
[추천시스템] CTR을 위한 추천모델(발전단계/LR/Poly2/MF/FM/FFM/W&D/DeepFM)
CTR 모델
- context aware에서 대표적인 모델연구가 많이 되고 있고, CTR 높이려고 하는 회사에서 많이 관심을 가지고 있음
- 대표적인 모델 FM - W&D - NFM - DeepFM - DCN - DCN V2
CTR 분야의 의미
- 광고추천에서의 CTR: 특정 웹사이트에서 광고를 보여줄 때 클릭될 확률을 예측하는 태스크
- CTR = clicks/ impressions
- impressions: 특정한 사람들에게 광고를 보여주는 숫자
- clicks: 클릭한 숫자
- 이 사람의 context에 맞게 어떤 시점에 어떤 경로로 들어왔는지를 잘 알고 , 어떤 것을 클릭했는지를 보고 수많은 광고에서 클릭 많이 할 시점을 찾는 것임
- 해당 분야의 대표 모델은 FM이고 근본은 linear model임
- FM은 MF의 일반화 모델로 context feature를 사용하는 모델
CTR 분야 모델의 발전단계
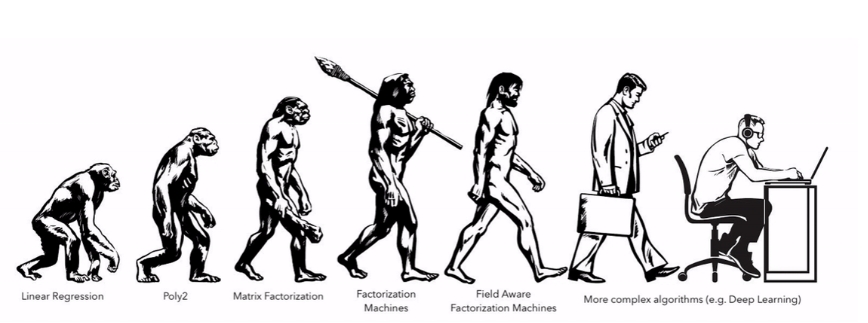
위의 그림은 추천시스템의 Linear model에서부터 deep recommender model까지의 진화과정을 보여준다.
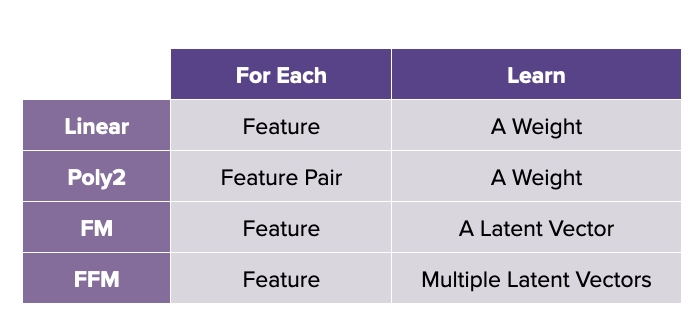
1) Linear Regression
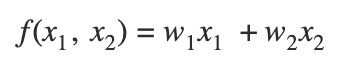
- user, movie 정보를 one hot으로 표현해서 linear 모델로 표현한 형태
- 앨리스의 가중치와 다크나이트 가중치로 평점을 예측
- 두 개의 one hot vector를 concat해서 하나의 input vector로 표현하고 최종적으로 binary vector로 표현됨
- MF와 다른 점은 MF에서는 user와 item을 임의의 벡터로 바꿔서 벡터의 내적을 하는데 Linear Regression에서는 Factorization 없이 한 것
- 하나의 weight는 각각의 feature로 학습됨
- ex) 각각의 feature(User1, Item1, User_Attribute1)로 학습
- 한계점: USER1과 ITEM2 학습 하는게 맞는데 각각의 경우에는 클릭수가 높지 않은데 결합했을때 시너지 내는 경우가 있을 수 있는데 그런 결합된 효과를 학습할 수 없음
2) poly2
- linear model이 USER1과 ITEM2의 결합된 효과를 학습할 수 없기 때문에 이런 한계를 보완하기 위해 second order까지 고려하는 것이 polynomial model
- 하나의 weight는 각각의 feature pair로 학습됨
- ex) 각각의 feature pair(User1&Item1, User1&User_Attribute1, Item1&User_Attribute1)로 학습
- interaction은 전체 조합에 대한 정보 확보가 어려우므로 generalization 이슈 있을 수 있음
- 모든 가능한 interaction을 학습을 통해 표현하고자 함 → interaction의 갯수가 엄청 많아지며, USER1이 ITEM3을 보지 않았는데 weight를 학습하기 어려움 → 초기값에 영향을 받을 수도 있으며, 특정 유저가 많으면 그에 대한 biase가 생길 수 있음
