
[추천시스템] NAVER D2 추천시스템 강의
해당 글은 youtube에 공개된 naver d2(19.08) 발표된 **Recent Advances in Deep Recommender Systems**를 정리한 자료입니다.

추천시스템의 의미와 활용
사용자들이 원하는 아이템을 추천, 원하는 것을 추론
상품과 음악, 영화 추천 분야에서 활용
검색과 추천
추천과 검색 모두 기본 목적은 사용자가 원하는 것이 무엇인가를 찾아주는 것이 주된 목적
사용자가 원하는 소량의 정보
검색의 경우 사용자가 무엇을 할지를 보통 명시하게 됨, 키워드 질의 형식으로 그 명시 바탕으로 관련된 결과를 반환함, 사용자가 먼저 모델을 시작한다고 볼 수 있고 ex)네이버를 알고 싶다 → 관련 문서, 이미지

추천은 사용자에서 시작하는 것이 아니라 시스템의 관점에서 시작함, 과거의 어떤 정보를 검색, 클릭 정보를 제공할 뿐 현재 원하는 것을 알려주지 않음 과거 히스토리를 바탕으로 좋아하는 것을 제안 → 사용자의 선호도를 정확히 추론하지 못하면 사용자에게 이상한 정보를 제공할 수 있는게 어려운 문제
즉, 가장 큰 차이는 사용자 관점에서 유저 인텐트를 이해하고 제공하는지 추론하는지임
추천의 활용분야

음악과 영화의 차이, 3~5분 그리고 음악의 경우 훨씬 더 많은 아이템을 가지고 있음
spotify: 플레이리스트 자동재생으로 사용자 만족도를 높임

뉴스 추천으로 클릭수 30% 증가

- 페이스북의 친구 추천, 맛집추천(생각보다 어려운 추천 context 이해가 중요 개인, 가족, 연구 필요한 분야)), 게임의 앱 추천, 데이팅앱, 리뷰 중 태그 추천, job 추천, 부동산 추천 → 대부분의 앱에서 추천 시스템 활용 → 사용자 만족도 관점
