
[추천시스템] DeepFM(개념/수식/구현 코드/튜토리얼)
2002.DeepFM(개념/수식/구현 코드/튜토리얼)
위의 그림은 추천시스템의 Linear model에서부터 deep recommender model까지의 진화과정을 보여준다.
1. DeepFM 모델 요약
- FM(선형) + MLP(비선형)
- Wide 부분을 FM으로 대체한 형태(Wide모델은 poly2인데 오버핏 될 수 있는 부분을 그 부분을 FM으로 대체함)
- 성능면에서 DeepFM이 Wide&Deep보다 좋음
- FM 류 중에 DeepFM과 DCN이 괜찮은 모델이라고 함
- CTR 관련된 모델 중 DeepFM을 baseline으로 선택하는게 좋음
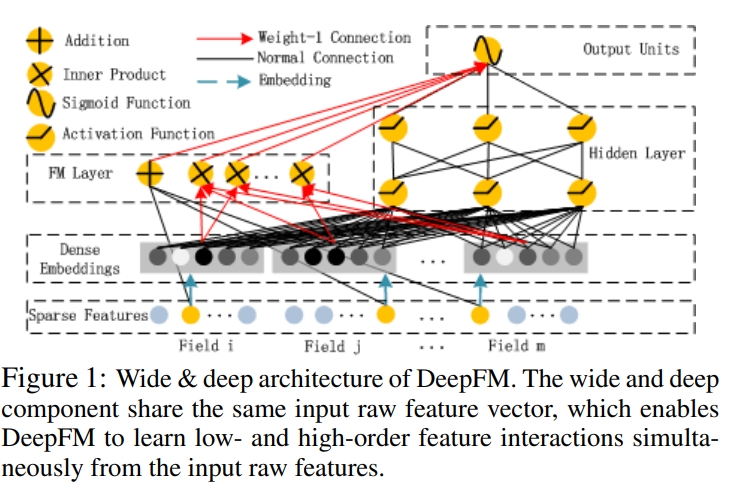
(1) 임베딩 레이어
- 각 필드가 있으면 필드별로 임베딩 레이어를 통과시켜서 dense vector로 변환하는 부분이 있음
- e(1)~e(f)가 dense vector임 → 편의상 임베딩 디멘젼은 편의상 같게 만듦
- numerical feature는 가져다 붙이는 형식으로 하고 있음, 하나의 레이어를 통과시키는 식임
(2) FM
- dense vector(embedding)을 concat한 형태이고 FM layer는 e(1)에서 e(f)까지의 second order interaction을 고려한 FM 모델을 돌림
- X(j)와 X(k)는 하나 하나의 벡터임 X(j)=e(j), X(k)=e(k)의 dense vector이고 그 둘의 가중치를 표현한 부분이 W(jk)
(3) MLP 부분
- MLP 부분은 e(1)~e(f) concat을 하고 → w와 b를 여러개 쌓아서(layer) → DNN모델로 적용
- 많이 쌓아야 3개고 1~2개임, 더 많이 쌓으면 성능 오버핏되는 경향이 있어 많이 쌓지 않음
2. DeepFM 모델의 구조 및 수식
1) Deep FM 구조
-
wide and deep component는 같은 input raw feature vector를 공유함
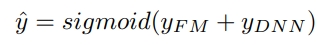
-
Y(FM)은 FM component의 output이고, Y(DNN)은 deep component의 output임
2. FM Component
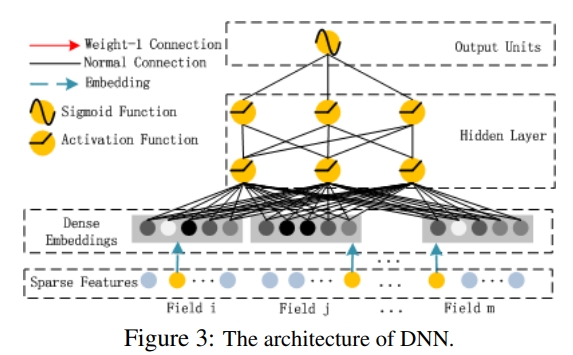
-
linear(order1) ineteractions과 pairwise(order2) interactions을 모델링함
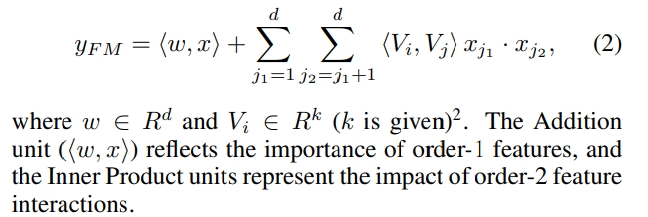
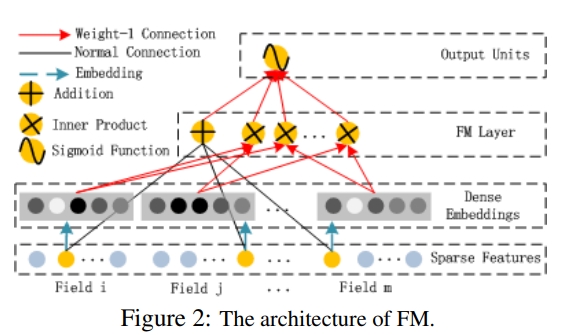
- FM은 addition unit과 Inner Product unit으로 구성됨
- addition unit(<w,x>)는 order 1 feature의 importance를 반영하고
- Inner Product units<V(i),V(j)>은 order 2 feature interactions을 표현함
- V(i)는 FM에서는 2차원 interaction을 모델링하며, Deep에서는 고차원 피처 interaction을 모델링함
