
[추천시스템] FiGNN (개념/수식/구현 코드)
[Fi-GNN] 코드 이해 및 분석
모델 설명
모델 개요
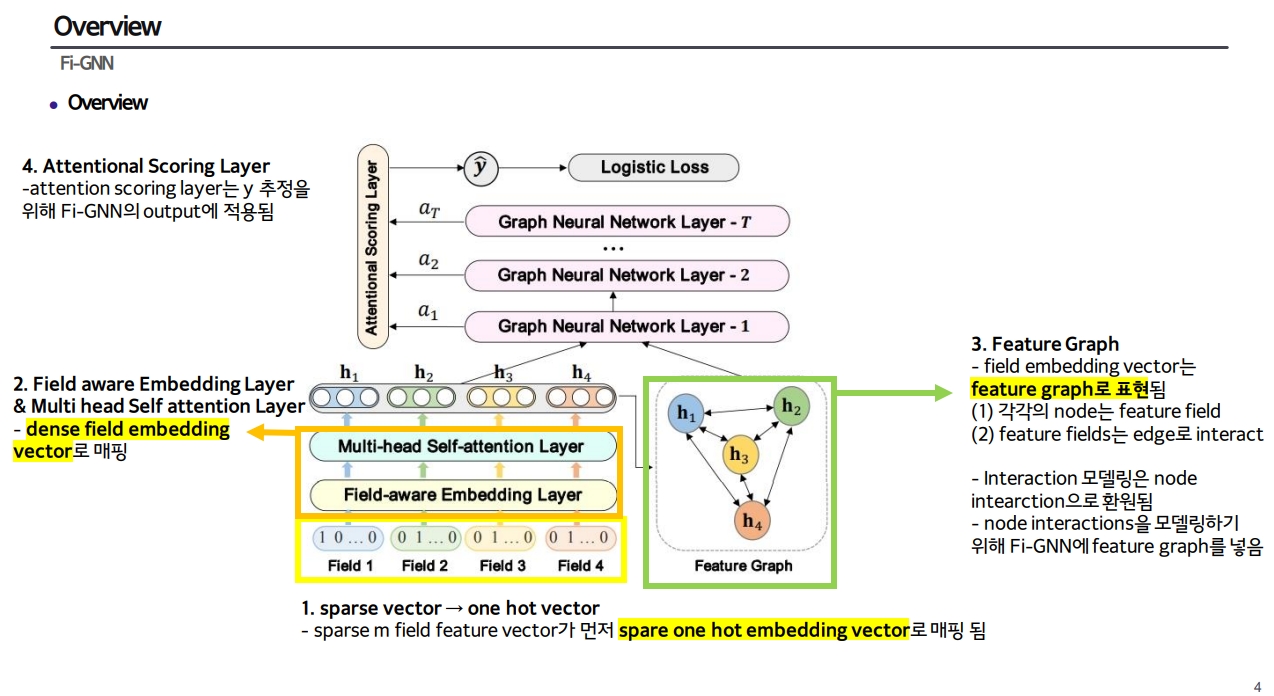
모델 구성
1) Field-aware Embedding Layer
- one hot vector → dense real value field
-
output: field embedding vector
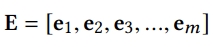
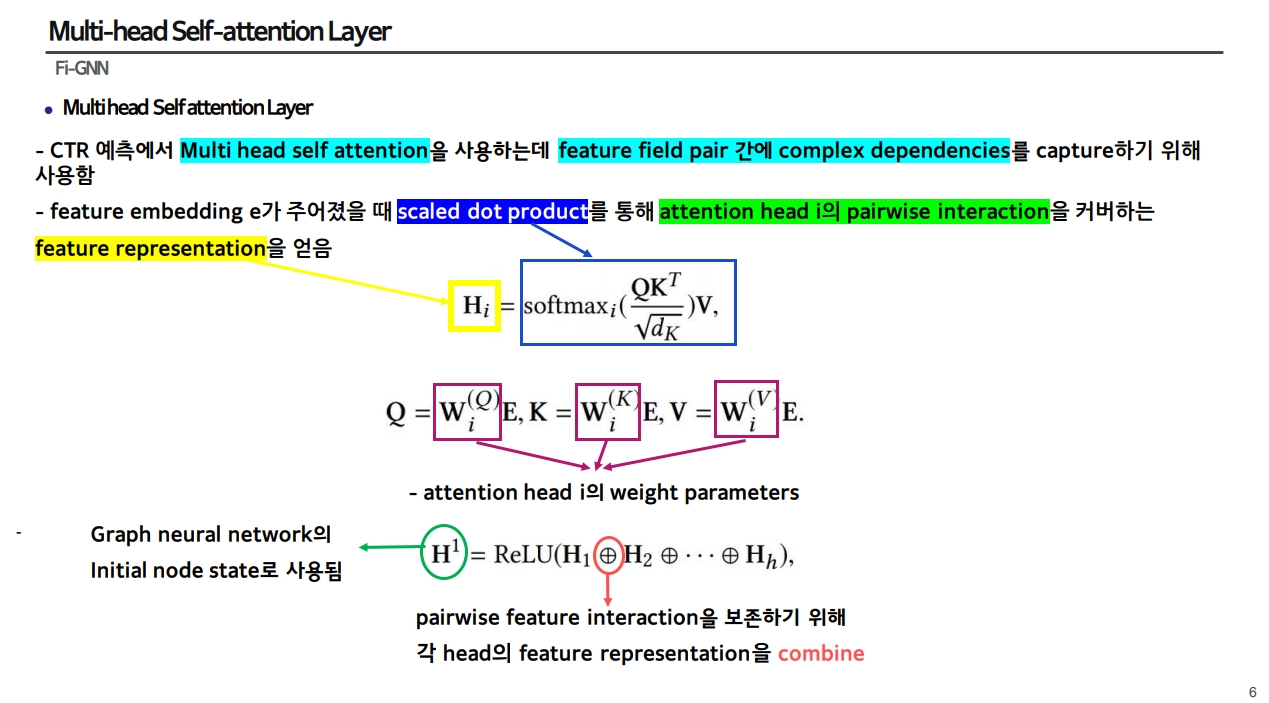
2) Multi-head Self-attention Layer
- feature field pair 간의 dependencies를 capture
- scaled dot product
-
output: attention head i의 pairwise interaction을 커버하는 feature representation
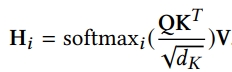
-
각 head의 feature representation을 combine한 것이 최종 output이며, graph neural network의 initial node state로 사용됨
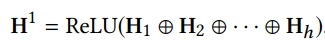
3) Feature Graph
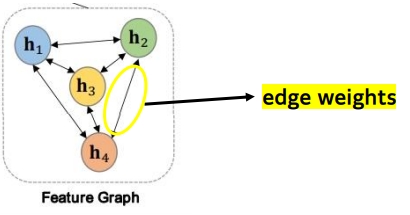
- multi-head self attention layer의 output을 model에 넣고 그래프 구조로 표현함
- edge weights는 feature interactions(node interaction)의 중요성을 반영함
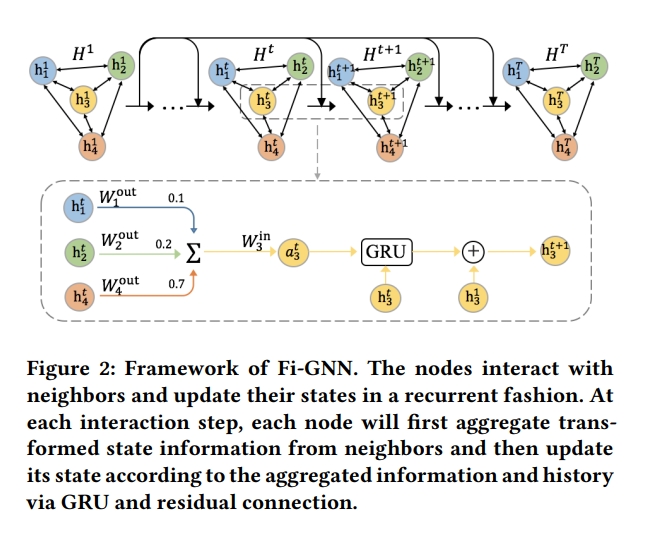
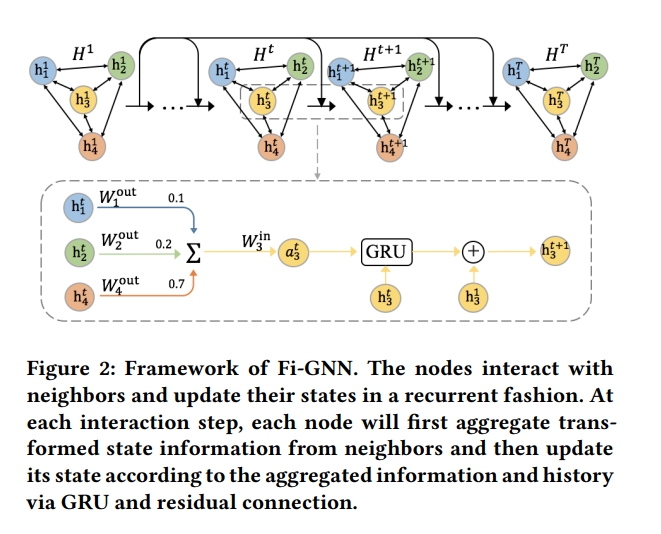
4) Feature Interaction Graph Neural Network
-
각각 node ni는 hidden state vector와 관계가 있으며, graph의 state는 node state로 구성됨
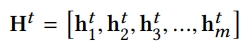
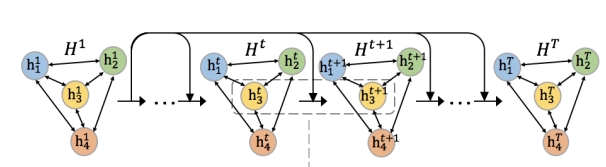
- Multi-head Self-attention Layer의 output인 H1이 initial node state로 사용되며, 노드들은 반복하여 states를 상호작용하여 업데이트함
- 각각의 interaction step에서 nodes는 이웃 node와 함께 transform된 state information을 aggregate함
- node interaction을 결정하는 것은 1) adjacency matrix 와 2) transformation function임
- edge-wise interaction을 목표로 하며, 각각의 edge에 대해 unique한 weight와 transformation function이 필요함
- output은 아래 식과 같은데 A는 노드 간의 edge weight(=interaction의 importance반영)이며, W는 transformation fuction임
-
이 output을 node i에 대한 aggregated state information으로 부름
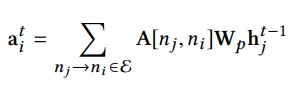
-
여기서 A를 단순 연결(1,0) 뿐만 아니라 관계 중요성을 보기 위해 attention mechanism을 활용하여 edge weight를 학습하고자 함
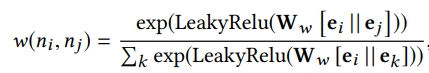
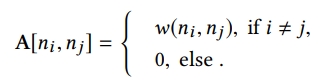
- 즉, edge weight를 나타내는 A에 attention mechanism을 활용하여 feature fields의 relation에 대한 good explanation을 제공할 수 있음
-
여기서 단순히 각각의 edge에 unique transformation weight를 할당하는 것은 space & time complexity가 높기 때문에 이를 줄이고 edge-wise transformation을 이루기 위해서 각 노드 ni에 output matrix와 input matrix를 할당함 → node ni가 state information을 node nj로 보낼 때 state information은 output matrix에 의해 먼저 transformation 되고 그 다음에 nj가 받기 전에 노드 nj의 input matrix에 의해 transform됨
