
[추천시스템] Session-based recommendation model 종류(GRU4Rec~SGNN)
GRU4Rec(2015) → NARM(2017) → STAMP(2018) & SRGNN(2018)→ NISER(2019) → SGNN(2020) → GCE-GNN(2021)
GRU4Rec
- session에서는 시간 순서를 고려하니까 RNN을 써야하는게 아닌가?라는 질문에서 출발하게 된 논문
-
해당 논문은 RNN 중 GRU를 사용한 모델임
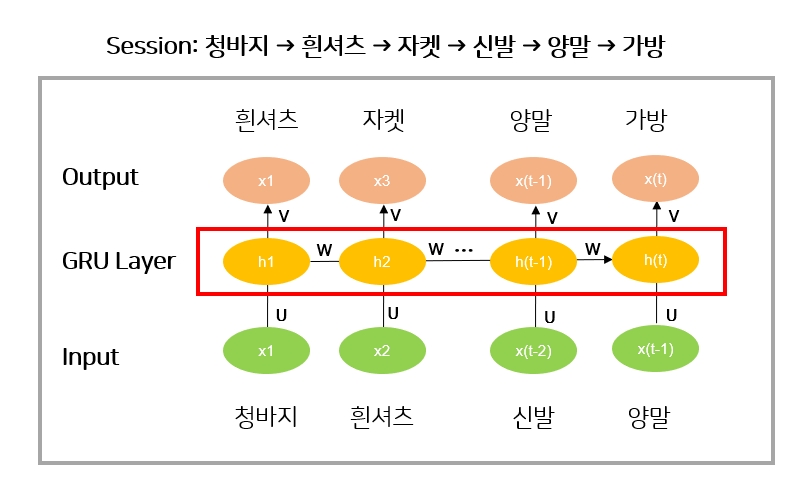
- A를 입력했을 때 B를 맞추고 A,B를 입력했을 때 C를 맞추고
A,B,C를 입력했을 때 D를 맞추고 A,B,C,D를 입력했을 때 E를 맞추는 형식으로 학습함
- 예) (청바지)을 입력으로 넣었을때 (흰셔츠)를 맞추고, (청바지,흰셔츠)을 입력으로 넣었을때 (자켓)를 맞추고 (청바지, 흰셔츠, 자켓)을 입력으로 넣었을때 (신발)를 맞추는 식
- 입력 sequence를 순차적으로 넣고 next 아이템을 맞추려고 함
- GRU4rec은 마지막 히든 스테이트가 의미하는 바가 가장 처음 x(1))부터 현재시점(x(t-1))까지의 입력을 잘 aggegation해서 표현한 벡터가 h(t)임
NARM
- Neural Attentive Recommendation Machine (NARM)
요약
- GRU4Rec을 개선하고자 함
- 기존의 GRU4Rec은 글로벌 인코더 역할을 함
- 글로벌 뿐만 아니라 로컬 인코더를 추가하여 다양한 property를 고려하고자 함
h(t)
- RNN에서 가장 마지막 hidden state가 의미하는게 가장 처음 x(1)부터 현재시점 x(t-1)까지의 입력을 잘 aggregation해서 표현한 벡터
- h(t)가 input 마지막 아이템인 양말의 정보를 많이 포함했다고 볼 수 있음
- 마지막 아이템인 가방을 맞추는데 있어서 h(t) 뿐만 아니라 h(t-1), h1 등 중간 hidden state도 같이 고려해서 예측하는게 성능 개선에 도움이 되지 않을까 라는 아이디어에서 시작
- 즉, 기존 GRU4Rec은 h(t)만 사용했는데 NARM은 중간 hidden state도 같이 사용함
NARM 모델 구조
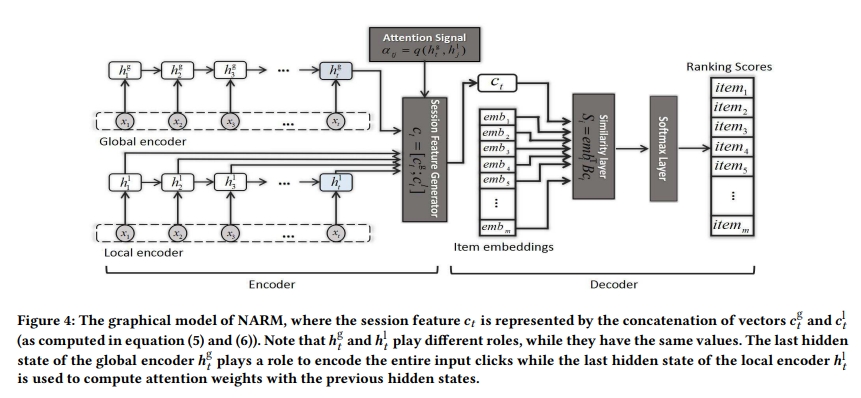
- 2개의 인코더를 가지고 local feature와 global feature를 잡아내려고 함
1) Global Encoder
- 해당 session에 전반적으로 흐르는 정보
2) Local encoder:
- 현재 아이템을 기준으로 다음 아이템을 맞출 때 가장 근거리 아이템을 반영
1) Global Encoder
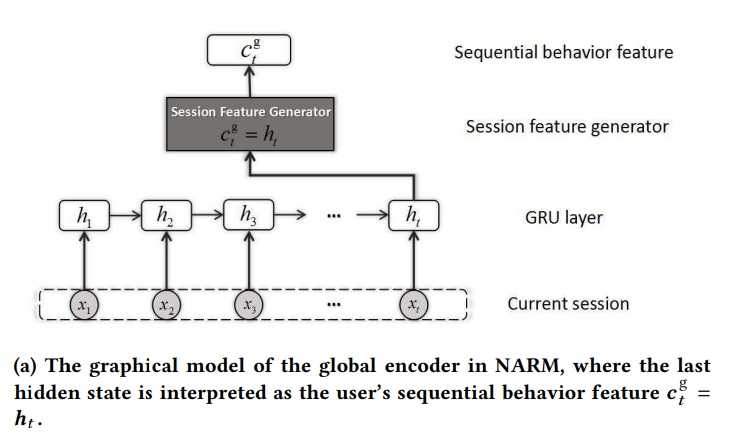
- 글로벌 인코더는 마지막 h(t): x1~xt를 고려해서 만든 것
- 입력으로 주어진 모든 정보를 h(t)가 압축