- 한국의 추천시스템 회사: 레코멘
추천시스템 종류
Collaborative filtering
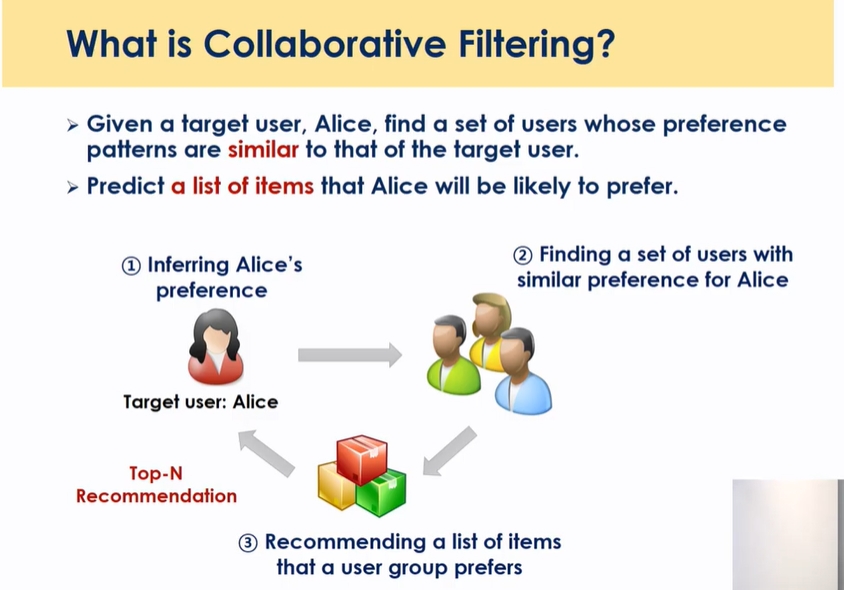
어떤 유저가 들어왔을때 그 유저와 가장 비슷한 유저를 찾아주고 그 정보를 바탕으로 타겟 유저가 경험하지않은 항목들을 제공해주는 것, 도플갱어를 찾아준다는 개념, K개의 nearest 이웃을 찾아줌

어떤 유저가 어떤 아이템을 좋아하는지, user가 클릭하지 않은 아이템들 중에서 어떤 상위 N개를 좋아할 것인가
Latent Factor Models
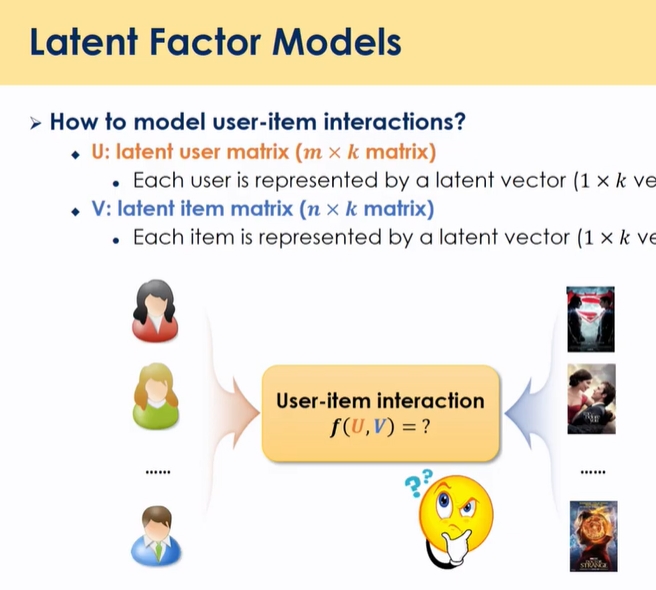
유저와 아이템을 K차원의 임베딩 스페이스에서 유저와 아이템을 풀어 표현하는 것
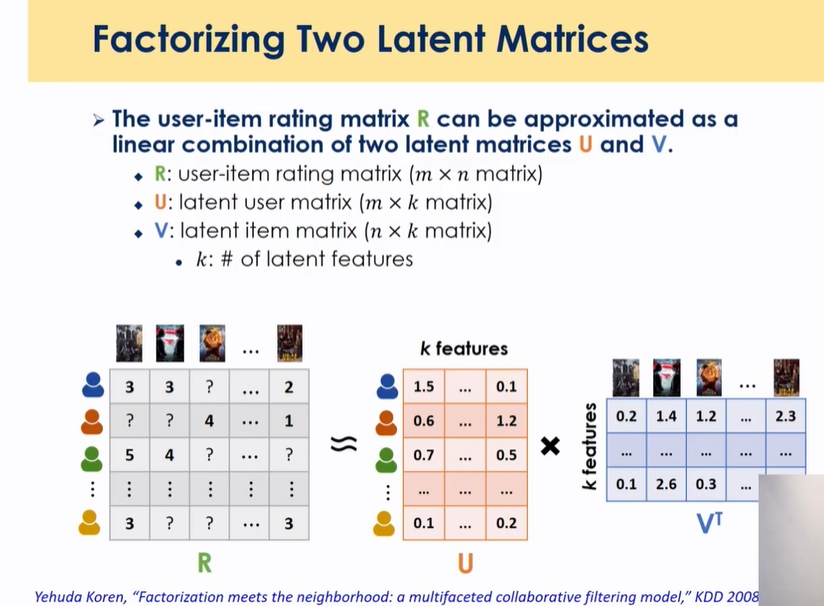
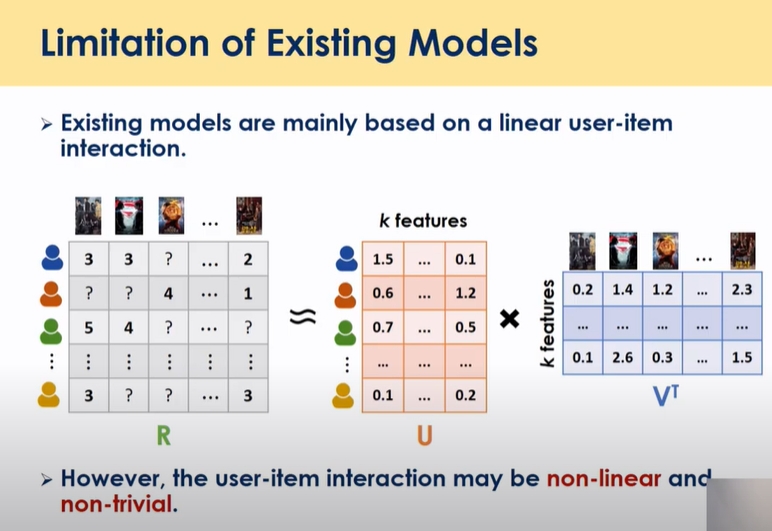
inear combination이 아닌 non linear 관계를 가질 때 inner product가 아닌 다른 형식으로 표현하도록 하는게 딥러닝 방향으로 개선하고자함
Q: user와 item이 많은 경우, 실제 서빙할 때 시간이 많이 걸릴 것 같은데
답변1: 곱해둔 상황에서 user에게 서빙
답변1 보완: 사실 저장하는 것 자체에 용량이슈, 속도이슈가 있음 ⇒ user latent factor, item latent factor 각각 저장하면 용량이슈가 줄어듦 → 사람이 들어왔을때 계산 + latent factor 해석할 수 있으면 활용도가 높아질 수 있음 →검토 필요