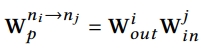
-
즉 식이 아래와 같이 변경될 수 있음
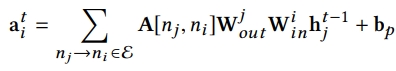
- 이렇게 식을 변경함으로써 space & time complexity를 줄이고 edge-wise interaction을 진행함
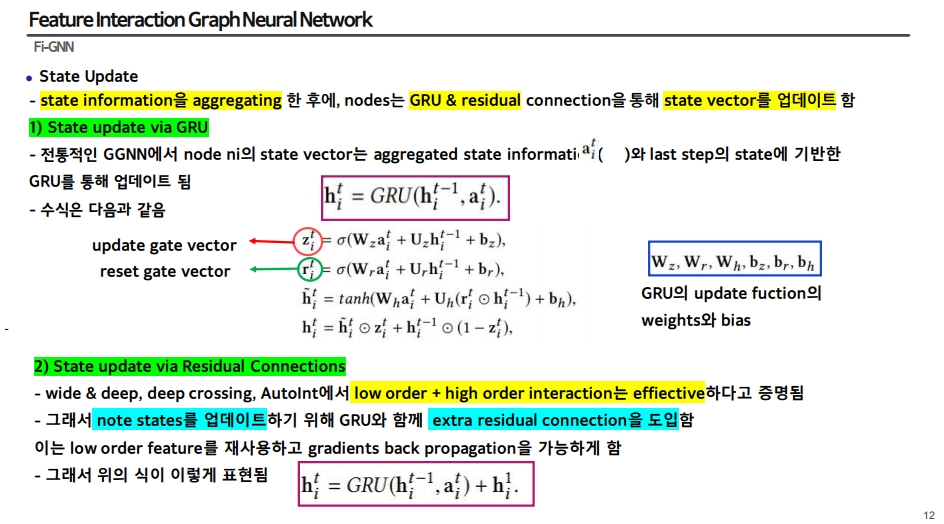
5) State Update(GRU & Residual)
- state information을 aggregating 한 후에 GRU와 residual connection을 통해 state vector를 업데이트 함
(1) GRU
- GRU를 활용한 GNN을 GGNN이라고 부르며, 이에 대한 식은 아래와 같음
-
이전 step의 hidden state 값과 aggregated state information을 input으로 하여 t번째의 hidden state 값을 내뱉음
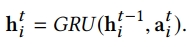
(2) Residual
- 이전 CTR 모델들에서 low order과 high order의 combine은 effective하였기 때문에 residual connection을 도입하여 low order feature를 재사용함
-
이를 통해 state update에 대한 최종 식은 다음과 같아짐
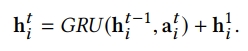
6) Attentional scoring Layer
-
t번의 propagation step을 거친 후 아래와 같은 node states를 얻을 수 있음
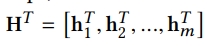
-
nodes는 t order neighbors를 가지고 interact했기 때문에 t order feature interaction을 모델링함
[Attention node weights]
- MLP를 2가지 활용함
1) MLP1
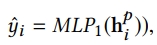
- output: each node의 final state의 prediction score
- each field node의 final state에 대한 score predict
- global information의 각각의 field aware의 prediction scoring 모델링
2) MLP2
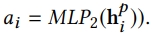
- output: attentional node weight
- each field의 weights를 모델링하는데 사용됨
- attention mechanism으로 MLP1의 예측 스코어를 sum up함
- attention mechansim
3) MLP1과 MLP2
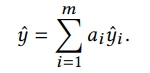
- all nodes의 summation
- output: overall prediction
Fi-GNN 코드 분석
코드-1) EmbeddingLayer

import torch
from torch import nn
import h5py
import os
import numpy as np
from collections import OrderedDict
class EmbeddingLayer(nn.Module):
def __init__(self,
feature_map,
embedding_dim,
use_pretrain=True,
required_feature_columns=[],
not_required_feature_columns=[]):
super(EmbeddingLayer, self).__init__()
self.embedding_layer = EmbeddingDictLayer(feature_map,
embedding_dim,
use_pretrain=use_pretrain,
required_feature_columns=required_feature_columns,
not_required_feature_columns=not_required_feature_columns)
def forward(self, X):
feature_emb_dict = self.embedding_layer(X)
feature_emb = self.embedding_layer.dict2tensor(feature_emb_dict)
return feature_emb
class EmbeddingDictLayer(nn.Module):
