
[추천시스템] BERT4Rec: Sequential Recommendation with Bidirectional 설명
BERT4Rec: Sequential Recommendation with Bidirectional
Summary
이전 접근의 한계점
- left to right unidirectional model은 users’ behavior sequences를 파악하기 충분하지 않음
- GRU4Rec과 SASRec의 경우, 유저의 이전 행동 패턴만을 고려한 단방향 추천을 진행함
- 이러한 단방향 추천 모델의 유저가 과거에 구매한 아이템의 정보만으로 모델을 학습을 하게 됨
해당 모델의 제안점
1. propose a sequential recommendation model called BERT4Rec
- 이에 해당 모델은 양방향 self attention을 도입하는 것을 제안함
- which employs the deep bidirectional self-attention to model user behavior sequences
2. adopt the Cloze objective
- BERT의 학습방법처럼 유저의 행동 시퀀스에 대해 mask 토큰을 사용하여 양방향으로 mask의 정보를 파악할 수 있도록 함
- predicting the random masked items in the sequence by jointly conditioning on their left and right context. In this way, we learn a bidirectional representation model to make recommendations by allowing each item in user historical behaviors to fuse information from both left and right sides.
BERT4REC
Problem statement
\[p(v^{(u)}_{n_{u}+1} = v|S_{u})\]- user u의 상호작용한 item sequence인 interaction history $S_{u}$가 주어졌을 때, user u가 time step $n_{u}+1$에서 특정 item v와 상호작용할 probability를 modeling
Notation
-
$U = [{ u_{1},…,u_{ U } }]$ : users의 set - $V =[ v_{1},…,v_{V}]$ : items의 set
- $S_{u} = [ v_{1}^{u},…,v_{n_{u}}^{u} ]$ : user u의 상호작용한 item sequence
- $v_{t}^{(u)}$: time step t에서 u가 상호작용한 item
- $n_{u}$: user u의 interaction sequence의 총 길이
Model Architecture
BERT4Rec model architecture
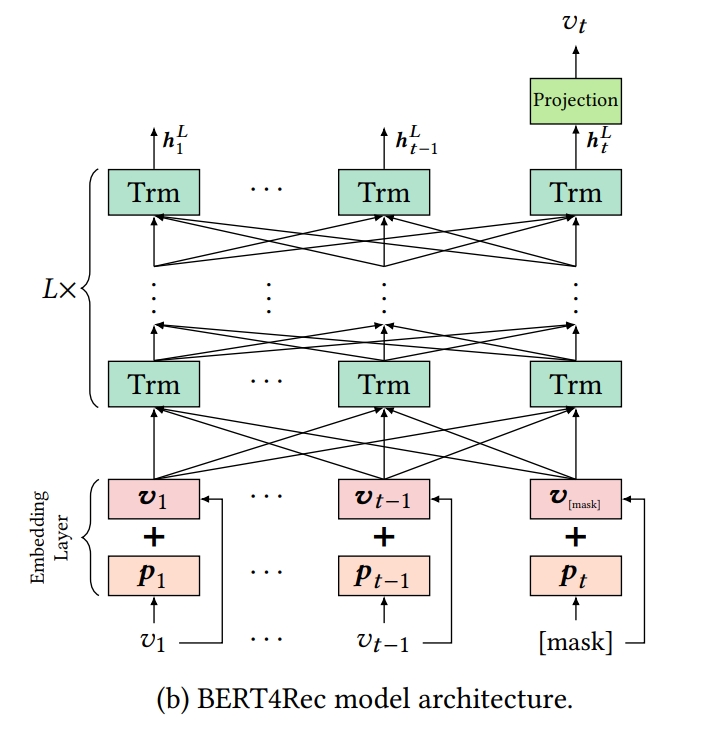
1) BERT4Rec은 Transformer Layer를 사용함