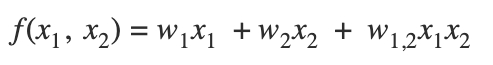
3) MF
- poly2의 경우, 모든 가능한 interaction 조합에 대해 각 weight이 균일하게 학습되어야 일반화 될 수 있는데 특정 sample에 bias될 수 있음
- 이를 보완하기 위해 파라미터를 다 학습하는게 아니라 실제로 interaction이 있는 케이스에 대하서만 줄여서 학습을 하는 것이 MF의 개념
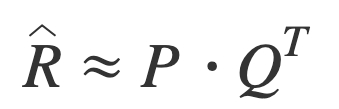
4) FM
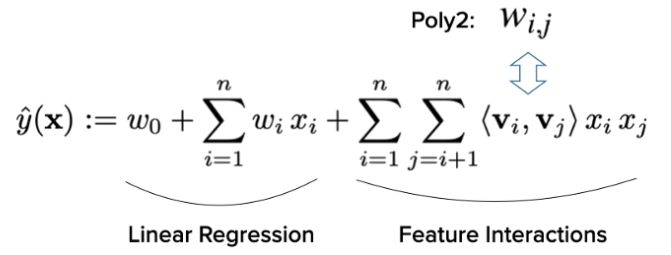
- FM은 second polonomial(Wi,j)을 V(i)와 V(j)의 두 벡터의 내적으로 표현함
- 주어진 mf feature만 가지고 polinomial을 표현한 것을 factorization을 적용하면 우리가 아는 matrix factorization 모델로 환원됨
- User1과 Item3의 샘플이 없더라고 해도 User1과 Item3에 대한 latent factor가 있기 때문에 User1과 Item3이 다른 샘플로 학습이 된다면 reliable한 예측이 가능함
- FM은 MF의 일반화 모델로 context feature 사용이 가능함
- FM을 일반화 한다면 user와 item의 side feature가 있을 때 one hot vector로 표현이 가능함 → 3개의 원핫 벡터를 concat되어 하나의 샘플의 입력으로 들어감
- rating 3을 맞출때 쓰는 정보는 user 가중치, item 가중치, 장르 가중치가 선형으로 들어가고 interaction은 두 벡터의 내적으로 표현 → 컨텐츠 피쳐까지해서 모델 일반화 가능
- (user, item, user_side feature)3개의 weight을 표현하는 건 poly2와 동일한데 모든 가능한 interaction weight를 따로 따로 표현하는게 아니라 interaction을 두 벡터의 내적으로 표현하여, 각각의 feature는 하나의 latent vector를 가짐
- 지금은 선형으로 interaction이 되는데 최근에는 non linear, 내적이 아닌 임의의 뉴럴네트워크로 적용하는 식으로 개선함가지고 있는 정보가 user, item, location, time, language → 2개가 아닌 3,4차 방정식으로 확장이 가능함 → 모델의 표현력이 높아지지만 쉽게 오버피팅 될 수 있음 → residual link 방식을 사용함
- high order는 성능이 엄청 좋아지지 않을 수도 있고 또는 속도 이슈 있을 수 있음
5) FFM
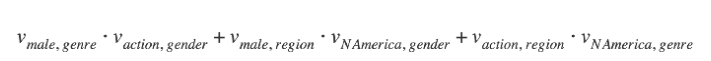
- 문제점이 될 수 있는게 두 벡터 내적했는데 USER1ITEM2의 Interaction과 USER1ITEM4에서 USER1의 weight를 공유해서 쓰는데 다른 interaction인데 공유해서 쓰는게 효과적인가에 대한거고 그래서 나온게 field aware fm임 → 중복사용하지 않고 구분해서 사용하고자 함
- FFM은 필드 수만큼 증강시킴
- field는 feature의 집합인데 같은 타입을 가짐
- 각 필드마다 서로 다른 필드마다 다른 벡터를 둬서 계산함 → 데이터가 충분히 없으면 FFM 성능이 떨어질 수 있음 → 데이터 많으면 flexible하게 학습이 됨