- 이 글로벌 인코더만 사용하면 GRU4Rec과 동일함
- $C^{g}_{t}$
2) Local Encoder
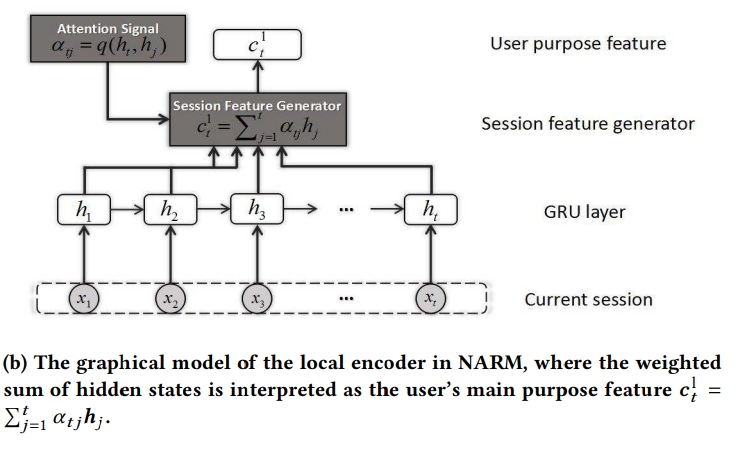
**
- attention mechanism을 이용하여 계산
- h(1)~h(t)까지 각각의 시점에서 얻은 hidden state vector를 aggregation해서 표현한 것
- $\alpha(tj)$: 타겟 h(t)를 기준으로 각각의 h(1), …, h(t)까지 attention score를 계산하는 것
- attention score를 기준으로 h(1)~h(t)까지를 aggregation 해서 새로운 h attention 벡터를 얻게 됨
- h(1), h(2), h(3) 3개가 있다고 할 때 $\alpha(tj)$가 계산되어서 0.1, 0.4, 0.5가 되고, 이를 aggregation하여 $C_{t}^{l}$ 이 을 생성함
- $C_{t}^{l}$ : Local Encoder의 결과물
1)+2) 전체
- NARM은 Local Encoder가 추가된 게 핵심임
-
Global과 Local Encoder로 나온 게 $C^{g}{t}$와 $C{t}^{l}$
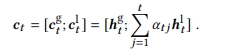
-
두 벡터를 concat하고, 2h차원으로 확장하고, B매트릭스를 곱해서 h차원으로 줄인 후 원하는 형태로 늘려줌
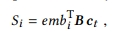
-
LSTM과 RNN에서 마지막 state가 현재까지의 정보를 잘 누적했다고 기대하지만 그러지 않게 되는 경우가 있음, 그럴 때 hidden state를 selection해서 내가 원하는 부분을 잘 prediction하게 하고자 하는 것인데 이때 중간 hidden state를 쓸 수 있게 해주는 것이 로컬 인코더의 역할임
STMP
- short term memory model
- RNN의 경우, 학습시간이 걸리는 편이라 RNN을 사용하지 않고 MLP를 사용함
1) general interest
- 세션에서 전체적으로 흐르는 정보
2) short term interest
- 가장 최근의 아이템(마지막 아이템)
→ STMP는 1)과 2)를 모두 고려하는 그 중 2)인 short term interest를 좀 더 고려하는 모델임
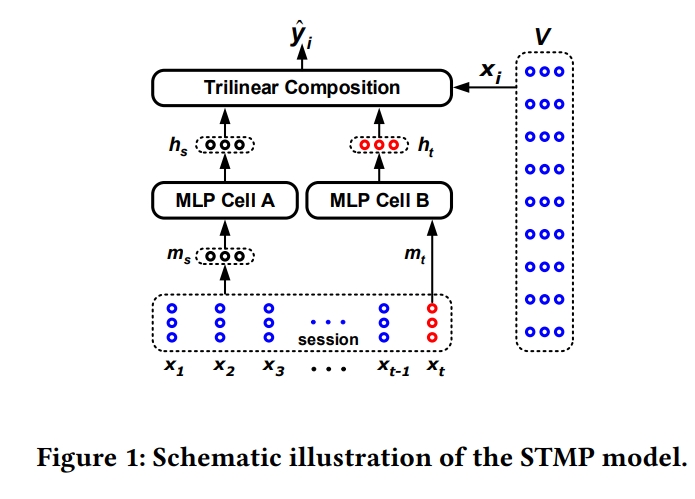
- x(1)~x(t)까지 입력했을 때 그 다음에 어떤 아이템이 나올지 x(t+1)을 예측하는게 목적임
1-1) general interest
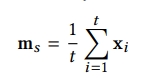
- m(s): x(1)~x(t)를 평균 낸 벡터
- x(1)~x(t)까지가 각 아이템의 임베딩인데 이를 모두 1/t의 가중치로 동일하게 표현함
1-2) short interest
