개 진행 → (concat) → (linear)
- 물어보는 주체(Q)가 들어오고 각각 어텐션을 수행할 단어들인 K가 들어가서 행렬곱(matmul)을 수행 및 scale 진행 → 필요한 경우 mask를 씌워준 다음에 softmax를 취하여 → 어떤 단어와 가장 높은 연관성을 가지는지 비율을 구할 수 있음→이 확률값과 Value 값을 곱하여(matmul) → Attention Value를 얻음
- 요약: 하나의 어텐션은 Q,K,V를 가지고 Q와 K를 곱해서 각 Q에 대해서 각각의 K에 대한 에너지 값을 구해서 softmax로 확률값으로 만들고 scale을 함(각각의 K dim) → 그리고 V값과 곱해주어 Attention Value를 얻음
- 해당 코드에서도 마찬가지로 Class ScaledDotProductAttention를 만들고 이를 사용하여 Class MultiHeadSelfAttention를 구성함
scaled dot product attention
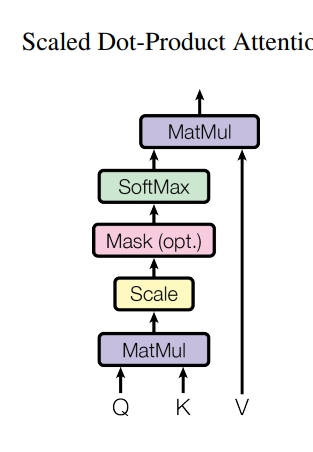
# scaled dot product attention
# step01: Q와 K 행렬곱(matmul)
# step02: scale
# step03: mask (값이 0인 부분을 채워줌)
# step04: softmax
# step05: dropout
# step06: 최종 output(attention value): 위의 결과와 V 값 행렬곱(matmul)
class ScaledDotProductAttention(nn.Module):
""" Scaled Dot-Product Attention
Ref: https://zhuanlan.zhihu.com/p/47812375
"""
def __init__(self, dropout_rate=0.):
super(ScaledDotProductAttention, self).__init__()
self.dropout = None
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
def forward(self, Q, K, V, scale=None, mask=None):
# step01
scores = torch.matmul(Q, K.transpose(-1, -2))
# step02
if scale:
scores = scores / scale
# step03: mask
if mask:
scores = scores.masked_fill_(mask, -1e-10)
# step04
attention = scores.softmax(dim=-1)
# step05
if self.dropout is not None:
attention = self.dropout(attention)
# step06
output = torch.matmul(attention, V)
return output, attention
Multi head attention
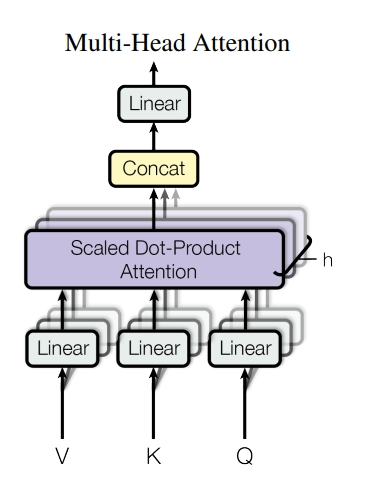

- Multi head attention의 구성: (O,K,V) → (linear) → (scaled dot product attention) * h개 진행 → (concat) → (linear)
- 서로 다른 linear layer를 만들어서 h개의 서로 다른 각각의 Q,K,V를 만들도록 함
- h개의 서로 다른 컨셉을 네트워크가 구분해서 학습하도록 함
# Multi head attention
# step01: (O,K,V) → (linear) : h개의 Q,K,V /Residual도 linear 진행
# step02: (scaled dot product attention) * h개 진행
# step03: (concat heads)
# step04: (residual connection)
# step05: (linear)
# step06: relu
class MultiHeadSelfAttention(nn.Module):
""" Multi-head attention module """
def __init__(self, input_dim, attention_dim=None, num_heads=1, dropout_rate=0.,
use_residual=True, use_scale=False, layer_norm=False):
super(MultiHeadSelfAttention, self).__init__()
if attention_dim is None:
attention_dim = input_dim
assert attention_dim % num_heads == 0, \
"attention_dim={} is not divisible by num_heads={}".format(attention_dim, num_heads)
self.head_dim = attention_dim // num_heads
self.num_heads = num_heads
self.use_residual = use_residual
self.scale = self.head_dim ** 0.5 if use_scale else None
# step01(O,K,V) → (linear) : h개의 Q,K,V /Residual도 linear 진행
self.W_q = nn.Linear(input_dim, attention_dim, bias=False)
self.W_k = nn.Linear(input_dim, attention_dim, bias=False)
self.W_v = nn.Linear(input_dim, attention_dim, bias=False)
# Linear projection of residual
if self.use_residual and input_dim != attention_dim:
self.W_res = nn.Linear(input_dim, attention_dim, bias=False)
else:
self.W_res = None
# step02: scaled dot product attention
self.dot_attention = ScaledDotProductAttention(dropout_rate)
self.layer_norm = nn.LayerNorm(attention_dim) if layer_norm else None
def forward(self, X):
residual = X
# step01: linear projection
query = self.W_q(X)
key = self.W_k(X)
value = self.W_v(X)
# split by heads: h(head갯수)개로 분리
batch_size = query.size(0)
query = query.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
key = key.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
value = value.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# step02: (scaled dot product attention) * h개 진행
output, attention = self.dot_attention(query, key, value, scale=self.scale)