def __init__(self,
feature_map,
embedding_dim,
use_pretrain=True,
required_feature_columns=[],
not_required_feature_columns=[]):
super(EmbeddingDictLayer, self).__init__()
self._feature_map = feature_map
self.required_feature_columns = required_feature_columns
self.not_required_feature_columns = not_required_feature_columns
self.embedding_layer = nn.ModuleDict()
self.sequence_encoder = nn.ModuleDict()
self.embedding_hooks = nn.ModuleDict()
for feature, feature_spec in self._feature_map.feature_specs.items():
if self.is_required(feature):
if (not use_pretrain) and embedding_dim == 1:
feat_emb_dim = 1 # in case for LR
else:
feat_emb_dim = feature_spec.get("embedding_dim", embedding_dim)
if "pretrained_emb" in feature_spec:
self.embedding_hooks[feature] = nn.Linear(feat_emb_dim, embedding_dim, bias=False)
# Set embedding_layer according to share_embedding
if use_pretrain and "share_embedding" in feature_spec:
self.embedding_layer[feature] = self.embedding_layer[feature_spec["share_embedding"]]
self.set_sequence_encoder(feature, feature_spec.get("encoder", None))
continue
if feature_spec["type"] == "numeric":
self.embedding_layer[feature] = nn.Linear(1, feat_emb_dim, bias=False)
elif feature_spec["type"] == "categorical":
padding_idx = feature_spec.get("padding_idx", None)
embedding_matrix = nn.Embedding(feature_spec["vocab_size"],
feat_emb_dim,
padding_idx=padding_idx)
if use_pretrain and "pretrained_emb" in feature_spec:
embeddings = self.get_pretrained_embedding(feature_map.data_dir, feature, feature_spec)
embedding_matrix = self.set_pretrained_embedding(embedding_matrix,
embeddings,
freeze=feature_spec["freeze_emb"],
padding_idx=padding_idx)
self.embedding_layer[feature] = embedding_matrix
elif feature_spec["type"] == "sequence":
padding_idx = feature_spec["vocab_size"] - 1
embedding_matrix = nn.Embedding(feature_spec["vocab_size"],
feat_emb_dim,
padding_idx=padding_idx)
if use_pretrain and "pretrained_emb" in feature_spec:
embeddings = self.get_pretrained_embedding(feature_map.data_dir, feature, feature_spec)
embedding_matrix = self.set_pretrained_embedding(embedding_matrix,
embeddings,
freeze=feature_spec["freeze_emb"],
padding_idx=padding_idx)
self.embedding_layer[feature] = embedding_matrix
