
concept
1. 강화학습의 개념
강화학습이란
- 매번 decision을 통해 action을 취하고 최적화하게 완수하여 score를 얻는 것
- 지속적인 시행착오가 가능한 환경인가? 현재 상태를 observation, action이 평가되고 상태가 변경됨, 처음엔 말도 안되는 의사결정을 하다가 반복하다가 사람보다 똑똑한 결정을 내리게 됨
- 데이터센터의 쿨링 시스템 에너지 절감(안 쓰는 장비의 경우 끄고 키고를 결정), 의족의 경우 사람마다 걸음걸이가 다른데 30분 걸으면 최적 걸음으로 맞춤형 로봇 의족, 스마트 팩토리의 공정 최적화 (운반-배송의 과정을 자동화)
머신러닝과 다른 점?
1) no supervisor, only a reward signal : 레이블을 주지 않고, 리워드 시그널이 있음
2) 리워드는 연기될 수도 있음 : 바둑의 경우 일련의 과정이 다 끝나고 피드백이 한번에 옴, 즉각적인 리워드는 greedy한 결과를 가져다주기도 함
3) time이 중요함 : sequential, non independent identically distributed data
4) agent의 action은 후속 데이터에 영향을
- agent는 자율 주행 카메라로 영상정보 즉 환경을 얻음 → 브레이크, 핸들, 시동 등의 action 중 하나라 선택해 수행함 → 환경에 영향을 줌 → 리워드가 발생함(즉각 또는 나중에 발생)
- agent: 행동을 하는 주체
- state: 환경, 상태 정보 (ex S0→S1로 변함)
- action: 행동
- reward: 환경에 따른 리워드
1.리워드

1) 리워드 R은 상수 피드백 시그널임
2) 리워드는 agent가 한 행동에 대해 해당 스텝에서 얼마나 잘했는지를 나타냄
3) agent의 job은 cumulative reward를 최대화하는 것임 , greedy가 아닌 cumulative reward, greedy를 다이나믹 프로그래밍으로 극복
[Sequential Decision Making: 순차적 의사결정]

1) 목표: total future reward를 maximize하는 action을 고르는 것
2) 액션은 long tern 결과를 가짐
3) 리워드는 아마도 delayed 될 것
4) 즉각적인 리워드는 희생하는 것이 long term reward를 얻기 위해서는 나음
Ex) 재무적인 투자, 드론의 연료 충전(다른 드론이 많을 경우 충돌 우려)
2. Environments
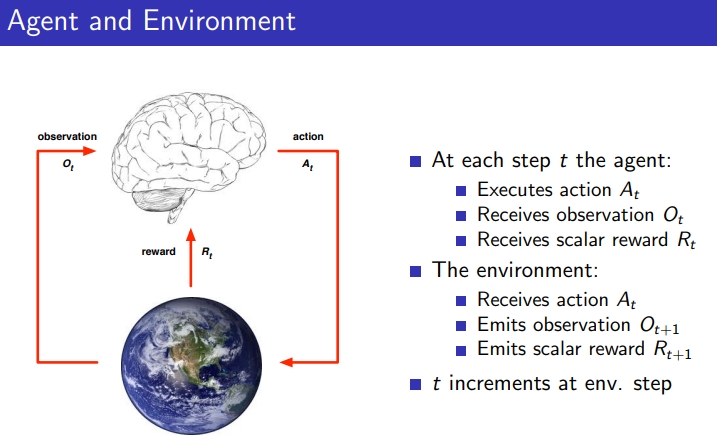
1) Step T의 Agent
- O(t) 관측치를 받음
- R(t) scalar 리워드를 받음
- A(t) 새로운 액션을 취함
2) Environment
- A(t) 액션을 받음
- O(t+1) 환경의 변화가 생김
- R(t+1) 새로운 리워드를 만들어냄
3. State
3-1. History & State