- m(t): short term interest
- x(t): 가장 마지막 아이템, short term interest를 표현하는 벡터
- The symbol m(t) denotes the current interests of the user in that session, in this study, the last click x(t) is used to represent the user’s current interests : m(t) = x(t)
2-1) MLP Cell A
-
h(s): general interest를 토대로 만든 hidden vector
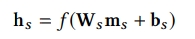
2-2) MLP Cell B
- h(t): short term interest를 토대로 만든 hidden vector
3) score function
- h(s)와 h(t)를 concat하고 x(i)각각의 아이템을 함수에 넣어서 각 아이템에 대한 스코어를 계산하고 softmax에 통과시킴
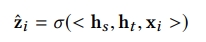
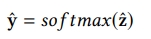
- 정리를 하자면 첫번째 인코더는 각 아이템 벡터 평균 내서 만든 것, 두번째 인코더는 마지막 아이템만 통과시킨 것
- 이 두개를 임의의 MLP에 하나씩 통과시킨 다음에 그 두 개의 벡터와 아이템 임베딩을 임의의 함수를 통과시키도록 하여 최종 스코어를 계산하는 방식이 STMP
STAMP
- short term attention/memory priority model
- STMP 모델에 attention을 넣은 부분이 다른 점
- STMP의 경우, general interest를 표현하는 m(s)는 각 아이템에 대한 평균을 사용하는데 이가 효과적이지 않을 수 있으니, 이 부분을 학습을 통해 결정하고자 하는 모델임
-
평균 대신 attention을 사용함
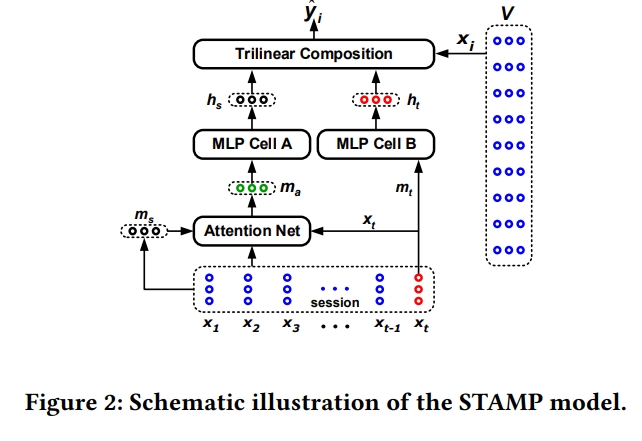
****
1) Query
- m(s)
2) Key, Value
- x(1)~x(t)
→ Key 하나하나에 대해서 가중치가 계산이 되고,
이 가중치를 통해 다시 한 번 x(1)~x(t)를 aggregation하여 m(a)가 표현됨
3) 계산 과정
- m(s)와 x(t)를 입력으로 하여 x(1)~x(t)를 aggregation하고자 함
4) m(a)
- 어떤 아이템을 더 중요하게 볼 것이냐를 m(s)d와 x(t) 관점에서 해석
- Key를 x(t)와 m(s) 두 가지로 사용
SRGNN
요약
- GNN을 도입한 부분이 달라진 부분
- 주어진 session sequence를 작은 그래프로 생각하고 , GNN을 통해 각각의 아이템에 대한 벡터를 얻고자 함
- SRGNN 전: 임베딩 벡터를 심플하게 임베딩 레이어를 하나 통과시켜 랜덤으로 초기화하여 학습