딥러닝을 활용한 모델

오토인코더
###
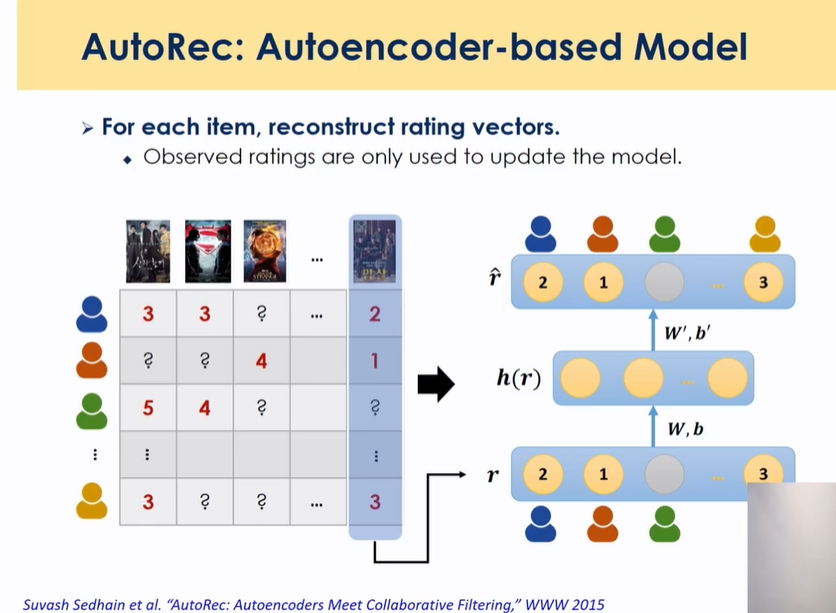
- vector를 그대로 복원해 내는 것
- 고차원→ 저차원 축소
- 축소된 차원이 PCA나 SVD와 같이 고차원 데이터를 저차원으로 축소하는 그런 형식
- h(r)라는 걸 표현할 때 액티베이션 function을 넣을 수 있는데 그걸 identity function으로 하고 레이어를 하나만 쌓으면 오토 인코더 모델은 pca와 같음, pca의 non linear 버전까지 확장
- user item matrix를 컬럼, 로우 기반으로 각각 인풋으로 벡터로 넣고 벡터를 복원해내는 형식으로 학습 위 예제에서는 컬럼 기반으로 진행, binary도 가능
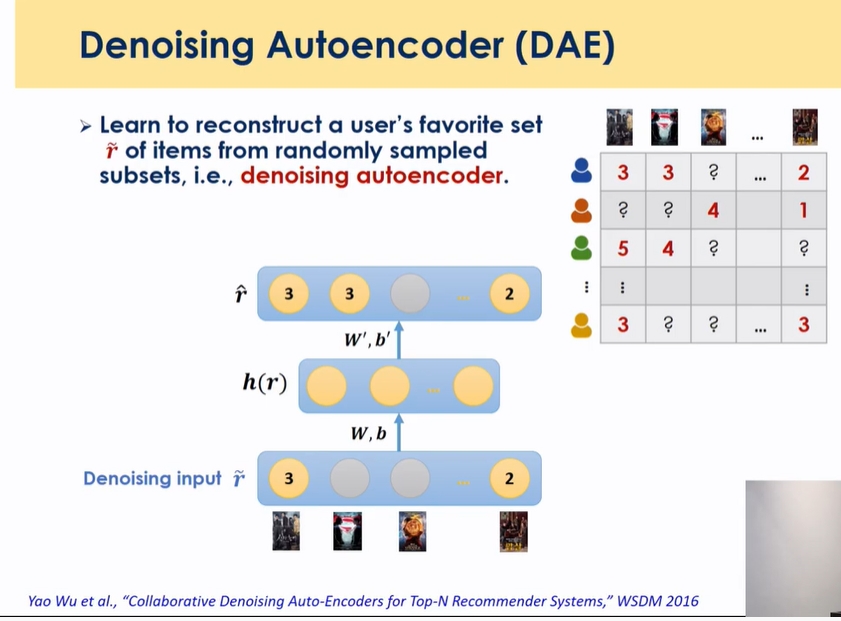
- 가장 큰 인풋 데이터를 일부 노이즈를 넣고 일부 넣은 노이즈를 복원할 수 있게끔 만든 것
- 앞에선 332이었는데 대신에 일부 값을 노이즈를 넣음 지워버리고 32를 넣고 332를 복원하라고 하는 것
- output은 같은데 input을 조금씩 변경하면서 넣고 latent space에서 거의 비슷한 형식으로 표현되게끔 강제하는 과정을 학습함 → 이 중간에 표현된 representation이 좀더 강건해짐 → 강건한 모델 → DAE가 AE보다 나은 성능
- 장점:
1) data generation 효과, 샘플수가 늘어나는 효과