2) BERT4Rec은 L개의 bidirectional Transformer layers로 쌓여있음
3) 각 layer에서는 병렬적으로 이전 layer에서의 all positions의 information을 교환함으로써 every position의 representation을 iteratively하게 수정하며 학습을 진행함
- 이를 통해 any distances라도 직접적으로 dependencies를 capture할 수 있게 됨
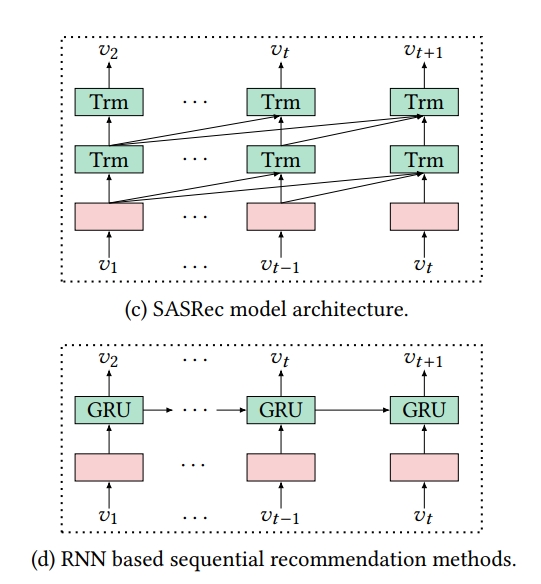
BERT4REC VS SASRec, RNN based, other model
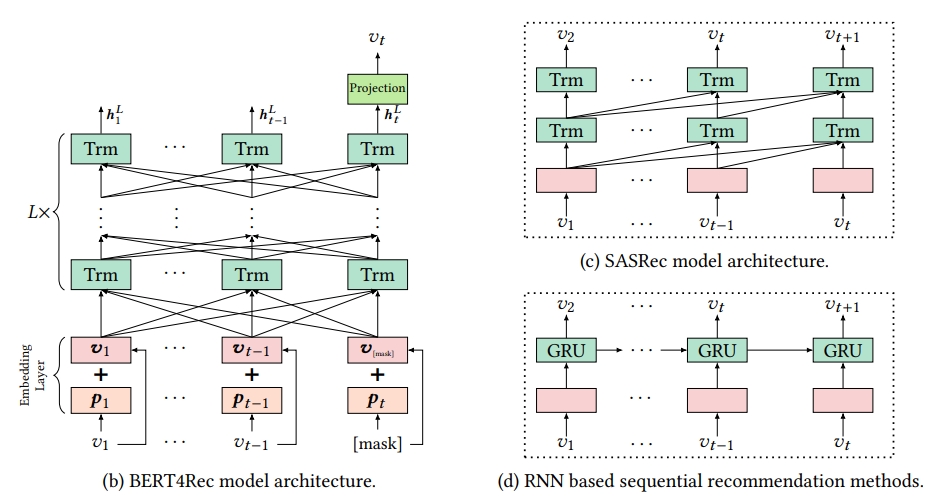
1. global receptive field
- CNN based의 Caser는 a limited receptive field
2. self-attention is straightforward to parallelize
- RNN based model과는 parallalize하지 않음
3. BERT4Rec uses bidirectional self-attention to model users’ behavior sequence
- SASRec and RNN based methods are all left-to-right unidirectional architecture
Embedding Layer
위치정보
- Transformer layer는 input seqeunce의 order를 알지 못함
- input의 seqeuntial information을 사용하기 위해, Positional Embeddings을 input item emebdding에 주입함
- 즉, Embedding Layer의 경우, 아이템의 정보와 아이템의 위치정보를 더해 mask와 함께 Transformer 모델의 입력을 들어가게 됨
- item $v_{i}$가 주어졌을 때, input representation $h^{0}_{i}$는 상응하는 item과 positional embeddings을 sum하여 생성됨
- $v_{i}$는 아이템 vi d-dimensional embeddings
- positional embedding matrix P는 모델이 input이 어느 부분인지에 대해 식별하게 해줌
Truncate & Padding
- 유저 시퀀스의 길이가 전체 시퀀스 길이인 N보다 크면 잘라내고 N보다 작으면 제로 패딩을 진행함
- senetence의 maximum length는 N으로 제한됨
- 그래서 t가 N보다 클때, input sequence $V =[ v_{1},…,v_{t}]$를 last N items $[v_{t-N+1}^{u},…,v_{t}]$로 truncate함
Transfomer Layer(Trm)
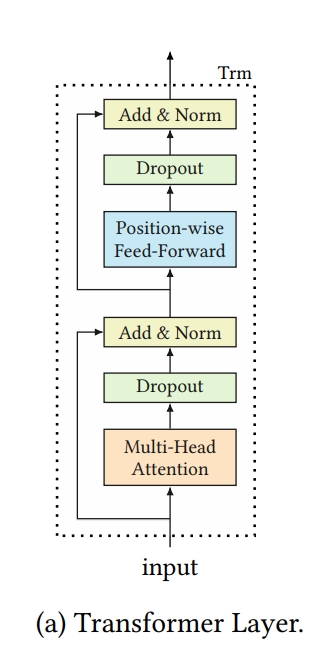
- length t의 input sequence가 주어졌을 때, 각각의 layer l 에서 각각의 postion i에 대해서 동시에 hidden representations인 $h_{i}^{l}$을 iteratively하게 compute함