- 히스토리는 O,R,A,O,R,A, …. 의 과정
- State = f(H) : state는 히스토리의 함수
- State는 다음에 어떤 액션을 하기 위해 필요한 정보임
3-2. Environment State
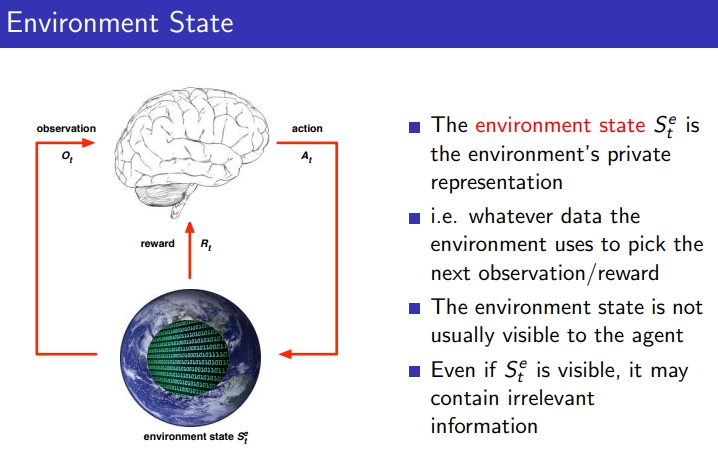
- Environment의 모든 정보가 모두 중요한게 아님, 통째로 모든 정보를 준다고 하더라도 관계 없는 정보를 포함하고 있는 경우가 있으므로, 선택적으로 사용해야 함, state를 어떻게 정의하느냐가 중요함
3-3. Agent State
3-4. Information State(Markov State)

- Markov State는 history로부터 유용한 모든 정보를 가지고 있음
- 최초의 State인 S(1)부터 → S(2) → …. → S(t-1)→S(t)→S(t+1) = S(t)의 state가 S(t+1)의 next state로 가는 상황
- 즉, S(1)→ S(2) → …. → S(t-1)→S(t)→S(t+1) = S(t) → state가 S(t+1)가 같은 경우를 Markov State라고 함
- 미래는 과거가 아닌 주어진 현재만 영향을 줌
- 현재의 상태를 안다면, 현재 상태로도 미래를 결정할만큼 충분하다고 보기 때문에 history는 사용하지 않음
- 이전에 경험한 State를 근간으로 미래에 어떤 행동할지에 대한 판단의 근거로 삼음
- ex) 아침 기상 후 가위바위보하기까지의 전체 과정 &가위바위보 직전 영향 요소
3-5. Fully observable Environments
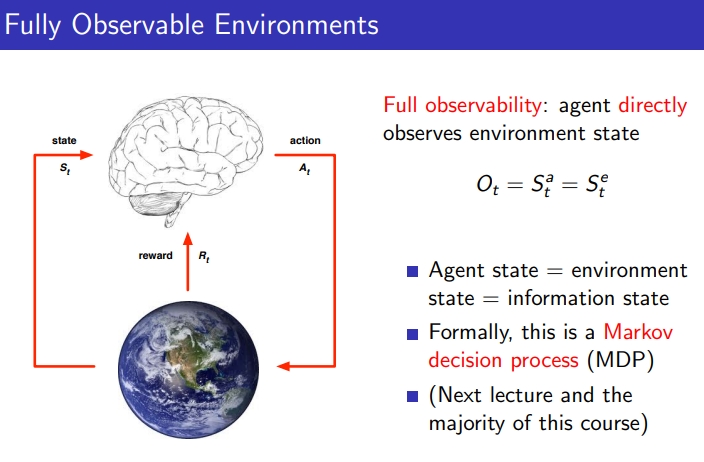
- Full observability : Agent가 environment state를 직접적으로 관측할 수 있음, last observation이 모든 정보를 가지고 있고, Agent가 그것을 활용해 Action 진행
- Environment state O(t) = Agent State S(a,t) = Markov State S(e,t)
- 이런 경우를 강화학습 개념(MDP)라고 부르며, 이는 굉장히 이상적인 것으로, 항상 optimal을 구해낼 수 있음
3-6. Partially Observable Environments
- Partial observability: agent가 environment의 일부만 관측 가능함
- ex) 트레이딩 agent가 현재 price만 관측 가능, pocker playing agent가 타인의 card는 알 수 없음
- Agent State는 이제 environment state와 같을 수 없고 이를 POMDP(Partial observable 강화학습 개념)라고 부름
- Agent는 own state representation을 구축해야 함
4. Inside An RL Agent
4-1. Major Components of an RL Agent