# step03: (concat heads)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.head_dim)
# step04: (residual connection)
if self.W_res is not None:
residual = self.W_res(residual)
if self.use_residual:
output += residual
# step05: (linear)
if self.layer_norm is not None:
output = self.layer_norm(output)
# step06: relu
# (해당 부분은 기존 attention에 없으며 autoint의 residaul로 인해 추가된 사항)
output = output.relu()
return output
모델: Class AutoInt
# input: feature_map
# input: embedding_dim
# step01: Input 넣은 후 X와 y로 분리
# step02: Embedding Layer
# step03: Interacting Layer(attention layer)
# step04: linear → (output: y_pred)
# step05: (존재시 진행) Embedding Layer를 거친 값 → MLP Layer (y_pred에 해당 값 +)
# step06: (존재시 진행) Input X → LR Layer (y_pred에 해당 값 +)
# step07: (존재시 진행) y_pred → output_activation (y_pred에 해당 값 +)
class AutoInt(BaseModel):
def __init__(self,
feature_map,
model_id="AutoInt",
gpu=-1,
task="binary_classification",
learning_rate=1e-3,
embedding_dim=10,
dnn_hidden_units=[64, 64, 64],
dnn_activations="ReLU",
attention_layers=2,
num_heads=1,
attention_dim=8,
net_dropout=0,
batch_norm=False,
layer_norm=False,
use_scale=False,
use_wide=False,
use_residual=True,
embedding_regularizer=None,
net_regularizer=None,
**kwargs):
super(AutoInt, self).__init__(feature_map,
model_id=model_id,
gpu=gpu,
embedding_regularizer=embedding_regularizer,
net_regularizer=net_regularizer,
**kwargs)
self.embedding_layer = **EmbeddingLayer**(feature_map, embedding_dim)
self.lr_layer = **LR_Layer**(feature_map, output_activation=None, use_bias=False) \
if use_wide else None
self.dnn = **MLP_Layer**(input_dim=embedding_dim * feature_map.num_fields,
output_dim=1,
hidden_units=dnn_hidden_units,
hidden_activations=dnn_activations,
output_activation=None,
dropout_rates=net_dropout,
batch_norm=batch_norm,
use_bias=True) \
if dnn_hidden_units else None # in case no DNN used
self.self_attention = nn.Sequential(
*[**MultiHeadSelfAttention**(embedding_dim if i == 0 else attention_dim,
attention_dim=attention_dim,
num_heads=num_heads,
dropout_rate=net_dropout,
use_residual=use_residual,
use_scale=use_scale,
layer_norm=layer_norm) \
for i in range(attention_layers)])
self.fc = nn.Linear(feature_map.num_fields * attention_dim, 1)
self.output_activation = self.get_output_activation(task)
self.compile(kwargs["optimizer"], loss=kwargs["loss"], lr=learning_rate)
self.reset_parameters()
self.model_to_device()
def forward(self, inputs):
"""
Inputs: [X, y]
"""
X, y = self.inputs_to_device(inputs) # input 넣으면 x와 y로 분리
feature_emb = self.embedding_layer(X) # Main Layer 1 (Embedding Layer)
attention_out = self.self_attention(feature_emb) # Main Layer 2 (Interacting Layer)
attention_out = torch.flatten(attention_out, start_dim=1)
y_pred = self.fc(attention_out) # fc(linear)
# Embedding Layer를 거친 값을 MLP를 거치게 함
if self.dnn is not None:
y_pred += self.dnn(feature_emb.flatten(start_dim=1))
# Input X를 LR Layer를 거치게 함
if self.lr_layer is not None:
y_pred += self.lr_layer(X)
if self.output_activation is not None:
y_pred = self.output_activation(y_pred)
return_dict = {"y_true": y, "y_pred": y_pred}
return return_dict
References
[논문]
- Transformer: Attention Is All You Need : https://arxiv.org/pdf/1706.03762.pdf
- **AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks:** https://arxiv.org/abs/1810.11921
[코드]
- 논문 저자 제공 코드(텐서플로우 ver1): https://github.com/deepgraphlearning/recommendersystems
- 패키지(파이토치) FUXI CTR : LR(07)~AOANet(2021)
https://github.com/xue-pai/FuxiCTR/tree/main/fuxictr/pytorch/modelshttps://github.com/xue-pai/FuxiCTR
Leave a comment