2) 일반화:information 모두 쓰면 외워버려서 적은 information을 쓰면 일반화 효과가 있음 → 모델의 안정성이 강해짐
이미지쪽은 실제로 잡음을 추가하고, 이미지 transform함 → 얘는 개념상 있는 데이터 없애주는 것
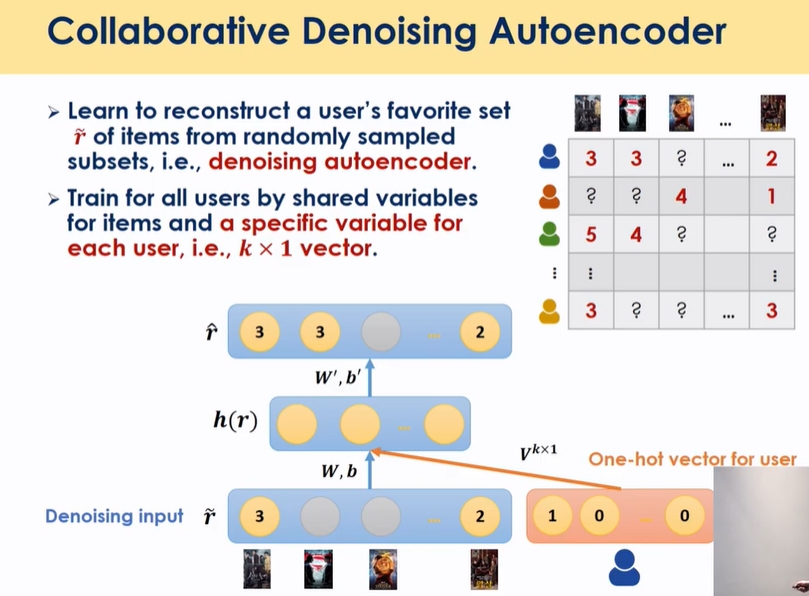
- user 자체의 특징을 one hot 벡터를 추가함
- 1) rating값을 넣고( nm) 2) user id one hot 인코딩(nn)으로 넣음: word2vec처럼 비슷한 유저들을 공간상에 모이게 뿌려줄 수 있음(단어의 의미를 수치화, 문장 수치화, predict )
- 실제로 돌려보면 데이터가 작으면 CDAE와 DAE와 유사함 → user 정보가 latent space에서 vector로 표현하는데 데이터가 많지 않고서는 그 정보를 정확히 캐치하기 어렵다고 함 →rating에 user가 다르다는건 이미 반영되어 있어서 추가적인 의미가 크지 않음
MLP 기반
GMF
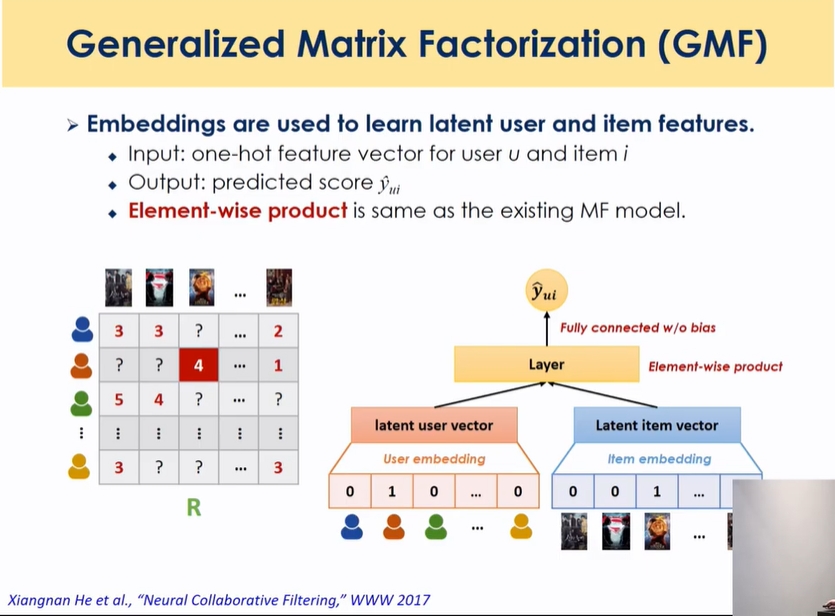
- 앞에서는 user의 rating 한줄을 예측했는데 GMF는 특정 user의 특정 item single value에 대해 예측함
- weight가 factor??
- 기존 MF를 뉴럴넷 모양으로 만들어서 extension한 모델
- user, item를 one hot vector로 표현해서 임베딩 매트릭스 통과한 후 element wise product 결과를 내고 더한 결과
-
fully connected 부분 제외하고 거의 동일함