self.set_sequence_encoder(feature, feature_spec.get("encoder", None))
def is_required(self, feature):
""" Check whether feature is required for embedding """
feature_spec = self._feature_map.feature_specs[feature]
if len(self.required_feature_columns) > 0 and (feature not in self.required_feature_columns):
return False
elif feature in self.not_required_feature_columns:
return False
else:
return True
def set_sequence_encoder(self, feature, encoder):
if encoder is None or encoder in ["none", "null"]:
self.sequence_encoder.update({feature: None})
elif encoder == "MaskedAveragePooling":
self.sequence_encoder.update({feature: sequence.MaskedAveragePooling()})
elif encoder == "MaskedSumPooling":
self.sequence_encoder.update({feature: sequence.MaskedSumPooling()})
else:
raise RuntimeError("Sequence encoder={} is not supported.".format(encoder))
def get_pretrained_embedding(self, data_dir, feature_name, feature_spec):
pretrained_path = os.path.join(data_dir, feature_spec["pretrained_emb"])
with h5py.File(pretrained_path, 'r') as hf:
embeddings = hf[feature_name][:]
return embeddings
def set_pretrained_embedding(self, embedding_matrix, embeddings, freeze=False, padding_idx=None):
if padding_idx is not None:
embeddings[padding_idx] = np.zeros(embeddings.shape[-1])
embeddings = torch.from_numpy(embeddings).float()
embedding_matrix.weight = torch.nn.Parameter(embeddings)
if freeze:
embedding_matrix.weight.requires_grad = False
return embedding_matrix
def dict2tensor(self, embedding_dict, feature_source=None, feature_type=None):
if feature_source is not None:
if not isinstance(feature_source, list):
feature_source = [feature_source]
feature_emb_list = []
for feature, feature_spec in self._feature_map.feature_specs.items():
if feature_spec["source"] in feature_source:
feature_emb_list.append(embedding_dict[feature])
return torch.stack(feature_emb_list, dim=1)
elif feature_type is not None:
if not isinstance(feature_type, list):
feature_type = [feature_type]
feature_emb_list = []
for feature, feature_spec in self._feature_map.feature_specs.items():
if feature_spec["type"] in feature_type:
feature_emb_list.append(embedding_dict[feature])
return torch.stack(feature_emb_list, dim=1)
else:
return torch.stack(list(embedding_dict.values()), dim=1)
def forward(self, X):