3. Deep Component
- deep component는 high order feature interaction을 학습하기 위해 사용되는 feed forward neural network임
- input vector를 low dim의 dense vector로 만들기 위해 임베딩 레이어를 사용함
4. Embedding layer
1) input field vectors의 길이가 다르지만, 임베딩은 같은 사이즈임
2) FM의 latent factor vectors(V)는 network weights로 사용됨, 이는 학습되고, input field vectors를 임베딩 벡터로 압축하는데 사용됨
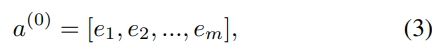
- 임베딩 레이어의 output
- e(i): i번째 field의 임베딩이며, m은 fields의 갯수임
-
a(0)은 deep neural network에 사용되며, forward process는 다음과 같음
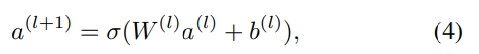
- l은 layer의 depth
- σ는 activation function
- a(l)은 lth layer의 output
- W(l)은 lth layer의 model weight
-
b(l)은 lth layer의 bias
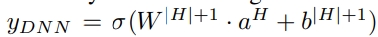
- dense한 실수 피처 벡터가 사용되면 최종적으로 sigmoid 함수에 들어감
-
H 는 hidden layers의 갯수 - FM component와 Deep component는 같은 feature 임베딩을 공유함
- 이는 2가지 이점을 가지는데 1) low와 high order feature interactions을 함께 학습할 수 있음 2) Wide&Deep에서 필요했던 피처 엔지니어링이 필요없음
3.DeepFM 모델의 장점
- WD의 Wide의 경우, feature engineering을 통해서 어떤 피쳐의 Wide 모델을 만들 것이냐를 고민하게 되는데 DeepFM에서는 Wide→FM으로 대체되기 때문에 feature engineering 없이도 end to end학습이 가능하고 이렇게 하는 것이 성능면에서도 좋음
4.DeepFM 모델의 성능
- 성능을 보면 Criteo 데이터 보니 DeepFM이 가장 좋은 성능을 보임
- FM&DNN → FM과 DNN의 학습을 따로 따로 하고 prediction할 때만 앙상블을 함(처음부터 끝까지 joint learning함→ 이 모델을 end to end로 학습함, 이 둘을 합칠 때 알파와 1-알파는 학습에 의해 결정됨 → joint learning은 학습 기반으로 weight이 결정되어 우수하다고 알려짐, 근데 하다보면 따로 따로 한 뒤 inference 하는게 우수할 수 있음 )
5. Pytorch 구현: From Scratch
5.1 데이터 설명
- 데이터는 클릭 문제를 다룰 때 많이 사용하는 Criteo Data를 활용하였으며, 이곳에서 다운로드할 수 있다.