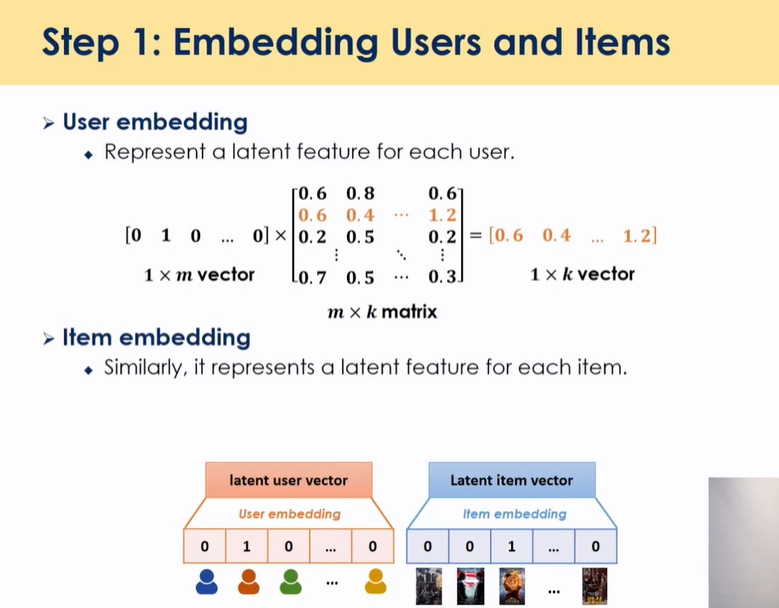
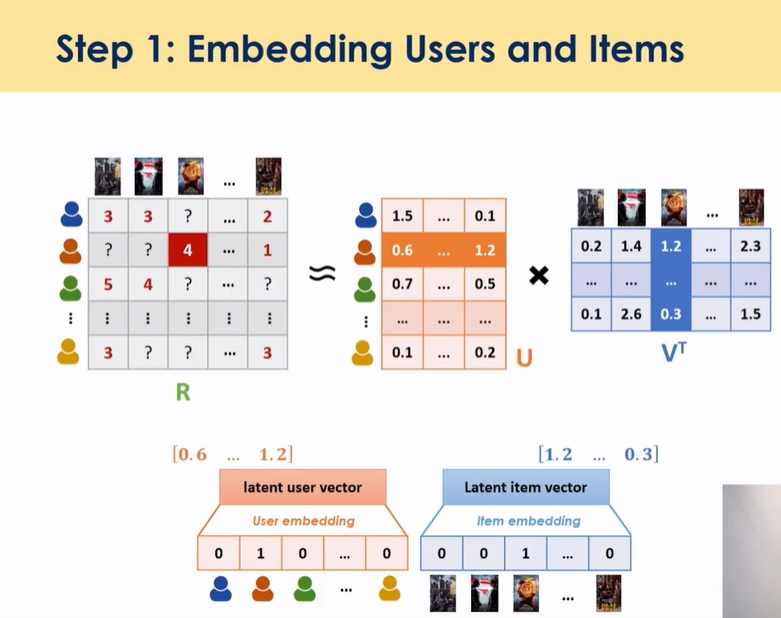
- 유저임베딩: 임베딩 매트릭스는 m*k차원으로 표현 → 임베딩을 통과하면 → 원핫벡터와 곱해서 한 행을 얻어낼 수 있음(user latent matrix의 한 행)
k차원에 대해 피처에 대해서 element wise product
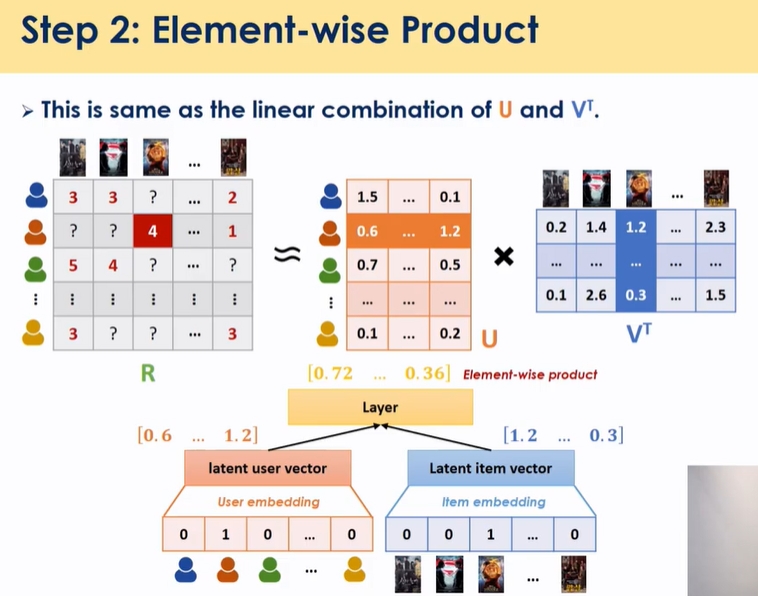
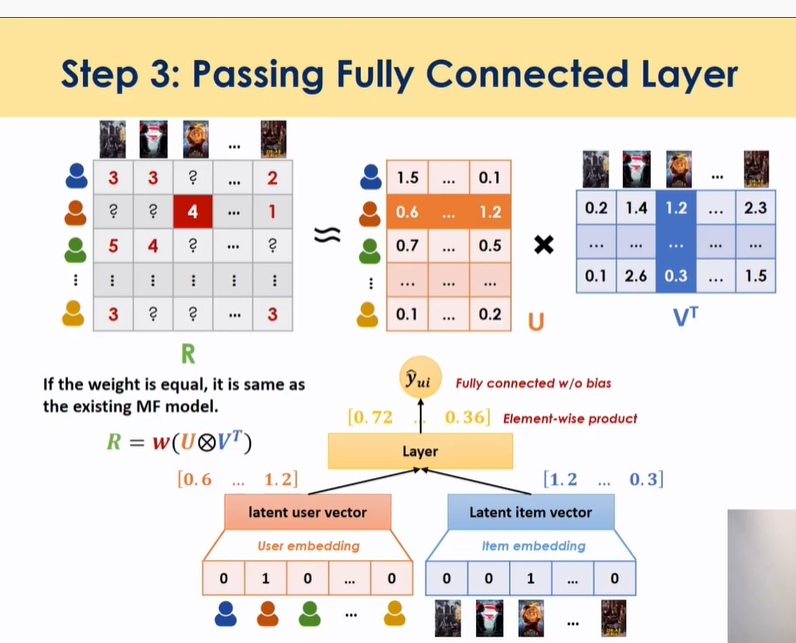
- 기존 MF는 product한걸 다 더했는데 y를 예측하는데 있어서 weight을 equal weight로 준건데 GMF는 weight를 학습하는 파라미터로 줌 → MF의 general 형태 → feature에 개별적으로 다르게 추가적으로 곱함
MLP based MF
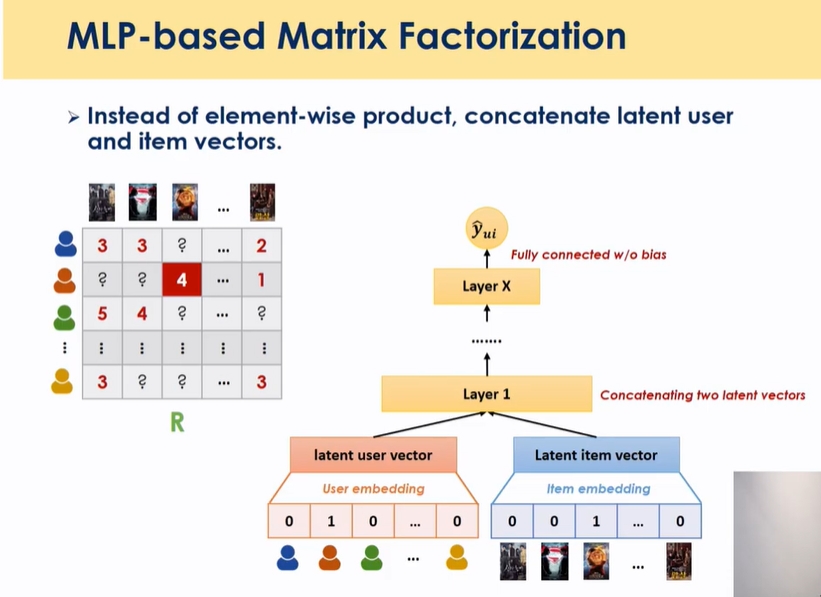
- 훨씬 더 단순하게 첫번째 임베딩을 통과한 후에 이 두개를 concatenate를 한 후 그 위에 MLP를 쌓아서 학습 → item과 user의 iteraction을 multi layer perceptron으로 확장했음 non linear등의 복잡한 관계를 학습할 수 있게 함 → GMF와 더블어 논문에서 제공된 모델 → 최종적으로 두개를 합친게 NCF
NCF
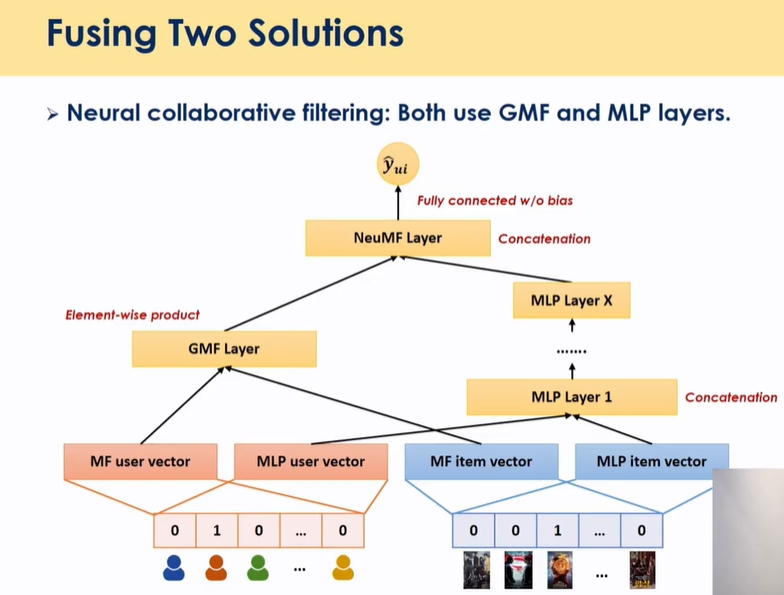
- GMF: linear relationship
- MLP: non linear relationship