- SRGNN: GNN을 통해서 아이템 하나하나에 대한 임베딩 벡터를 의미있게 표현하고자 함
GNN의 장점
- 주변 아이템 뿐 아니라 이후 아이템도 고려할 수 있음
- A → B → A → C → D
- A 관점에서 보았을 때, 인접한 아이템이 C와 B만 있는 걸로 보이지만 second order 까지 보면 D와 A와도 관련성이 있음
- 이러한 정보까지 고려하기 때문에 GNN을 통해 아이템 임베딩을 표현하는 것이 효과적임
- 세션 길이가 길면 길수록 유의미한 임베딩 벡터를 얻어낼 수 있는 장점이 있음
SRGNN 모델 구조
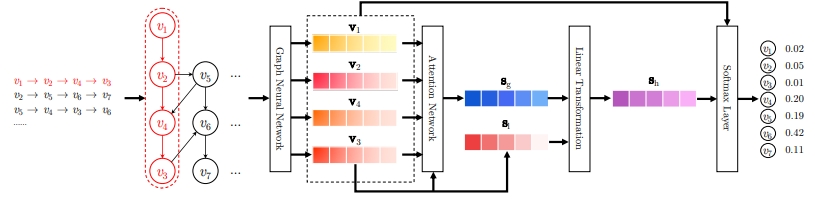
GNN 적용 파트
- 아이템 임베딩 벡터가 GNN 입력으로 들어가서 그들 간의 interaction을 잘 고려해서 다시 한 번 아이템 하나하나에 대한 임베딩 벡터가 아웃풋으로 나옴
- GNN 레이어를 통과시켜서 sequence 안의 아이템들에 대한 아이템 벡터를 얻는 것이고, 주어진 아이템의 sequence가 그래프로 표현됨
-
s(g): attention을 통해서 이 sequence의 아이템들에 대해 가중치를 다르게 해서 알파를 계산해서 산출함, global interest를 표현하는 형태
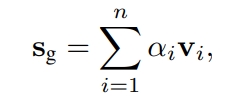
- s(1): sequence 아이템을 그대로 가지고 온 것, 또는 마지막 아이템을 그대로 가지고 온 것
- 이 s(g)와 s(1)을 concat한 후 W 벡터를 곱해서 s(h)라는 세션 벡터를 얻어냄
- Paper 상의 내용
- Previous session-based recommendation methods always assume there exists a distinct latent representation of user for each session.
- On the contrary, the proposed SR-GNN method does not make any assumptions on that vector.
- Instead, a session is represented directly by nodes involved in that session.
- To better predict the users’ next clicks, we plan to develop a strategy to combine long-term preference and current interests of the session, and use this combined embedding as the session embedding.
- After feeding all session graphs into the gated graph neural networks, we obtain the vectors of all nodes.