- 카테고리 컬럼: 26개
- 숫자 컬럼: 13개
- 타겟컬럼명: label
- field의 갯수는 39개이다
5.2 데이터셋 로드 및 preprocess
import torch
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
########## criteo dataset ##########
torch.manual_seed(2022)
data = pd.read_csv('./criteo_sample.txt')
# 1. category, numeric col 정의
category_cols = ['C' + str(i) for i in range(1, 27)]
numeric_cols = ['I' + str(i) for i in range(1, 14)]
data[category_cols] = data[category_cols].fillna('-1', )
data[numeric_cols] = data[numeric_cols].fillna(0, )
target_col = ['label']
# 2.Label Encoding for sparse features,and do simple Transformation for dense features
# 카테고리 컬럼 레이블 인코딩으로 카테고리 피처를 코드형 숫자 값으로 변환
for feat in category_cols:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
# 연속형 컬럼 scaling
mms = MinMaxScaler(feature_range=(0, 1))
data[numeric_cols] = mms.fit_transform(data[numeric_cols])
5.3 모델에 맞게 DataSet 구성
data_massage
- data_massage 함수는 카테고리 컬럼과 연속형 변수를 인자로 넣어주면, field_size를 생성하는데 연속형 변수면 field_size에 1, 카테고리 컬럼이면 해당 컬럼 값의 unique한 수치를 넣어준다
- field size에 맞게 start_idx를 리턴한다
FMDataset
- FMDataset은 전체 변수별 index를 생성하고(idxs), 값을 넣어줌(vals)
def data_massage(data, category_cols, numeric_cols):
feat_cols = numeric_cols + category_cols
fields_size = []
for feat_col in feat_cols:
if feat_col not in category_cols: # numeric이면 field_size가 1
fields_size.append(1)
else: # category면 field_size 컬럼 값 갯수
fields_size.append(data[feat_col].nunique())
start_idx = [0] + np.cumsum(fields_size)[:-1].tolist() # field size에 맞게 start_idx 계산
return feat_cols, start_idx, fields_size
feat_cols, feat_start_idx, fields_size = data_massage(data, category_cols, numeric_cols)
class FMDataset(Dataset):
def __init__(self, data, feat_start_idx, fields_size, feat_cols, target_col):
self.data = data
self.label = np.asarray(self.data[target_col])
self.feat_cols = feat_cols
self.fields = fields_size
self.start_idx = feat_start_idx
def __getitem__(self, index):
row = self.data.loc[index, self.feat_cols] # 컬럼과 해당 인덱스 값
idxs = list()
vals = list()
label = self.label[index]
# 테이블의 변수갯수만큼 idx 및 vals 생성
for i in range(len(row)):
if self.fields[i] == 1: # filed_size가 1이면 numeric
idxs.append(self.start_idx[i])
vals.append(row[i])
else: # field size가 1이 아니면 category
idxs.append(int(self.start_idx[i] + row[i])) # 인덱스값: 변수 N번째의 경우, N번째의 필드 시작 인덱스 + Input 데이터의 N번째 변수의 값
vals.append(1)
# N번째 필드 시작 인덱스가 0 & input 데이터가 N번째 라벨값이 1인 경우 -> 해당 인덱스는 1이 되고 값은 1이 됨 -> 인덱스 1번/값 1
# N번째 필드 시작 인덱스가 0 & input 데이터가 N번째 라벨값이 3인 경우 -> 해당 인덱스는 4이 되고 값은 1이 됨 -> 인덱스 4번/값 1
label = label.squeeze()
label = torch.tensor(label, dtype=torch.float32)
idxs = torch.tensor(idxs, dtype=torch.long)
vals = torch.tensor(vals, dtype=torch.float32)
return label, idxs, vals
def __len__(self):
return len(self.data)
5.4 모델 빌드
- 전체 구조: FM + DEEP
- 1.FM COMPONENT: LINEAR TERM(1차원) + CROSS_TERM(2차원)
- 2.DEEP COMPONENT: EMBEDDING LAYER로 압축하여 저차원 DENSE 실수 벡터를 만듦
- 1) w(i): i번째 피처에 대한 스칼라, i차원 importance 측정
- 2) V(i): LATENT VECTO, 다른 피처들과의 INTERACTION 영향(-> FM에서 2차원 INTERACTION 모델화 & -> DEEP에서 고차원 피처 INTERACTION 모델화)
- 1) FM COMPONENT (linear_term + cross_term)
- linear_terms (first order part)
- cross_term (second order part)
- 2) DEEP COMPONENT
- 3): 1) + 2) FM COMPONENT(FIRST_ORDER + SECONDE_ORDER) + DEEP COMPONENT
from multiprocessing.sharedctypes import Value
import os
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
torch.random.manual_seed(2022)
class DeepFM(nn.Module):
def __init__(self, args) -> None:
super(DeepFM, self).__init__()
os.environ['CUDA_VISIBLE_DEVICES'] = args['gpuid']
self.lr = args['lr']
self.l2_reg = args['l2_reg']
self.epochs = args['epochs']
self.num_fetures = args['num_features'] # f: 원본 feature 개수
self.emb_dim = args['embedding_dim'] # k: 임베딩 벡터의 차원(크기)
self.feature_embs = nn.Embedding(sum(args['field_size']), args['embedding_dim'])
self.bias_embs = nn.Embedding(sum(args['field_size']), 1)
# self.num_layers = args['num_layers'] # 2
self.deep_neurons = args['dense_size']
self.early_stop = True
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.batch_norm = args['batch_norm']