-
각각의 feature에는 multiple latent vector가 있음
6) Wide & Deep
- poly2 = wide모델
- 1) wide는 모든 가능한 조합에 대한 weight를 한번에 학습: A,B 필드의 모든 가능한 조합들을 고려해서 이들에 대해 최종 결과가 어떻게 되는지 보겠다는 것
- 모든 가능한 interaction 학습 → cross product → 오버핏이 되더라도 학습을 하겠다. 패턴을 다 기억하려 함
- 2) deep은 훨씬 더 복잡한 패턴을 학습하겠다는 것: 내적 이외 복잡한 패턴을 잘 학습해서 interaction이 충분하지 않더라도 둘의 관계를 확실하게 학습하겠다
- generalization, 내적 이외 복잡한 패턴을 잘 학습해서 interaction이 충분하지 않더라도 둘의 관계를 확실하게 학습하겠다
- 기대하는 바는 direct한 feature interaction이 있으면 wide모델로 성능을 높이고, 없으면 deep 모델로 둘의 interaction을 표현해서 예측하라
7) DeepFM
- FM모델과 MLP 합친 형태
- Wide모델은 poly2인데 오버핏 될 수 있는 부분을 그 부분을 FM으로 함
- 성능면에서 DeepFM이 Wide&Deep보다 좋음
- CTR 관련된 모델 중 DeepFM을 baseline으로 선택하는게 좋음
- 각 필드가 있으면 필드별로 임베딩 레이어를 통과시켜서 dense vector로 변환하는 부분이 있음
- e(1)~e(f)가 dense vector임 → 편의상 임베딩 디멘젼은 편의상 같게 만듦
- dense vector(embedding)을 concat한 형태이고 FM layer는 e(1)에서 e(f)까지의 second order interaction을 고려한 FM 모델을 돌림
- MLP 부분은 e(1)~e(f) concat을 하고 → w와 b를 여러개 쌓아서(layer) → DNN모델로 적용
- WD의 Wide의 경우, feature engineering을 통해서 어떤 피쳐의 Wide 모델을 만들 것이냐를 고민하게 되는데 DeepFM에서는 Wide→FM으로 대체되기 때문에 feature engineering 없이도 end to end학습이 가능하고 이렇게 하는 것이 성능면에서도 좋음
8) NFM
- 모델이 아주 크게 다르진 않고 성능이 항상 좋진 않음, 기존 FM의 interaction을 좀 더 일반화했다는 것에 의의가 있음
- FM은 second order만 고려하는데 여기서는 좀 더 high order에 대해서도 고려할 수 있게 확장해보자라고 이야기를 함: FM layer을 만들고 난 후 MLP layer를 쌓는다고 함 , FM을 가지고 pre training을 하는 방법을 제안함
- 의미론적으로 보면 second order interaction에 대해 고려한 것인데 기존 FM에서는 내적을 하고 합산을 해서 기존 FM과 동일한 결과임
- 추가적으로 더 하고 싶었던 건 GMF의 모델을 보면 element wise product한 후 3개에 대해 가중치를 다르게 합치는데 여기서도 중간 레벨의 가중치를 다르게 해서 FM과 같을 수도 다르게도 만들 수 있게 됨
References
[이론]
Leave a comment