- Then, to represent each session as an embedding vector $S$ s ∈ R d(작성필요) , we first consider the local embedding sl of session s. For session s = [vs,1, vs,2, . . . , vs,n], the local embedding can be simply defined as vn of the last-clicked item vs,n, i.e. sl = vn.
- Then, we consider the global embedding s(g) of the session graph Gs by aggregating all node vectors.
-
Consider information in these embedding may have different levels of priority, we further adopt the soft-attention mechanism to better represent the global session preference:
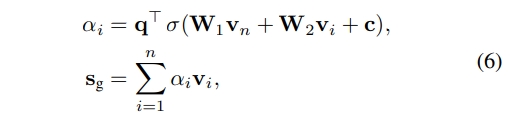
- where parameters q ∈ R d and W1,W2 ∈ R d×d
- control the weights of item embedding vectors.
아이템 벡터 얻은 후 과정
-
Finally, we compute the hybrid embedding sh by taking linear transformation over the concatenation of the local and global embedding vectors: sh = W3 [sl ; sg] , (7)
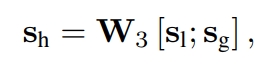
- matrix W3 ∈ R d×2d compresses two combined embedding vectors into the latent space
- 아이템에 대한 임벡딩 벡터를 얻고 나면 그 다음 과정은 STAMP와 비슷한 과정을 거침
- s(g)는 attention을 통해서 global interest를 표현하는 형태, s(1)는 마지막 아이템
- s(h): s(g)와 s(1)을 concat해서 W3을 곱해서 session representation을 벡터를 얻고 디코딩 과정 거침
- s(h): GNN과 2개의 글로벌, 로컬을 포함시켜서 만든 session 벡터
- 이 s(h) 세션 벡터를 통해 디코딩해서 최종적으로 맞추게 함
- 아이템에 대해 입력으로 들어가면 GNN을 통과해서 파랑색 벡터인 s(g)와 s(1)을 얻고 이 둘에 대해서 linear transfomation해서 s(h)를 얻고, 전체 아이템에 대해서 softmax를 통과해서 다음 item을 맞추게 됨