-
all positions에 대해서 동시에 attention fuction을 계산하기 때문에 matrix $H^{l}$에 $h_{i}^{l}$을 stack함
- Transformer Layer의 경우, 기존 Transformer와 동일하게 2개의 sub layers를 갖는데 1) Multihead Attention 과 2) Point wise feed forward를 사용하며 레이어의 수 L만큼 반복 연산을 수행함
Multi-Head Self-Attention
- attnetion 매커니즘은 다양한 tasks에서 seqeunce modeling의 중요한 파트가 됨, sequences에서의 distance를 고려하지 않고 representation pairs 사이에서의 dependencies를 capturing하게 함
- 이전 작업들은 이런 방법이 different positions에서 different representation subpsaces로부터의 information을 attend하게 하는 장점이 있음
- 그러므로 여기서는 1개의 attention function을 사용하는 대신 multi head self attention을 사용하고자 함
- 특히, multi-head attention은 h subspaces에 선형적으로 $H^{l}$을 project함, different, learnable linear projections도 진행함 그리고 난 다음 h attention function을 parallel하게 적용하는데 이는 concat된 output representations을 생성하기 위해서임
Notation
\[MH(H^{l}) = [head_{1}; head_{2};, ...; head_{h}]W^{O}\] \[head_{i} = Attention(H^{l}W^{Q}_{i}, H^{l}W^{K}_{i},H^{l}W^{V}_{i})\] \[Attention(Q,K,V) = softmax(QK^{T}/\sqrt{d/h} )V\]- 각각의 head에 대한 projection matrices는 learnable parameters임
- projection parameters는 layers 간에 share되지 않음
- Q, K, V는 same matrix $H^{l}$으로부터 projected됨
- $\sqrt{d/h}$ 는 small gradients를 피라기 위해 softer attention distribution을 생성하기 위해 도입됨
Position-wise Feed-Forward Network
- PFFN은 attention sub-layer의 결과물에 대해 적용되는데 여러 dimension 사이에 존재하는 상호작용을 포착하고 비선형성을 강화해줌 → activation function으로 GELU를 사용함
- self-attention sub-layer은 linear projections에 기반함