feature_emb_dict = OrderedDict()
for feature, feature_spec in self._feature_map.feature_specs.items():
if feature in self.embedding_layer:
if feature_spec["type"] == "numeric":
inp = X[:, feature_spec["index"]].float().view(-1, 1)
embedding_vec = self.embedding_layer[feature](inp)
elif feature_spec["type"] == "categorical":
inp = X[:, feature_spec["index"]].long()
embedding_vec = self.embedding_layer[feature](inp)
elif feature_spec["type"] == "sequence":
inp = X[:, feature_spec["index"]].long()
seq_embed_matrix = self.embedding_layer[feature](inp)
if self.sequence_encoder[feature] is not None:
embedding_vec = self.sequence_encoder[feature](seq_embed_matrix)
else:
embedding_vec = seq_embed_matrix
if feature in self.embedding_hooks:
embedding_vec = self.embedding_hooks[feature](embedding_vec)
feature_emb_dict[feature] = embedding_vec
return feature_emb_dict
코드-2) Multi head Self Attention Layer
코드-3) Graph
- a를 만드는데 있어서 adjacency matrix와 transformation fuction이 필요한데 여기서는 transformation fuction을 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import product
# 개요: GNN에는 adjacency matrix와 transformation fuction이 필요함
# step01 : adjacency matrix
# - adjacency matrix: 노드 간의 edge의 weight를 의미하고, interaction의 importance를 반영함
# - 이 edge의 weight를 계산할 때 attention mechanism를 사용하여 관계 중요성을 반영함
# step02: transformation fuction
# - 모든 edge에 단순히 unique한 transformation weight를 모두 다 할당하는 것은 parameter와 time 소요가 크기 때문에 이를 줄이고 edge-wise transformation을 이루기 위해 각 노드 ni에 w(out)(output matrix)와 w(in)(input matrix)를 할당함
# - node ni → node nj로 state information을 보낼 때,
# step02-1: w(out)으로 먼저 h를 transformation되고
# step02-2: adjancency matrix와 setep02-1 multiplication
# step02-3: nj의 w(in)으로 transform함
# g: Multi-head Self-attention Layer을 거친 후의 adjacency matrix(edge weight)
# a: state aggregate
# h: feature embedding/last step state
# - h에 대해 GRU와 residual 과정을 거침
class GraphLayer(nn.Module):
def __init__(self, num_fields, embedding_dim):
super(GraphLayer, self).__init__()
self.W_in = torch.nn.Parameter(torch.Tensor(num_fields, embedding_dim, embedding_dim))
self.W_out = torch.nn.Parameter(torch.Tensor(num_fields, embedding_dim, embedding_dim))
nn.init.xavier_normal_(self.W_in)
nn.init.xavier_normal_(self.W_out)