- 둘을 통합
- 다른 모델 대비 성능이 대단히 좋진 않지만 널리 차용되고 있는 모델임
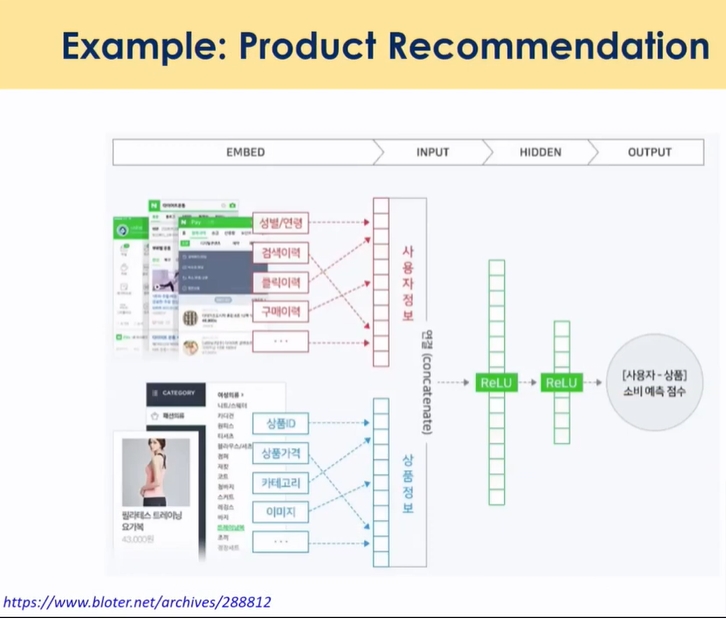
- 궁극적으로 위 그림처럼 이정도 information 사용하는게 미션
Prod2vec
word embedding
38분
Session based Recommendation : RNN

-
동영상 추천에서 많이 활용 → 유저가 로그인하지 않은 상태에서 a,b,c를 경험 한 경우 시간 순서에 따라 어떤 것을 추천해줄 것인가를 찾고자 하는 것 → 유저가 어떤 아이템들을 경험했고, 최근에 어떤 항목을 클릭했는지를 결합해서 유저가 좋아할만한 것을 찾아주는 것이 목적
-
RNN 기반
성능 개선 NARM
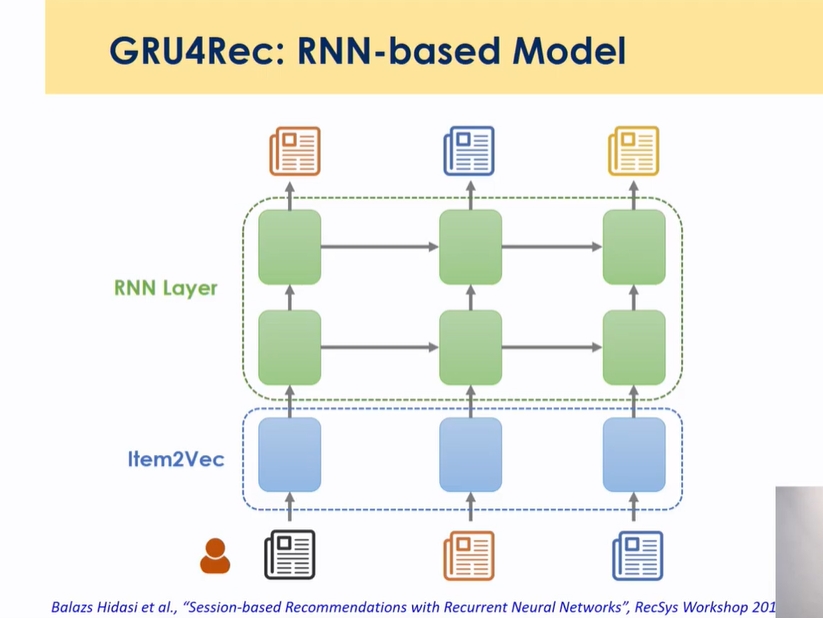
- 글로벌과 로컬 인포메이션 합치는 부분이 있음
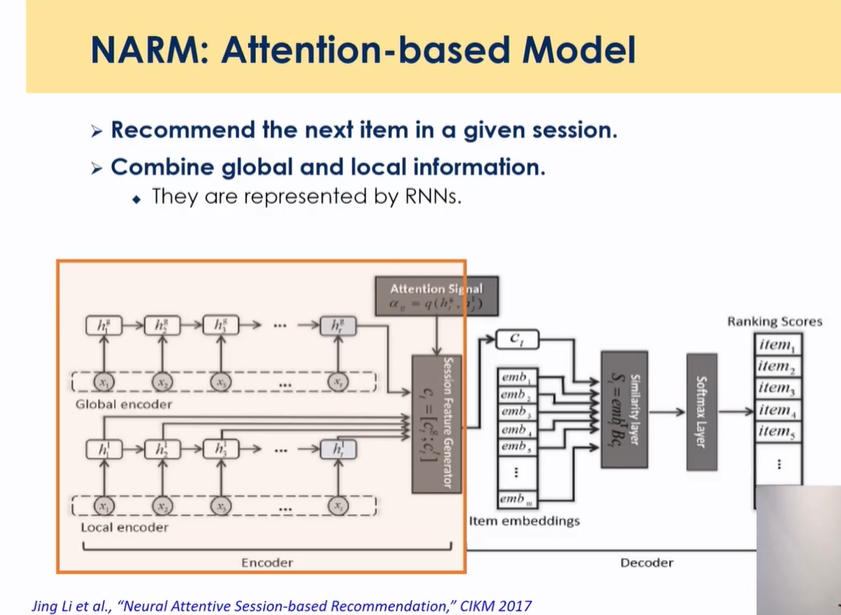
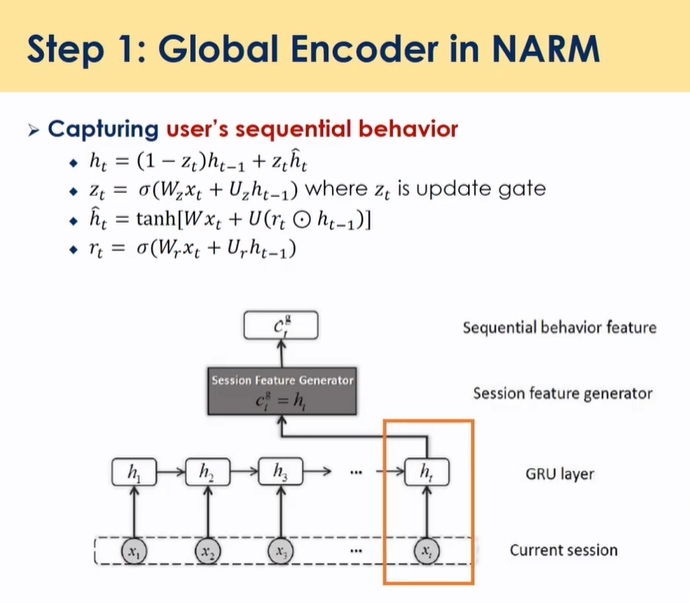
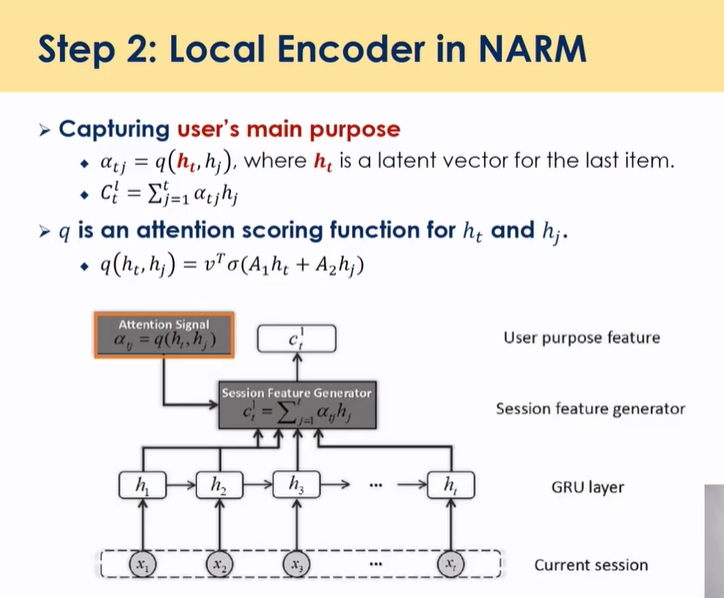
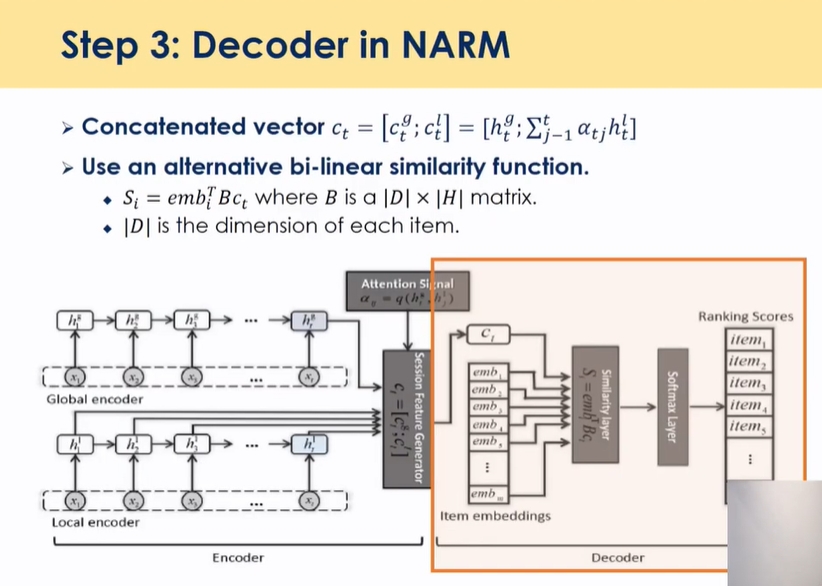
Combining Attention and Memory(STAMP)
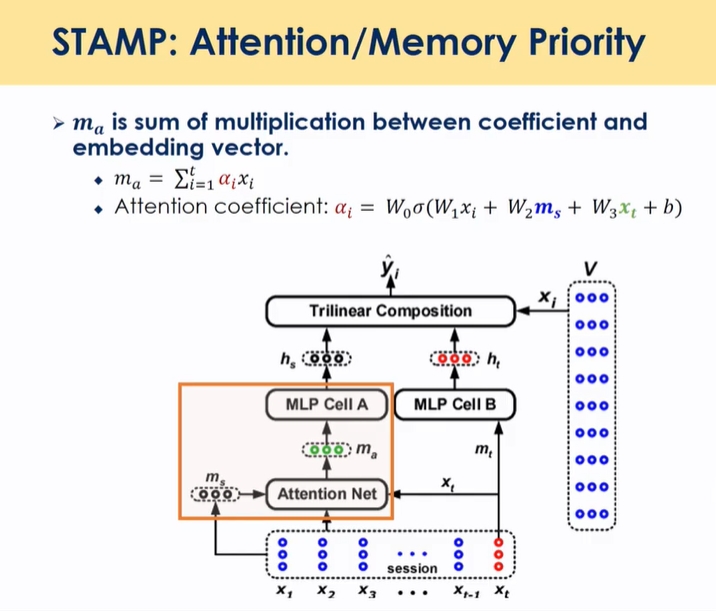
대회 : MMCF

- spotify

-
플레이리스트가 없는 extreme한 케이스, shuffle
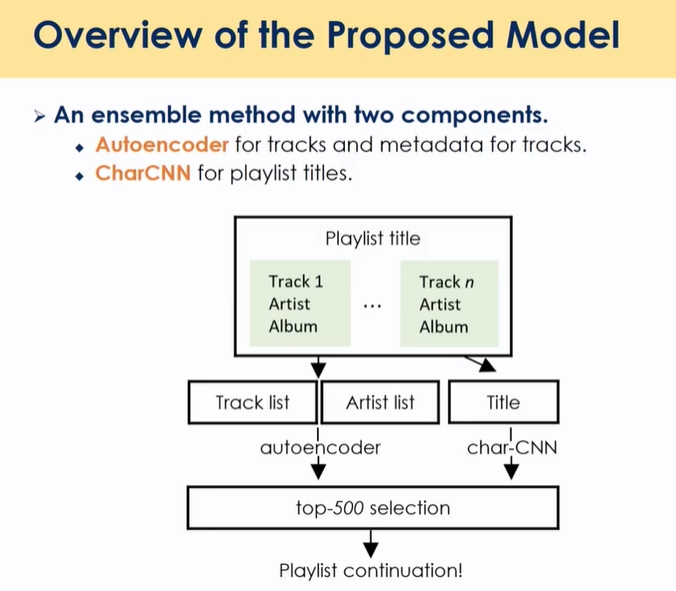