- RL agent는 아래 구성요소를 하나 이상은 가짐, 강화학습 알고리즘에 따라 초점 맞추는 구성요소가 달라짐
1) Policy: agent의 behavior function
2) Value Function: how good is each state(or state & action) → State의 값어치, 얼마나 좋은지
3) Model : agent’s representation of the environment → 현재의 environment를 어떻게 MDP로 표현할 수 있을 것인가
4-2. Policy

- Policy: behavior function
- state에서 action으로의 map, function을 의미하며, 2가지로 나뉨
1) Deterministic policy : 동일한 State면 항상 같은 action (게임 Atari)
2) Stochastic policy: 동일한 State더라도 일정 확률에 따라 Action 수행 (ex. a1: 70%, a2: 30% 또는 가위바위보)
4-3. Value Function

- Value function은 future cumulated rewards에 대한 prediction
- 주어진 State에 대해 리워드의 set ⇒ 무한번 반복하면 기댓값을 얻을 수 있음
- State를 평가하는데 사용될 수 있음
- 어떻게 Action 할지에 대해 decide 할 수 있음 ⇒ S(t)에서 S(t+1)로 Sa, Sb, Sc로 갈 수 있는데 각 state의 value를 알고 싶을 때 Value function을 비교해서 결정할 수 있음
4-4 Model