self.bias_p = nn.Parameter(torch.zeros(embedding_dim))
def forward(self, g, h):
# step02-1: w(out)으로 먼저 h를 transformation
h_out = torch.matmul(self.W_out, h.unsqueeze(-1)).squeeze(-1) # broadcast multiply
# step02-2: adjancency matrix와 h_out multiplication
aggr = torch.bmm(g, h_out) # batch matrix multiplication
# step02-3:w(in)으로 transformation
a = torch.matmul(self.W_in, aggr.unsqueeze(-1)).squeeze(-1) + self.bias_p
return a
코드-4) attentional edge weights & gnn & gru & residual

import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import product
class FiGNN_Layer(nn.Module):
def __init__(self,
num_fields,
embedding_dim,
gnn_layers=3,
reuse_graph_layer=False,
use_gru=True,
use_residual=True,
device=None):
super(FiGNN_Layer, self).__init__()
self.num_fields = num_fields
self.embedding_dim = embedding_dim
self.gnn_layers = gnn_layers
self.use_residual = use_residual
self.reuse_graph_layer = reuse_graph_layer
self.device = device
if reuse_graph_layer:
self.gnn = GraphLayer(num_fields, embedding_dim)
else:
self.gnn = nn.ModuleList([GraphLayer(num_fields, embedding_dim)
for _ in range(gnn_layers)])
# GRU
self.gru = nn.GRUCell(embedding_dim, embedding_dim) if use_gru else None
# node i, j
self.src_nodes, self.dst_nodes = zip(*list(product(range(num_fields), repeat=2)))
self.leaky_relu = nn.LeakyReLU(negative_slope=0.01)
# weight matrix
self.W_attn = nn.Linear(embedding_dim * 2, 1, bias=False)
# attentional edge weights
# - 노드 간의 interaction의 중요성을 추론하기 위해 attention mechanism 제안
def build_graph_with_attention(self, feature_emb):
src_emb = feature_emb[:, self.src_nodes, :] # node
dst_emb = feature_emb[:, self.dst_nodes, :] # node
concat_emb = torch.cat([src_emb, dst_emb], dim=-1) # concat
alpha = self.leaky_relu(self.W_attn(concat_emb)) # weight matrix
alpha = alpha.view(-1, self.num_fields, self.num_fields)
mask = torch.eye(self.num_fields).to(self.device)
alpha = alpha.masked_fill(mask.byte(), float('-inf'))
graph = F.softmax(alpha, dim=-1) # node 간의 weight를 쉽게 비교할 수 있도록 사용
# batch x field x field without self-loops
return graph