self.opt = args['opt_name']
if args['deep_layer_act'] == 'relu':
self.deep_layer_act = nn.ReLU()
else:
raise ValueError('Invalid activation function name for deep layers')
self.dropout_fm_1o = nn.Dropout(p=args['1o_dropout_p'])
self.dropout_fm_2o = nn.Dropout(p=args['2o_dropout_p'])
deep_modules = []
layers_size = [self.num_fetures * self.emb_dim] + args['dense_size']
# 1) Deep Component
for in_size, out_size in zip(layers_size[:-1], layers_size[1:]):
deep_modules.append(nn.Linear(in_size, out_size))
if self.batch_norm:
deep_modules.append(nn.BatchNorm1d(num_features=out_size))
deep_modules.append(self.deep_layer_act)
deep_modules.append(nn.Dropout(p=args['deep_dropout_p']))
self.deep = nn.Sequential(*deep_modules)
self.output = nn.Linear(args['dense_size'][-1] + self.num_fetures + self.emb_dim, 1, bias=False) # concat projection
self._init_weights()
def _init_weights(self):
nn.init.normal_(self.feature_embs.weight, std=0.01)
glorot = np.sqrt(2.0 / (self.num_fetures * self.emb_dim + self.deep_neurons[0]))
for la in self.deep:
if isinstance(la, nn.Linear):
nn.init.normal_(la.weight, std=glorot)
nn.init.constant_(la.bias, 0.)
glorot = np.sqrt(2.0 / (la.weight.size()[0] + la.weight.size()[1]))
glorot = np.sqrt(2.0 / (self.deep_neurons[-1] + self.num_fetures + self.emb_dim + 1))
nn.init.normal_(self.output.weight, std=glorot)
def forward(self, idxs, vals): # idx/vals: batchsize * feature_size
# 전체 구조: FM + DEEP
# 1.FM COMPONENT: LINEAR TERM(1차원) + CROSS_TERM(2차원)
# 2.DEEP COMPONENT: EMBEDDING LAYER로 압축하여 저차원 DENSE 실수 벡터를 만듦
# 1) w(i): i번째 피처에 대한 스칼라, i차원 importance 측정
# 2) V(i): LATENT VECTO, 다른 피처들과의 INTERACTION 영향(-> FM에서 2차원 INTERACTION 모델화 & -> DEEP에서 고차원 피처 INTERACTION 모델화)
# new_inputs: w와 inputs(vals)에 대한 multiply
feat_emb = self.feature_embs(idxs)
feat_emb = torch.multiply(feat_emb, torch.reshape(vals, [feat_emb.size(0), feat_emb.size(1), 1]).expand([feat_emb.size(0), feat_emb.size(1), self.emb_dim])) # batch_size * feature_size * embedding_size
# 1) FM COMPONENT (linear_term + cross_term)
# * linear_terms (first order part)
y_first_order = self.bias_embs(idxs) # batch_size * feature_size * 1
y_first_order = torch.multiply(y_first_order, torch.reshape(vals, [feat_emb.size(0), feat_emb.size(1), 1])) # batch_size * feature_size * 1
y_first_order = torch.sum(y_first_order, dim=2) # batch_size * feature_size
y_first_order = self.dropout_fm_1o(y_first_order) # batch_size * feature_size
# * cross_term (second order part)
# ** sum_of_square
summed_features_emb = torch.sum(feat_emb, 1)
summed_features_emb_square = torch.square(summed_features_emb)
# ** sqaure_of_sum
squared_features_emb = torch.square(feat_emb)
squared_sum_features_emb = torch.sum(squared_features_emb, 1) # batch_size * embedding_size
# ** cross_term
y_second_order = 0.5 * torch.subtract(summed_features_emb_square, squared_sum_features_emb) #summed_features_emb_square - squared_sum_features_emb
y_second_order = self.dropout_fm_2o(y_second_order) # dropout
# 2) DEEP COMPONENT
y_deep = feat_emb.view(feat_emb.size(0), -1)
y_deep = self.deep(y_deep) # nn.Sequential
# 1) + 2) FM COMPONENT(FIRST_ORDER + SECONDE_ORDER) + DEEP COMPONENT
concat_input = torch.cat([y_first_order, y_second_order, y_deep], dim=1) # batchsize * (embedding_size+feature_size+last_layer_out_size)
output = self.output(concat_input) # Linear
out = torch.sigmoid(output)
return out.view(-1)
def fit(self, train_loader, valid_loader=None):
if torch.cuda.is_available():
self.cuda()
else:
self.cpu()
if self.opt == 'adam':
optimizer = optim.Adam(self.parameters(), lr=self.lr)
elif self.opt == 'adagrad':
optimizer = optim.Adagrad(self.parameters(), lr=self.lr)
elif self.opt == 'sgd':
optimizer = optim.SGD(self.parameters(), lr=self.lr)
else:
raise ValueError(f'Invalid optimizer name: {self.opt}')
# criterion = nn.BCEWithLogitsLoss(reduction='sum') # CE_log_loss for binary classification
criterion = torch.nn.BCELoss(reduction='sum') # https://nuguziii.github.io/dev/dev-002/
last_loss = 0.