- 모델은 environment가 다음에 무엇을 할 것인지 예측
- P : next state를 예측
- R: next reward를 예측
[Maze Example]
미로게임
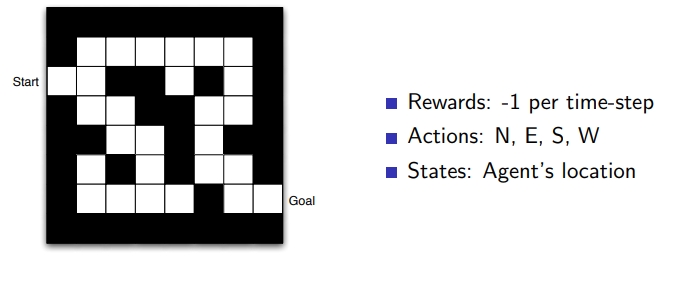
- States: Agent’s location x,y 좌표
- Actions : 위, 아래, 왼쪽, 오른쪽
- Rewards: step마다 -1 , 최단 거리
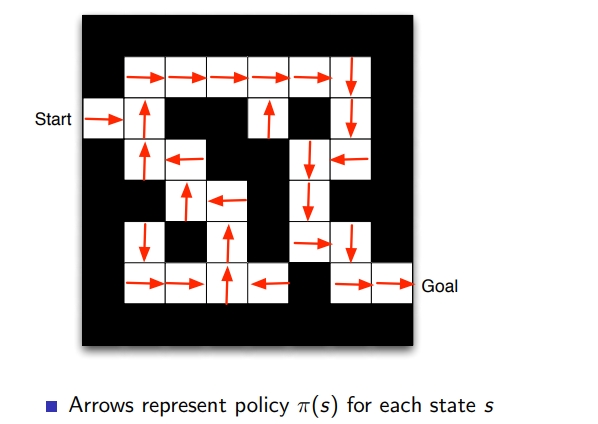
- policy: state에서 어떤 행동을 함, 화살표
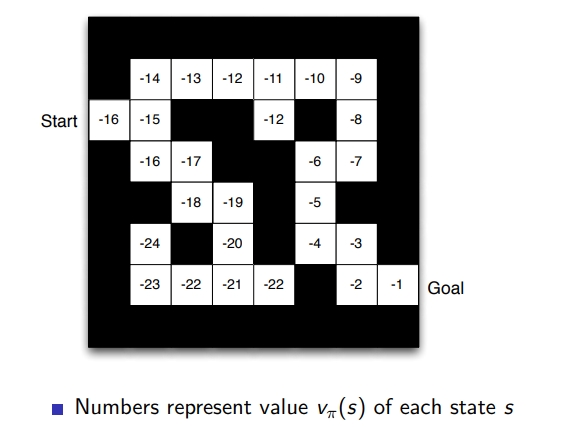
- Value function: 각 state의 value를 의미, 움직일 때마다 -1 패널티, value 값이 큰 애가 좋음, goal과 멀면 -가 커짐
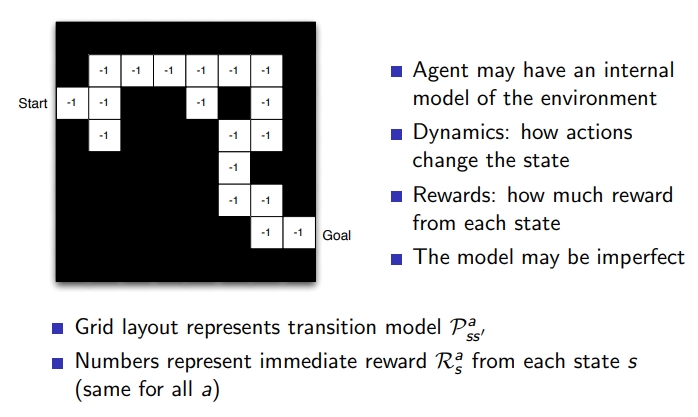
4-5. RL 카테고리


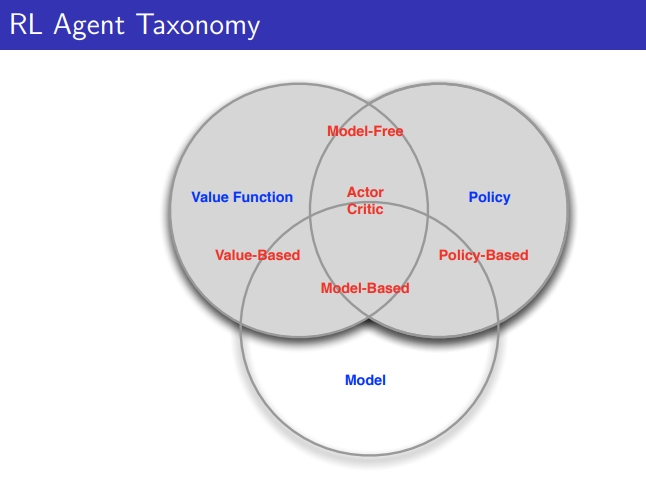 model-free RL : policy, value funtion = Q-learning
model-free RL : policy, value funtion = Q-learning
5. Learning & Planning

6. Exploration and Exploitation


- Exploitation: 지금까지 학습한 결과로 가장 좋은 액션을 택하는 것
- Exploration : 해보지 않은 것을 진행
- 둘의 밸런스가 필요함
7. Prediction and Control

- Prediction: 주어진 policy에 대해 이 policy가 미래에 얼마나 좋은지 평가
- Control: 현재 있는 policy를 improve 시켜 최적화하는 것
State : History, environment state, agent state, information state
References
CS234
UC Berkely CS294-112
UCL course on Reinforcement Learning
[Teaching - David Silver]
[Lecture 1: Introduction to Reinforcement Learning (davidsilver.uk)]
Leave a comment