- 모델에 nonlinearlity와 different dimensions 사이의 interaction을 강화하기 위해, self attention sub layer의 output에 Position-wise Feed-Forward Network를 each position에 각각 적용함
-
GELU를 사용함
\[PFFN*H^{l}) = [FFN(h^{l}_{1})^{T};...;FFN(h^{l}_{t})^{T}]^{T}\] \[FFN(x) = GELU(xW^{(1)} + b^{(1)})W^{(2} + b^{(2)}\] \[GELU(x) =x\Phi(x)\]- $\Phi(x)$은 cumulative distribution fucntion of standard gaussian distribution
- $W^{(1)}, W^{(2)}, b^{(1)}, b^{(2)}$ 는 all positions에서 share하고 learnable parameter임
- layer와 layer에서는 parameter가 다름
Stacking Transformer Layer
- self attention meachanism을 사용하여 전체 user behavior seqeunce를 통해 item-item interactions를 쉽게 capture할 수 있음
- self attention layer를 쌓음으로써 복잡한 item transition pattern을 학습하는데 장점이 있지만 학습하기 어려워짐
- 그래서 residual connection을 사용함
- 그리고 dropout도 사용함
BERT4Rec refines the hidden representations of each layer as follows
\[H^{l} = Trm(H^{l-1})\] \[Trm(H^{(l-1)} = LN(A^{l-1} + Dropout(PFFN(A^{(l-1)})))\] \[A^{l-1} = LN(H^{l-1} + Dropout(MH(H^{l-1})))\]- LN: layer normalization
Output Layer
- all postions에 대해서 이전 layer와 information을 교환하고 난 L번의 layer 후에, input seqeunce의 모든 아이템에 대해 final output $H^{L}$을 얻음
- time step t에서 item $v^{t}$를 mask하는 것을 가정할 때, masked items인 $v_{t}$를 figure (b)의 $h^{L}_{t}$ 에 근거하여 predict함
-
output layer에서는 trasformer 모델로부터 받은 final output $H^{L}$에 softmax를 취해 mask 토큰의 확률값을 구하게 됨
\[P(v) = softmax(GELU(h^{L}_{t}W^{P} + b^{P})E^{T} + b^{O})\] - 모델의 입력에 유저의 시퀀스 중 p의 비율만큼 mask를 수행하여 들어가게 되며, 출력으로는 mask된 아이템의 확률값이 나옴
- 실제 테스트 단계에서는 유저의 행동 시퀀스 마지막 부분에 mask를 사용하여 이후 진행할 추천할 아이템의 확률값을 계산함