- STAMP의 경우, embedding lookup을 진행했는데 SRGNN은 embedding lookup을 하기 전에 GNN을 통과해서 벡터를 만들겠다는 것이 가장 큰 차이점임
-
작은 차이일 수 있으나, 상대적으로 sequence에서 생각하는 next item만을 고려하는 정보보다 풍부한 그래프 정보를 활용해서 item 임베딩이 될 수 있다는 장점이 있음
- https://arxiv.org/pdf/1811.00855.pdf
NISER
SRGNN의 한계
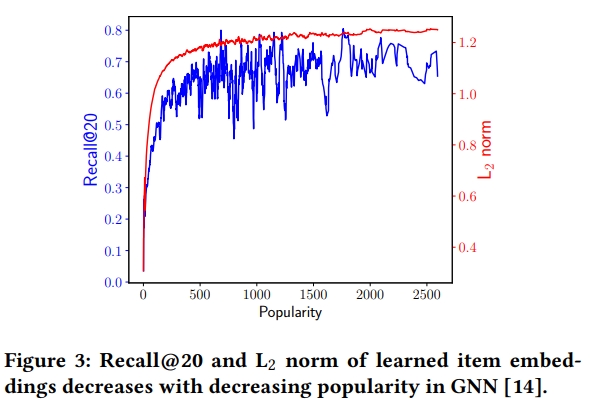
- SRGNN의 성능을 보았더니 추천된 항목들이 주로 인기있는 많이 추천됨
- SRGNN이 학습되는 과정에서 인기있는 아이템들이 L2 norm 벡터길이가 길어지는 식(내적했을 때 상대적으로 큰 값을 가질 수 있음)으로 표현이 되다보니 디코딩 할 때 그 스코어가 높게 나타나는 경향이 있음
- 추천에서는 normalization을 많이 하지 않았는데 하지 않았을 때 상대적으로 인기있는 애들이 벡터의 길이가 늘어나면서 히든 벡터의 크기가 커지게 됨
-
NISER라는 논문은 거기서 한발 더 나아가서 SRGNN을 학습할 때 중간 레벨에서 normalization을 도입함 → L2 norm 도입
- 아이템 하나하나가 임베딩 벡터를 통과한 후, GNN을 거쳐서 s(g)을 얻음
- s(g)는 가중치를 둬서 aggregation한 것
- NISER의 normalization 부분
1) s(h)(보라색) 를 normalize
2) 각각의 아이템 임베딩 v1~v4까지의 아이템들에 대한 임베딩이 있는 이 부분을 normalize함
⇒ 이를 통해, 인기있는 아이템 위주로 추천되는 걸 완화시키면서 성능이 높아짐
이 normalization 도입여부에 따라 성능 차이가 남
- SRGN보다 성능이 높음
NISER의 동작방식
- normalize : L2 벡터 길이가 1이 되게끔 진행
1. s(h) normalize
2. 각각의 v1~v4까지의 아이템에 대한 임베딩이 있는 부분을 normalize함
→ 인기있는 아이템이 주로 추천되는 걸 완화시키며, 성능이 높아짐
→ 해당 normalize를 도입여부에 따라 성능 차이가 큼
SGNN
- Star Graph Neural Networks for Session-based Recommendation
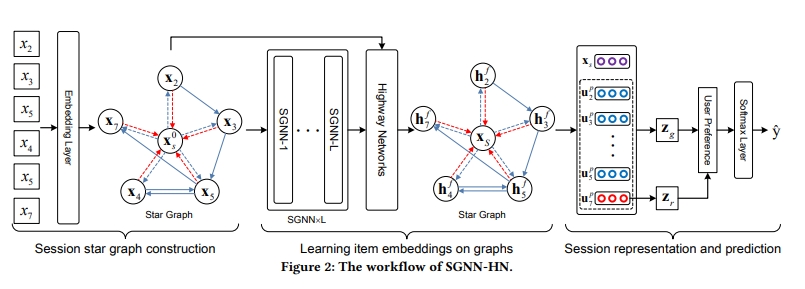
**
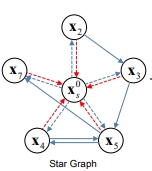
- start의 의미는 sequence data를 그래프로 표현할 수 있을텐데 x2, x3, x5, x4, x5, x7
- 이 외에 x0, 즉 임의의 가상의 아이템을 따로 둠
- 이 x0이 각 노드들과 연결되어있다고 봄
**<허구의 노드를="" 만드는="" 이유="">**
1) 세션 내 아이템이 멀리 떨어져있는 경우가 있는데 x2와 x7은 양극단에 있음