for epoch in range(1, self.epochs + 1):
self.train()
current_loss = 0.
total_sample_num = 0
for labels, idxs, vals in train_loader:
total_sample_num += labels.size()[0]
if torch.cuda.is_available():
labels = labels.cuda()
idxs = idxs.cuda()
vals = vals.cuda()
else:
labels = labels.cpu()
idxs = idxs.cpu()
vals = vals.cpu()
self.zero_grad()
# TODO remember to let batches in loader put on GPU or CPU
prediction = self.forward(idxs, vals)
loss = criterion(prediction, labels)
loss += self.l2_reg * self.output.weight.norm()
for la in self.deep:
if isinstance(la, nn.Linear):
loss += self.l2_reg * la.weight.norm()
if torch.isnan(loss):
raise ValueError(f'Loss=Nan or Infinity: current settings does not fit the recommender')
loss.backward()
optimizer.step()
current_loss += loss.item()
print(f'[Epoch {epoch:03d}] - training loss={current_loss / total_sample_num:.4f}')
delta_loss = float(current_loss - last_loss)
if (abs(delta_loss) < 1e-5) and self.early_stop:
print('Satisfy early stop mechanism')
break
else:
last_loss = current_loss
if valid_loader is not None:
self.eval()
# TODO if need valdiation
pass
def predict(self, test_loader):
self.eval()
_, idxs, vals = next(iter(test_loader))
idxs = idxs.to(self.device)
vals = vals.to(self.device)
preds = self.forward(idxs, vals).cpu().detach()
return preds
5.5 모델학습
-
모델 학습을 진행했고, 아래와 같은 결과가 나왔다


args = {
'batch_size': 256,
'gpuid': '0',
'lr': 0.001,
'l2_reg': 0.,
'epochs': 20,
'num_features': len(feat_cols),
'embedding_dim': 8,
'field_size': fields_size,
'dense_size': [32, 32],
'1o_dropout_p': 1.,
'2o_dropout_p': 1.,
'deep_dropout_p': 0.5,
'batch_norm': True,
'deep_layer_act': 'relu',
'opt_name': 'adam'
}
train_data, test_data = train_test_split(data, test_size=0.2)
train_data, test_data = train_data.reset_index(drop=True), test_data.reset_index(drop=True)
train_dataset = FMDataset(train_data, feat_start_idx, fields_size, feat_cols, target_col)
train_loader = DataLoader(train_dataset, batch_size=args['batch_size'], shuffle=True)
test_dataset = FMDataset(test_data, feat_start_idx, fields_size, feat_cols, target_col)
test_loader = DataLoader(test_dataset, batch_size=len(test_dataset))
model = DeepFM(args)
model.fit(train_loader)
model.predict(test_loader)
6. 패키지: deepctr
- 패키지는 이곳에서 확인할 수 있다.
- 같은 데이터에 대해서는 아래와 같은 결과가 나왔다.


!pip install deepctr
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.do simple Transformation for dense features
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.set hashing space for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=1000, embedding_dim=4, use_hash=True, dtype='string')
# since the input is string
for feat in sparse_features] + [DenseFeat(feat, 1, )
for feat in dense_features]
linear_feature_columns = fixlen_feature_columns
dnn_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns, )
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2, random_state=2020)
train_model_input = {name: train[name] for name in feature_names}
test_model_input = {name: test[name] for name in feature_names}
# 4.Define Model,train,predict and evaluate
model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=100, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
References
[논문]
https://arxiv.org/pdf/1703.04247v1.pdf
[이론]
[코드]
https://greeksharifa.github.io/machine_learning/2020/04/07/DeepFM/
https://github.com/AmazingDD/DeepFM-pytorch/blob/main/main.py#L5
Leave a comment