Experiments
Datasets
- Amazon Beauty: 아마존의 리뷰 데이터셋
- Stream: online game platform에서 모은 데이터셋
- Movielens : ML-1m, ML-20m
Evaluation Metrics
- HR
- NDCG
- MRR
Baselines
-
POP
It is the simplest baseline that ranks items according to their popularity judged by the number of interactions.
-
BPR-MF
It optimizes the matrix factorization with implicit feedback using a pairwise ranking loss.
-
NCF
It models userâĂŞitem interactions with a MLP instead of the inner product in matrix factorization.
-
FPMC
It captures users’ general taste as well as their sequential behaviors by combing MF with first-order MCs.
- Caser:
- It employs CNN in both horizontal and vertical way to model high-order MCs for sequential recommendation.
- GRU4Rec
- It uses GRU with ranking based loss to model user sequences for session based recommendation.
- GRU4Rec+
- It is an improved version of GRU4Rec with a new class of loss functions and sampling strategy.
- SASRec
- It uses a left-to-right Transformer language model to capture users’ sequential behaviors, and achieves
overall performance comparison
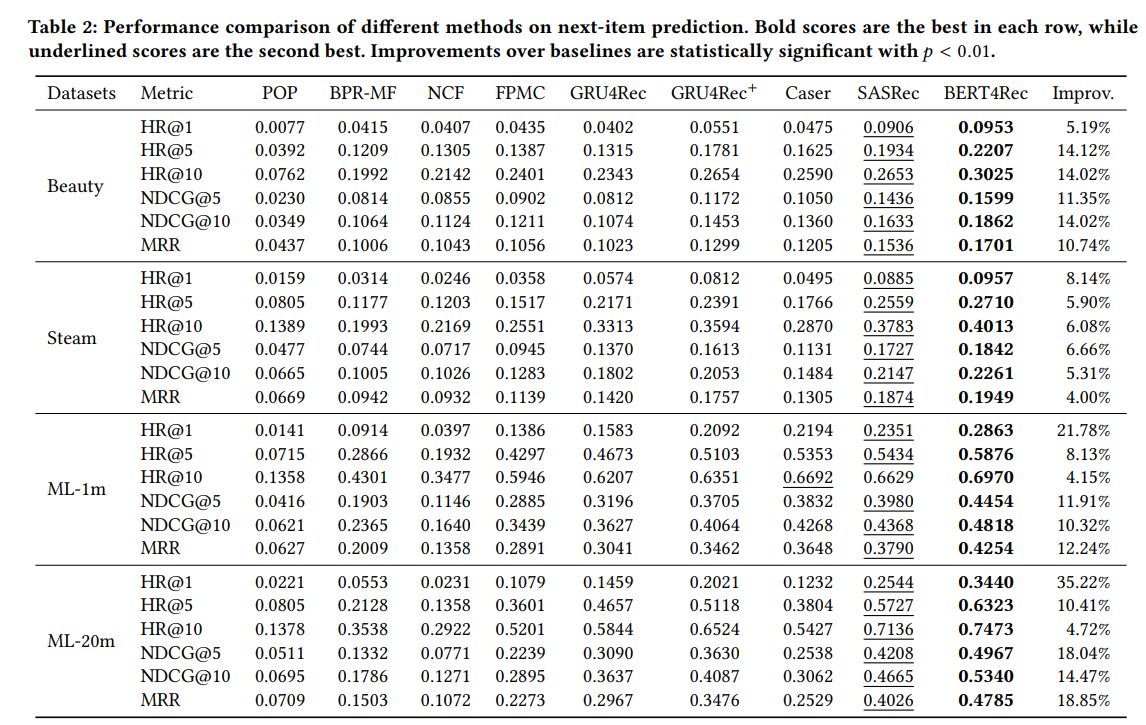
- 4개의 데이터셋에서 BERT4Rec이 가장 성능을 보임
1) 베스트셀러인 POP의 경우, 가장 좋지 않은 성능을 보임 → 개인 선호를 반영하지 못하기 때문
2) 베이스라인 모델들 중, sequential method인 FPMC와 GRU4Rec+는 non sequentail method인 BPR-MF와 NCF보다 성능이 좋음
- BPR-MF와 비교하여 FPMC의 개선점은 sequential한 방법으로 user의 historical records를 모델링하는 것임
3) sequential baselines 중에서는 Caser가 FPMC보다 성능이 좋은데 특히 dense한 dataset ML-1m에서 좋음
- 이는 high-order MCs는 sequential recommendation에서 좋다는 것을 보여줌