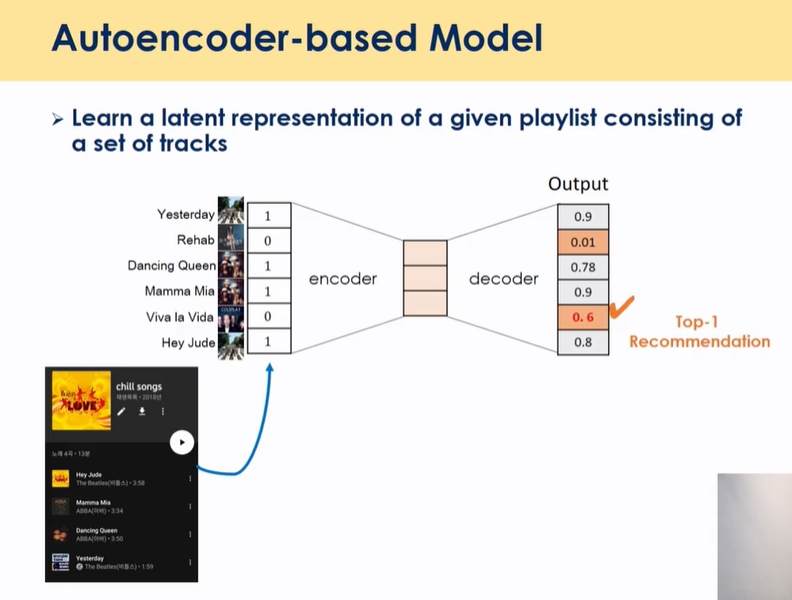
- auto encoder 유저가 이전에 본 음악들을 binary로 표현
- base라인으로 DAE 활용 → 데이터 풍부하게 만들어둠
- 정보가 sparse할 수 있음
-
metadata 활용 → 아티스트 데이터 활용
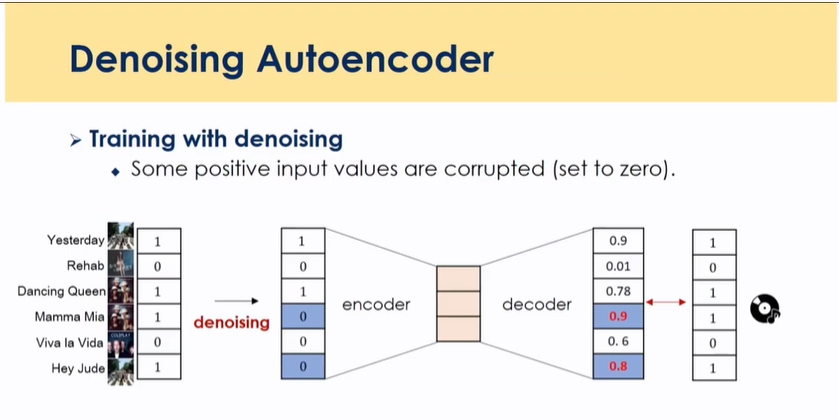
- 봤던 아이템의 아티스트 binary data → sparness는 해결되지 않음(ex) 아이템 모두 안본 경우, 아티스트도 0)
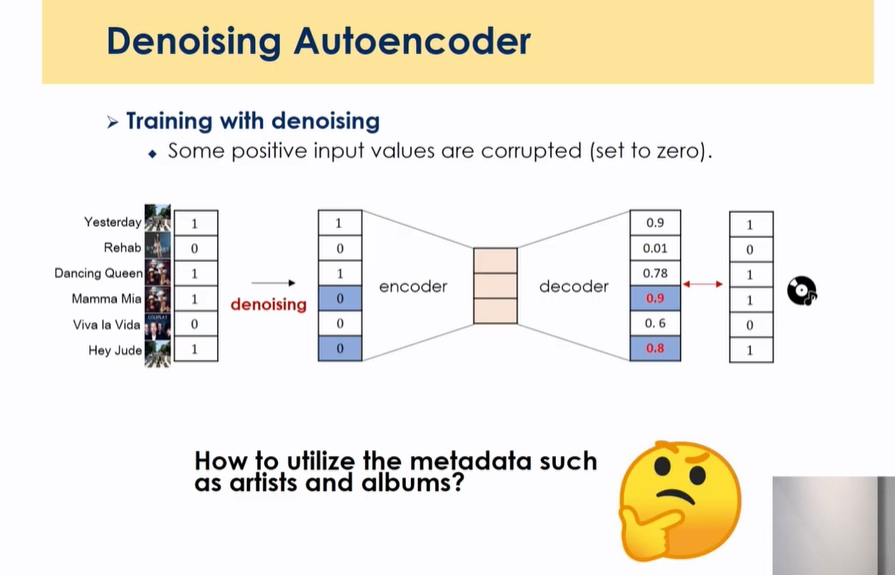
- 이 음악의 가수들을 binary로 표현
-
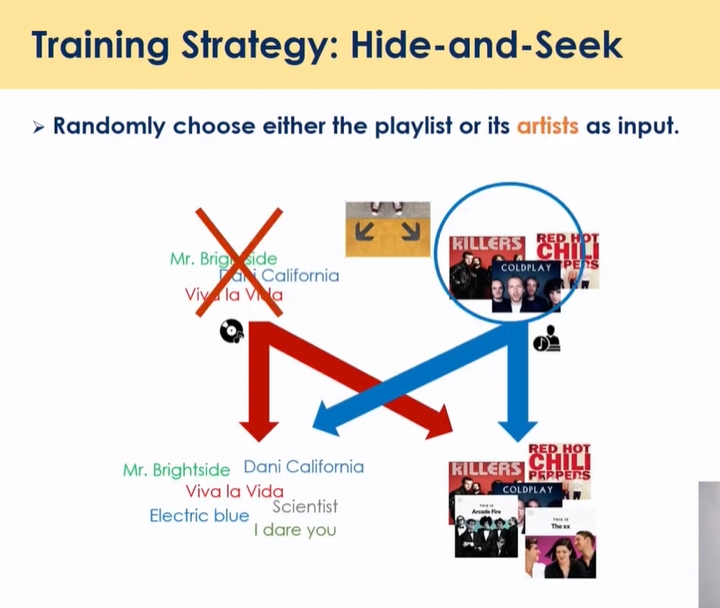
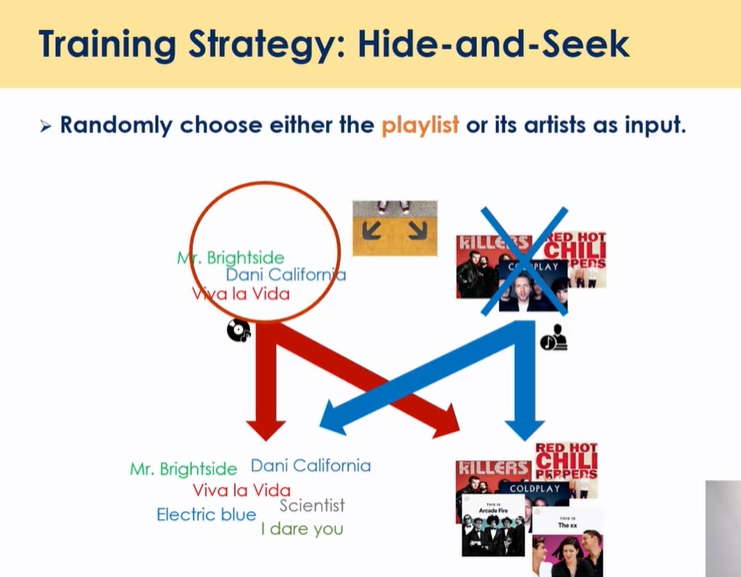
강건한 학습을 위해 숨바꼭질 하듯이 번갈아가면서
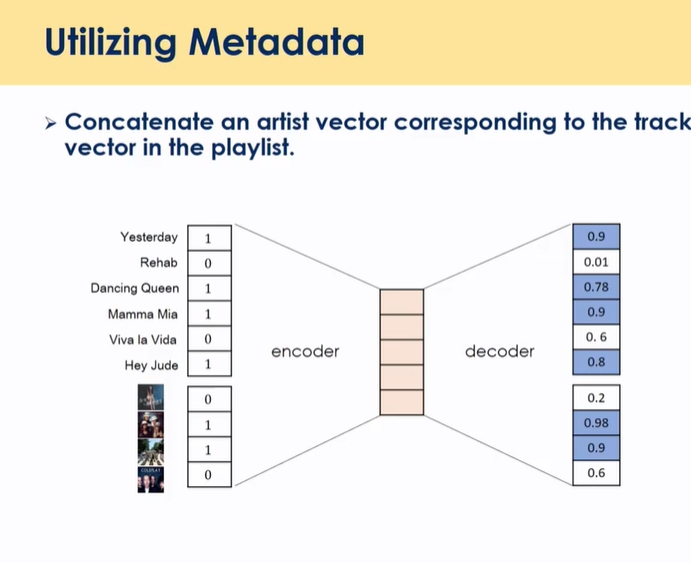
- 컨텐츠 뿐만 아니라 아티스트에 대한 예측도 가능함 (개별 컨텐츠를 클릭할 확률과 카테고리 클릭할 확률을 동시에 얻어낼 수 있음 → 신규 아이템의 경우, 카테고리 값을 활용해서 cold start 해결 가능)
CharCNN :
LSTM이 후에 성능은 더 좋았음
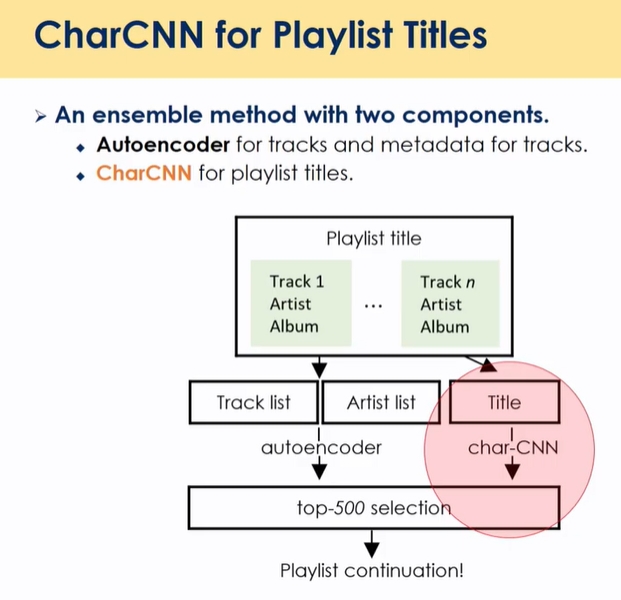
- 워드 레벨을 캐릭터 레벨로 표현 → 이유는 1) playlist가 짧기 때문(ex)가을에 들으면 좋은 노래 →가을노래) 2) 존재하지 않는 워드들 존재(ex)ㅋㅋㅋ)