# step01: attentional edge weights(Multi-head Self-attention Layer)
# step02: feature embedding(last step의 state)
# step03: GGNN: GNN & GRU (노드들을 반복하여 states 상호작용하여 업데이트)
# 1) gnn에 input(g와 h)를 넣어서 a를 만들고
# 2) gru에 inpu(h와 a)를 넣어서 nodes states(h)를 업데이트하고
# 3) residual connection을 도입하여 nodes state(h)를 업데이트
# -> 최종 output h
# g: Multi-head Self-attention Layer을 거친 후의 adjacency matrix(edge weight)
# a: state aggregate
# h: feature embedding/last step state
# - h에 대해 GRU와 residual 과정을 거침
def forward(self, feature_emb):
# step01: attentional edge weights(Multi-head Self-attention Layer)
# 초기 node state
g = self.build_graph_with_attention(feature_emb)
# step02: feature embedding(last step의 state)
h = feature_emb # feature representation
# step03: GGNN: GNN & GRU
for i in range(self.gnn_layers):
# step03-1) gnn에 input(g와 h)를 넣어서 a를 만들고
if self.reuse_graph_layer:
a = self.gnn(g, h)
else:
a = self.gnn[i](g, h)
# step03-2) gru에 inpu(h와 a)를 넣어서 nodes states(h)를 업데이트하고
if self.gru is not None:
a = a.view(-1, self.embedding_dim)
h = h.view(-1, self.embedding_dim)
h = self.gru(a, h)
h = h.view(-1, self.num_fields, self.embedding_dim)
else:
h = a + h
# step03-3) residual connection을 도입하여 nodes state(h)를 업데이트
if self.use_residual:
h += feature_emb
return h
GNN_layer 부분을 순서대로 요약해서 보자면
- Multi-head Self-attention Layer을 거치고 adjacency matrix를 생성: g
- gnn에 g와 h(feature embedding)을 넣어 a를 생성하고
- gru에 a와 h를 넣어서 h를 업데이트하고, residual connection으로 h 업데이트 업데이트 된 h를 가지고 gnn_layer 갯수만큼 반복하여 업데이트함 → 그래서 최종 결과는 h로 나옴
코드-5) Attentional Scoring Layer

-
t번의 propagation step을 거친 후 아래와 같은 node states를 얻을 수 있음
- nodes는 t order neighbors를 가지고 interact했기 때문에 t order feature interaction을 모델링함
- 이제 CTR 예측을 위해서 graph level의 output이 필요함
[Attention node weights]
- MLP를 2가지 활용하고 attention mechanism으로 이들을 sum함
-
MLP1은 각각 node의 final state(global)의 prediction score이고, MLP2는 각각의 field에 대한 weights를 모델링하는데 사용됨 → MLP1의 결과와 MLP2의 결과를 곱하여 sum해줌으로써 attention node weights를 생성함 → 그래서 최종적으로 all node의 summation을 하면 overall prediction이 생성됨
# step01: MLP1
# output: each node ni의 prediction score
# - each field node의 final state에 대한 score predict
# - global information의 각각의 field aware의 prediction scoring 모델링
# step02: MLP2
# output: attentional node weight
# - each field의 weights를 모델링하는데 사용됨
# - attention mechansim
# step03: all nodes의 summation
# output: overall prediction
class AttentionalPrediction(nn.Module):
def __init__(self, num_fields, embedding_dim):
super(AttentionalPrediction, self).__init__()