이 두 아이템은 GNN을 이용하면 서로 propagation 되는일이 별로 없음
아이템이 관련이 있다고 해도 멀리 있어서 둘 간의 관계가 효과적으로 표현되지 않을 수 있는데 x0라는 허구 노드를 둔다면 모든 노드들이 2홉 관계를 가지고 연결될 수 있음
실제로 어떤 노드들이 관련이 있다면 세션 시퀀스와 상관없이 멀리 위치하더라도 두 노드간의 correlation이 학습이 될 수 있는 것
2) x0가 모두 연결되어있기 때문에 x0가 session에 대한 representation으로 활용이 될 수 있음
**
- SGNN1~SGNN L은 GNN 레이어인데 이런 L개의 레이어가 쌓여져있는데 레이어가 깊어지면 이게 불필요하게 학습이 되면 오버 스무딩 문제가 발생할 수 있음 → 그런 걸 막기 위해서 일종의 residual connection처럼 highway net을 둔 것 = 점프할 수 있게끔 한 것
- 이러면 오버스무딩 및 오버피팅 문제를 일부 완화하면서 추가적인 가상 노드를 이용해서 세션을 효과적으로 표현하겠다고 봄
**<전체 구조="">**
- input graph가 star graph를 만드는 부분만 다른 부분이고
- GNN을 거치는 부분은 동일함
GCE-GNN
- Global Context Enhanced Graph Neural Networks for Session-based Recommendation
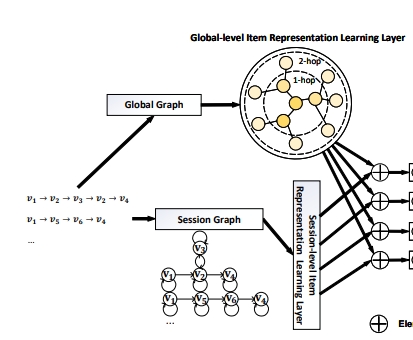
- 세션1: V1→V2→V3→V2→V4
- 세션2: V1→V5→V6→V4
- 세션에 대한 정보를 하나만 넣는게 아니라 세션(세션1,2)들에 대해서 그래프로 표현을 하면 큰 그래프인 seesion Graph를 생성할 수 있음
- 글로벌 그래프를 이용해서 좀 더 효과적으로 (세션은 짧고 희소하기 때문에) 전체 그래프를 이용해서 학습해보자는게 기본 아이디어임
- 대신 but train time이 상당히 길다고 함
- 현재 주어진 세션에서 만들어진 전체 그래프를 다 쓰진 않고 근처에 있는 1hop이나 2hop 정도 되는 노드들만 이용하려고 함
- 즉, 전체 그래프 중 서브 그래프만 사용하겠다는 의미임
- 그럼에도 학습시간 길다고 함
- 성능 개선에 일부도움이 되는건 맞는데 해보면 엄청 좋아지진 않음
References
NARM
https://arxiv.org/pdf/1711.04725.pdf
STAMP
https://dl.acm.org/doi/pdf/10.1145/3219819.3219950
SRGNN
https://arxiv.org/pdf/1811.00855.pdf
NISER
https://arxiv.org/pdf/1909.04276.pdf
SGNN
https://staff.fnwi.uva.nl/m.derijke/wp-content/papercite-data/pdf/pan-2020-star.pdf
Leave a comment