-
음악과 아티스트 정보 맞히게끔 학습
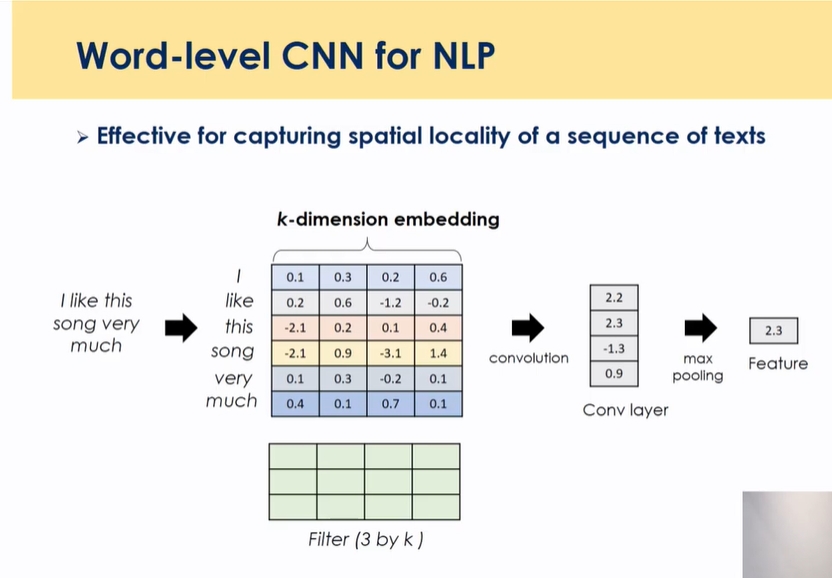

- CNN의 경우, 이미지 상에서 특정 feature를 끄집어내서 새로운 feature를 만들어냄
- ‘어떤 기조의 워드가 들어가 있어’가 중간 feature vector
- 제목이 나타내는 성향이 feature로 나타남 → 이 feature를 바탕으로 다른 info가 없을때 제목을 가지고 평균적으로 어떤 성향을 가져서 어떤 음악과 아티스트를 좋아하는지를 추론
## 최종 모델 : 결합
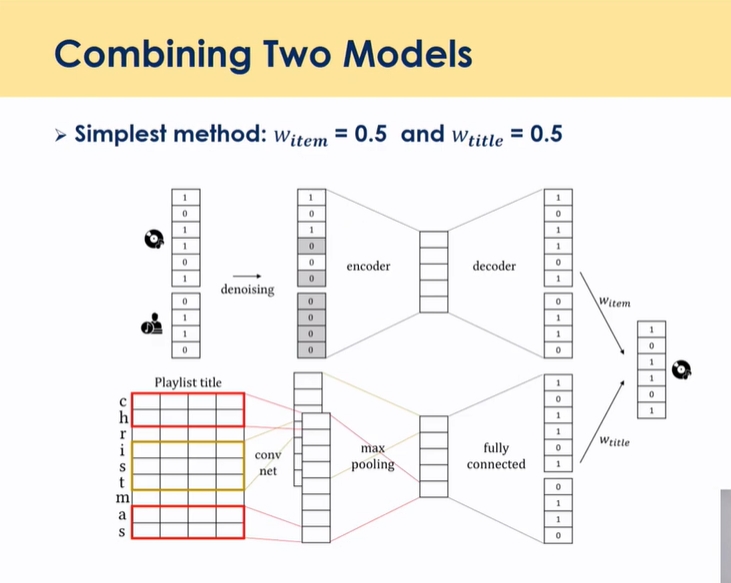
- weight을 반반으로 하지 않음
- 1) rating과 아티스트 2) 제목 ⇒ 합쳐둔 것(rating 정보가 없으면 2로
- 아이템이 콜드스타트여도 반응할 것 같은 확률 값을 얻어냄
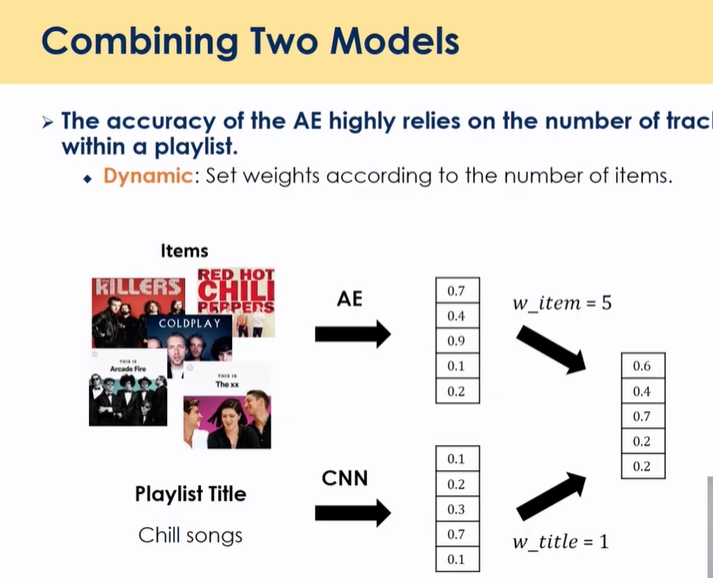
- 결합할 때 반반 결합하기엔 정보가 다를 수 있어서
- 갯수에 따라 weight을 다르게 줘서 모델을 학습하게 함
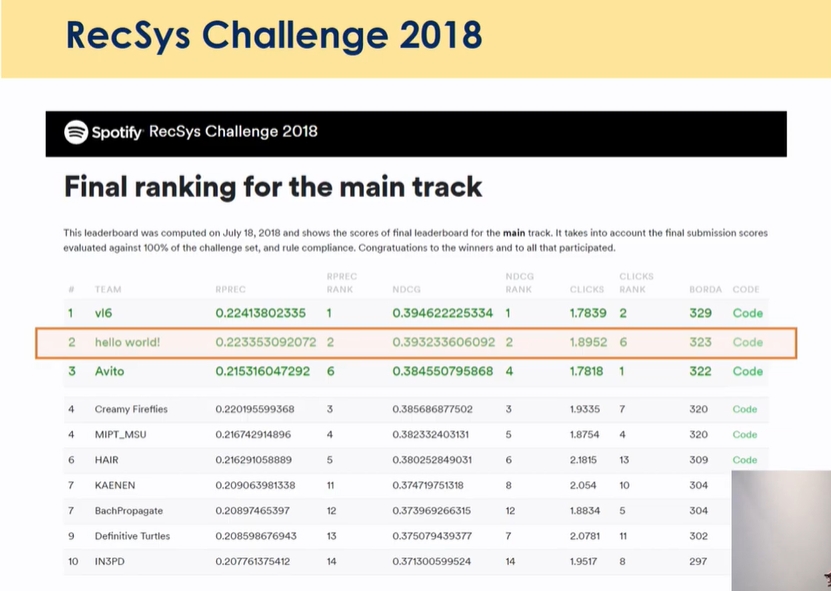
spotify recsys challenge 2018
https://github.com/hojinYang/spotify_recSys_challenge_2018
https://www.recsyschallenge.com/2018/
https://github.com/hojinYang/spotify_recSys_challenge_2018

Leave a comment