self.mlp1 = nn.Linear(embedding_dim, 1, bias=False)
self.mlp2 = nn.Sequential(nn.Linear(num_fields * embedding_dim, num_fields, bias=False),
nn.Sigmoid())
def forward(self, h):
# step01: MLP1
score = self.mlp1(h).squeeze(-1) # b x f
# step02: MLP2
weight = self.mlp2(h.flatten(start_dim=1)) # b x f
# step03: all nodes의 summation
logit = (weight * score).sum(dim=1).unsqueeze(-1)
return
코드-5) 모델: Class FiGNN
# step01: Input 넣은 후 X와 y로 분리
# step02: Embedding Layer
# step03: FiGNN_Layer
# step04: AttentionalPrediction
# step05: (존재시 진행) y_pred → output_activation (y_pred에 취해줌)
class FiGNN(BaseModel):
def __init__(self,
feature_map,
model_id="FiGNN",
gpu=-1,
task="binary_classification",
learning_rate=1e-3,
embedding_dim=10,
gnn_layers=3,
use_residual=True,
use_gru=True,
reuse_graph_layer=False,
embedding_regularizer=None,
net_regularizer=None,
**kwargs):
super(FiGNN, self).__init__(feature_map,
model_id=model_id,
gpu=gpu,
embedding_regularizer=embedding_regularizer,
net_regularizer=net_regularizer,
**kwargs)
self.embedding_dim = embedding_dim
self.num_fields = feature_map.num_fields
self.embedding_layer = EmbeddingLayer(feature_map, embedding_dim)
self.fignn = FiGNN_Layer(self.num_fields,
self.embedding_dim,
gnn_layers=gnn_layers,
reuse_graph_layer=reuse_graph_layer,
use_gru=use_gru,
use_residual=use_residual,
device=self.device)
self.fc = AttentionalPrediction(self.num_fields, embedding_dim)
self.output_activation = self.get_output_activation(task)
self.compile(kwargs["optimizer"], loss=kwargs["loss"], lr=learning_rate)
self.reset_parameters()
self.model_to_device()
def forward(self, inputs):
# step01: Input 넣은 후 X와 y로 분리
X, y = self.inputs_to_device(inputs)
# step02: Embedding Layer
feature_emb = self.embedding_layer(X)
# step03: FiGNN_Layer
h_out = self.fignn(feature_emb)
# step04: AttentionalPrediction
y_pred = self.fc(h_out)
# step05: (존재시 진행) y_pred → output_activation (y_pred에 취해줌)
if self.output_activation is not None:
y_pred = self.output_activation(y_pred)
return_dict = {"y_true": y, "y_pred": y_pred}
return return_dict
References
[논문]
- Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Prediction:https://arxiv.org/pdf/1910.05552.pdf
[코드]
- 패키지(파이토치) FUXI CTR : LR(07)~AOANet(2021)
Leave a comment