- 하지만 high order MCs는 보통 적은 L을 사용하는데 이 때문에 GRU4Rec+나 SASRec보다 Caser가 성능이 좋지 않음(특히 sparse dataset에서)
4) SASRec은 GRU4Rec과 GRU4Rec+보다 성능이 좋음
- self attention이 sequential recommendation에서 강력하기 때문
5) 이러한 결과를 통해 BERT4Rec은 4개 데이터셋에서 가장 좋은 성능을 보임
- 7.24% HR@10, 11.03% NDCG@10, and 11.46% MRR improvements (on average) against the strongest baselines.
Impact
-
Impact of Hidden Dimensionality d
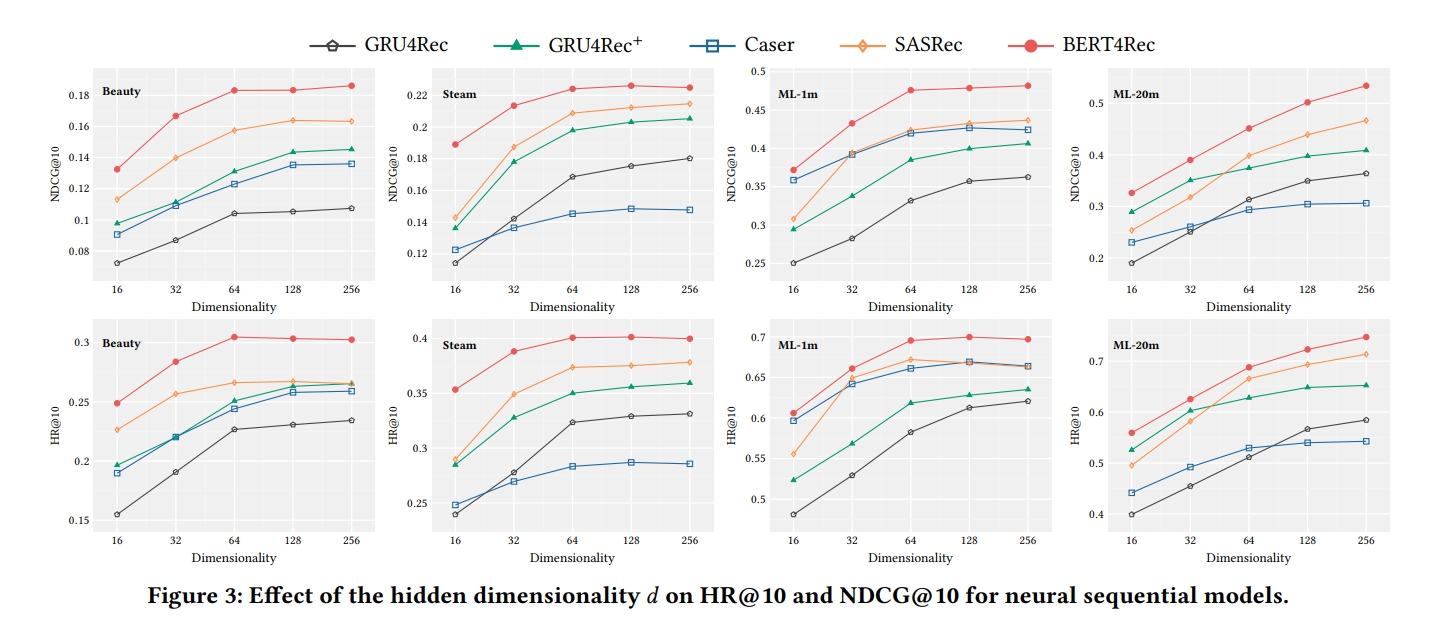
- dimension이 증가하면서 모델의 성능이 증가함을 볼 수 있음
- sparse dataset의 경우, larger hidden dimensionality는 더 나은 성능을 가져오는 건 아님(Beauty and Steam) → overfitting 문제로 보임
- self attention method인 SASRec과 BERT4Rec은 모든 데이터셋에서 superior 성능을 보임
-
Impact of Mask Proportion p
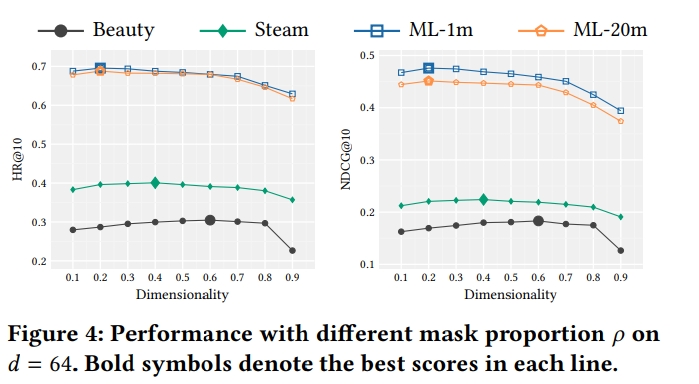
- mask proportion p는 key factor임
- mask p가 너무 적거나 커도 안됨
- 적으면 strong model을 학습하기 적합하지 않고,
- 너무 크면 context는 적은데 예측해야할 item이 너무 많아짐
- p가 0.6보다 크면 모든 데이터셋에서 성능이 떨어짐을 보임
- short sequence legnth에서는 베스트가 0.6이고(beauty steam)
- long sequence에서는 p가 0.2가 좋음(ml)
-
Impact of Maximum Sequence Length N
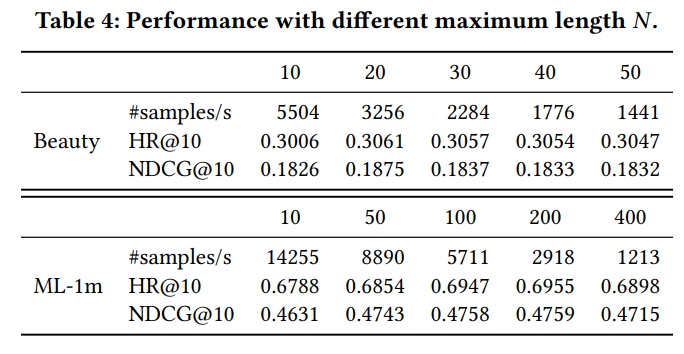
- N에 따른 성능과 학습속도
- 적절한 최대 N은 dataset의 sequence length의 평균에 의존함
- Beauty는 N=20보다 적은게 좋고, ML-1m은 N=200일 때 가장 좋은 성능을 보임
- 이는 user의 behavior가 short sequence에서는 more recent한 item에 더 영향을 많이 받는다는 것을 의미함
- larger N은 extra information을 가지게 됨
- BERT4Rec은 N이 커짐에 따라 성능이 함께 안정적으로 상승함
- 이는 제안 모델이 noisy historical records로부터 informative item을 찾아낼 수 있음을 의미함
CONCLUSION
- BERT4Rec은 유저의 행동 패턴만을 바탕으로 시퀀셜 추천을 위한 end-to-end 방식의 추천 모델로 차별점
Leave a comment